
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- bigdata engineering
- java
- apache iceberg
- Trino
- HIVE
- 양평
- 맛집
- 프로그래머스
- Data Engineer
- 코딩테스트
- 코엑스
- BigData
- 백준
- bigdata engineer
- 여행
- Iceberg
- 코테
- 개발
- 삼성역맛집
- 용인맛집
- 알고리즘
- Data Engineering
- BFS
- 영어
- dfs
- 코엑스맛집
- 파이썬
- hadoop
- 코딩
- 자바
- Today
- Total
지구정복
[Iceberg] Iceberg Guide Book Summary | Chaper 1,2. The Architecture of Apache Iceberg 본문
[Iceberg] Iceberg Guide Book Summary | Chaper 1,2. The Architecture of Apache Iceberg
noohhee 2025. 3. 9. 21:07

A data warehouse acts as a centralized repository for organizations to store all their
data coming in from a multitude of sources, allowing data consumers such as analysts
and BI engineers to access data easily and quickly from one single source to start their analysis
The Data Lake
While data warehouses provided a mechanism for running analytics on structured
data, they still had several issues:
What Is Apache Iceberg?
Apache Iceberg is a table format
It arose from the need to overcome challenges with performance, consistency,
and many of the challenges previously stated with the Hive table format.
Key Features of Apache Iceberg
ACID transactions

Partition evolution
Too often, when your partitioning needs to change the only choice you have is to rewrite the entire table,
and at scale this can get very expensive.
With Apache Iceberg you can update how the table is partitioned at any time without
the need to rewrite the table and all its data. Since partitioning has everything to do
with the metadata, the operations needed to make this change to your table’s structure
are quick and cheap.
Hidden partitioning
Sometimes users don’t know how a table is physically partitioned, and frankly, they
shouldn’t have to care.
Row-level table operations
copy-on-write (COW) or merge-on-read (MOR)
When using COW, for a change of any row in a given datafile, the entire file is rewritten
When using MOR, for any row-level updates, only a new file that contains the changes to the affected row
that is reconciled on reads is written.
Time travel
Apache Iceberg provides immutable snapshots, so the information for the table’s
historical state is accessible, allowing you to run queries on the state of the table at a
given point in time in the past, or what’s commonly known as time travel.
Version rollback
it also reverts the table’s current state to any of those previous snapshots. Therefore,
undoing mistakes is as easy as rolling back
Schema evolution
Regardless of how your table needs to evolve,
Apache Iceberg gives you robust schema evolution features—for example, updating
an int column to a long column as values in the column get larger.
CHAPTER 2
The Architecture of Apache Iceberg
The Apache Iceberg Architecture
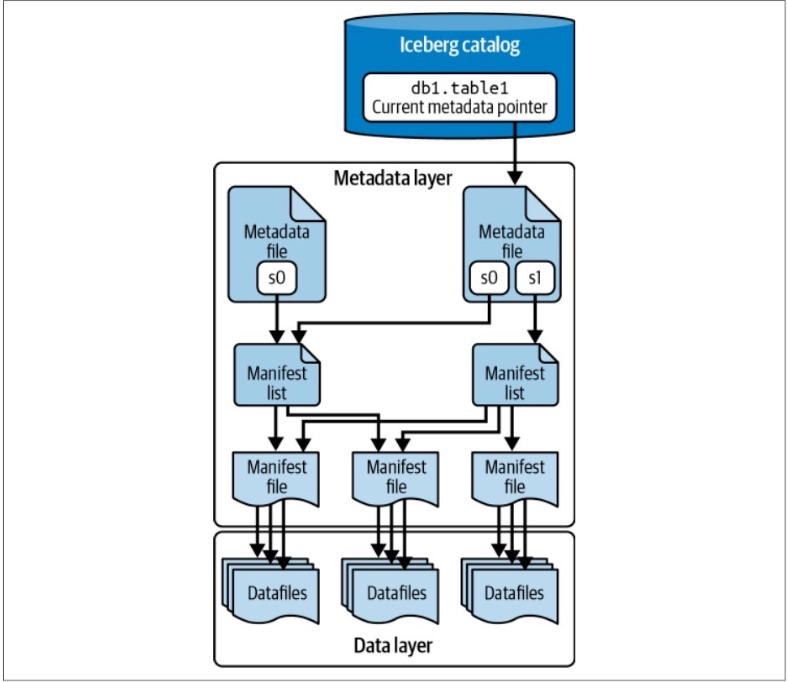
The Data Layer
what stores the actual data of the table.
Datafiles
Datafiles store the data itself.
Apache Parquet, Apache ORC, and Apache Avro
in the real world the file format most commonly used is Apache Parquet.
Delete Files
Delete files track which records in the dataset have been deleted.
Since it’s a best practice to treat data lake storage as immutable, you can’t update rows in a file in place.
Instead, you need to write a new file.
it can be a new file that only has the changes written, which engines reading the data then coalesce
That is, delete files only apply to MOR tables
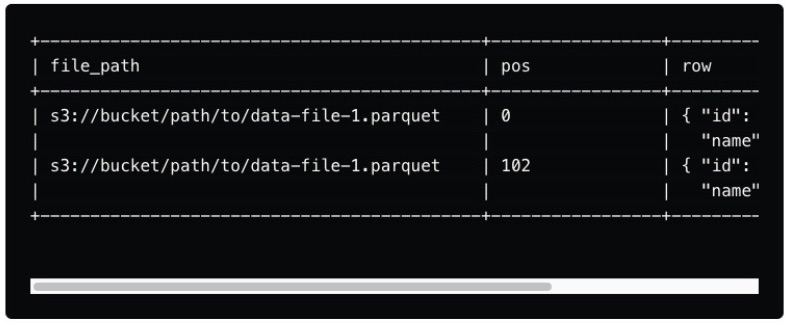
Positional delete files
These delete files specify the exact position of rows within a data file that should be considered deleted. They are used when the physical location of the data (i.e., the row's position in the file) is known.
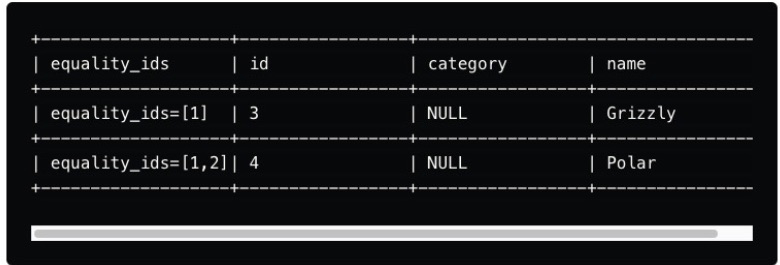
Equality delete files
These delete files mark rows for deletion based on specific column values rather than their position. For example, suppose a record with a particular ID needs to be deleted. In that case, an equality delete file can specify that any row matching this ID should be excluded from query results.
Key Fields in a Delete File
Here are some of the critical fields you’ll find inside a delete file:
- file_path: This field indicates the path of the data file to which the delete file applies. It’s essential for mapping the delete operations to the correct data file in the dataset.
- pos: Present in position delete files, this field specifies the exact position of the row within the data file that should be marked as deleted. This allows for precise, row-level deletions based on the physical layout of the data.
- row: In equality delete files, the row field contains the values that identify which rows should be deleted. For instance, if a particular ID needs to be deleted across multiple data files, this field will hold that ID value.
- partition: This field contains the partition information of the data that is subject to deletion. It helps ensure that the delete file is applied only to the relevant partitions, further optimizing the deletion process.
- sequence_number: Iceberg uses sequence numbers to track the order of changes made to the data. The sequence_number in a delete file indicates when the deletion was committed relative to other changes in the dataset.
The Metadata Layer
The metadata layer is an integral part of an Iceberg table’s architecture and contains
all the metadata files for an Iceberg table.
Manifest Files
Manifest files keep track of files in the data layer (i.e., datafiles and delete files) as
well as additional details and statistics about each file, such as the minimum and
maximum values for a datafile’s columns.
Manifest Lists
A manifest list is a snapshot of an Iceberg table at a given point in time.
A manifest list contains an array of structs, with each struct keeping track of a single
manifest file.
Metadata Files
Manifest lists are tracked by metadata files.
Puffin Files
A puffin file stores statistics and indexes about the data in
the table that improve the performance of an even broader range of queries, such as
the aforementioned example, than the statistics stored in the datafiles and metadata
files.
The Catalog
This central place where you go to find the current location of the current metadata
pointer is the Iceberg catalog.
The primary requirement for an Iceberg catalog is that
it must support atomic operations for updating the current metadata pointer. This
support for atomic operations is required so that all readers and writers see the same
state of the table at a given point in time.
Within the catalog, there is a reference or pointer for each table to that table’s current
metadata file.



