
- 지구정복과정 (515)

- 데이터 엔지니어링 정복 (413)
- Elastic Stack (2)
- Hadoop Ecosystem (27)
- HTML-CSS-JavaScript-Spring-.. (43)
- JAVA & JSP (46)
- Python (27)
- SQL (14)
- Cloud(AWS, Ncloud) (8)
- Docker&Kubernetes (2)
- Linux (11)
- Git-GitHub (9)
- Algorithm (159)
- HDFS (4)
- Iceberg (6)
- Hive (5)
- Hue (1)
- Yarn (1)
- Spark (8)
- MapReduce (2)
- Airflow (2)
- Sqoop (2)
- Tez (0)
- Trino (2)
- Kafka (12)
- Zookeeper (2)
- Flume (2)
- Oozie (1)
- Hbase (3)
- Ranger (1)
- OpenSearch (1)
- Ansible & AWX (2)
- AD & LDAP (0)
- NiFi (3)
- 데이터 애널리틱스 정복 (3)
- 프로젝트 (5)
- 자격증 정복 (33)
- 영어 정복 (7)
- 건강 정복 (5)
- 주식 정복 (가능 ?) (0)
- 이것저것 (38)
- 데이터 엔지니어링 정복 (413)
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- hadoop
- 여행
- 알고리즘
- 코엑스맛집
- 자바
- 삼성역맛집
- bigdata engineering
- apache iceberg
- HIVE
- 코딩
- 영어
- bigdata engineer
- Spark
- Data Engineer
- Data Engineering
- Apache Kafka
- Kafka
- java
- Trino
- 용인맛집
- BigData
- 백준
- Iceberg
- 개발
- 코테
- 맛집
- pyspark
- 프로그래머스
- 코딩테스트
- 코엑스
- Today
- Total
지구정복
[Iceberg] Iceberg Guide Book Summary | CHAPTER 3. Lifecycle of Write and Read Queries 본문
[Iceberg] Iceberg Guide Book Summary | CHAPTER 3. Lifecycle of Write and Read Queries
noohhee 2025. 3. 4. 21:03
apache iceberg guidebook에서 가져온 내용입니다.
CHAPTER 3
Lifecycle of Write and Read Queries

Writing Queries in Apache Iceberg

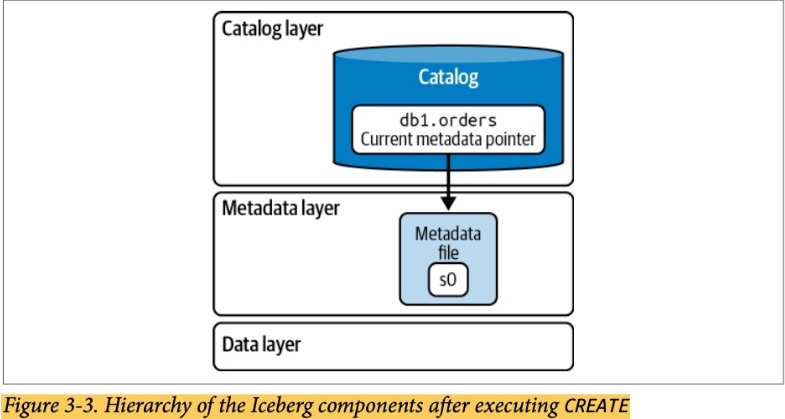
Create the Table
Send the query to the engine
Write the metadata file
Update the catalog file to commit changes
Insert the Query
Send the query to the engine
Check the catalog
Write the datafiles and metadata files
Update the catalog file to commit changes
Merge Query
Send the query to the engine
Check the catalog
Write datafiles and metadata files
Update the catalog file to commit changes
Reading Queries in Apache Iceberg
The SELECT Query
Send the query to the engine
Check the catalog
Get information from the metadata file
Get information from the manifest list
Get information from the manifest file
The Time-travel Query
Apache Iceberg provides
two ways to run time-travel queries: using a timestamp and using a snapshot ID
To analyze our order table’s history, we will query the history metadata table
# Spark SQL
SELECT * FROM catalog.db.orders.history;
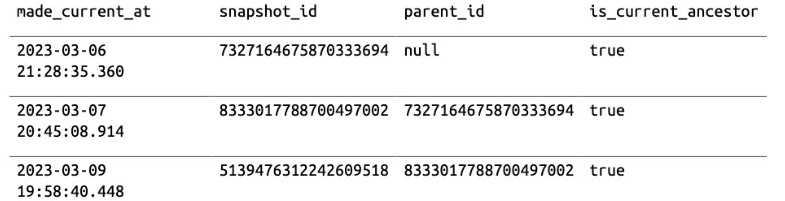
the timestamp or the snapshot ID we will be targeting is the second one. This
is the query that we will run:
# Spark SQL
SELECT * FROM orders
TIMESTAMP AS OF '2023-03-07 20:45:08.914'
Send the query to the engine
Check the catalog
Get information from the metadata file
Get information from the manifest list
Get information from the manifest file



