
- 지구정복과정 (516)

- 데이터 엔지니어링 정복 (414)
- Elastic Stack (2)
- Hadoop Ecosystem (27)
- HTML-CSS-JavaScript-Spring-.. (43)
- JAVA & JSP (46)
- Python (27)
- SQL (14)
- Cloud(AWS, Ncloud) (8)
- Docker&Kubernetes (2)
- Linux (11)
- Git-GitHub (9)
- Algorithm (159)
- HDFS (4)
- Iceberg (6)
- Hive (5)
- Hue (1)
- Yarn (1)
- Spark (8)
- MapReduce (2)
- Airflow (2)
- Sqoop (2)
- Tez (0)
- Trino (2)
- Kafka (12)
- Zookeeper (2)
- Flume (2)
- Oozie (1)
- Hbase (3)
- Ranger (1)
- OpenSearch (1)
- Ansible & AWX (2)
- AD & LDAP (0)
- NiFi (3)
- Ambari (1)
- 데이터 애널리틱스 정복 (3)
- 프로젝트 (5)
- 자격증 정복 (33)
- 영어 정복 (7)
- 건강 정복 (5)
- 주식 정복 (가능 ?) (0)
- 이것저것 (38)
- 데이터 엔지니어링 정복 (414)
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 알고리즘
- java
- 코딩테스트
- hadoop
- 맛집
- apache iceberg
- pyspark
- Kafka
- 백준
- 여행
- BigData
- Spark
- 코딩
- 삼성역맛집
- 코엑스
- 코엑스맛집
- 자바
- 용인맛집
- 영어
- 프로그래머스
- 코테
- bigdata engineering
- 개발
- HIVE
- Data Engineering
- Trino
- Data Engineer
- bigdata engineer
- Apache Kafka
- Iceberg
- Today
- Total
지구정복
[Iceberg] 기본 내용 정리 | Basic concepts using Trino 본문
참고
icberg guidebook
https://trino.io/docs/current/connector/iceberg.html#metadata-tables
Trino 402버전 문서: https://trino.io/docs/402/overview/use-cases.html
0. PE/DE로서 Iceberg 사용시 어떤 점들을 중점적으로 알아야 할까?
-Trino/Spark3 설치법
-Iceberg 셋팅법(Trino와 Spark3에서 사용가능하도록 셋팅하기)
-Ranger 권한관리방법
(현재는 Trino만 유저에 한해서만 작동하지만 LDAP연동시에는 그룹 권한은 미작동 / Spark3도 되지만 권한적용이 원활히 되진 않음 / 그룹 및 유저권한관리)
-Iceberg의 기본 개념 및 사용방법
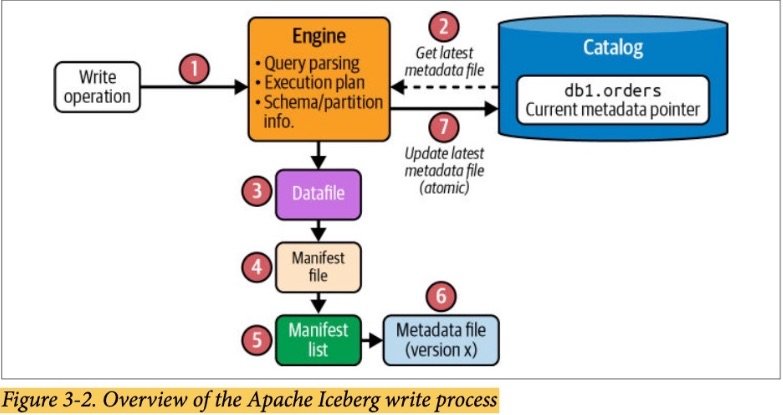
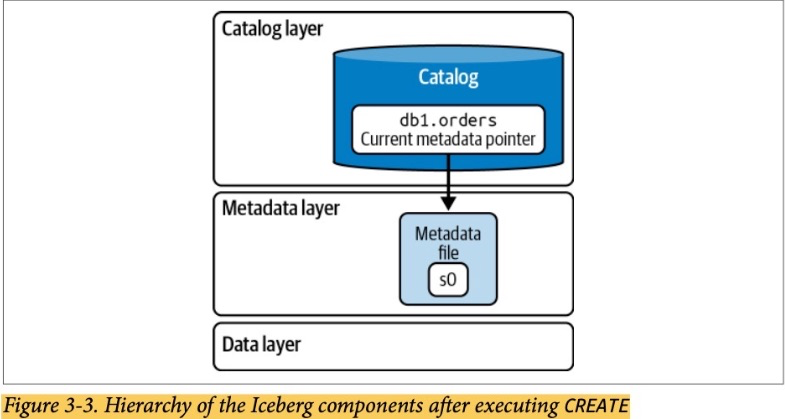
1. Iceberg Architecture
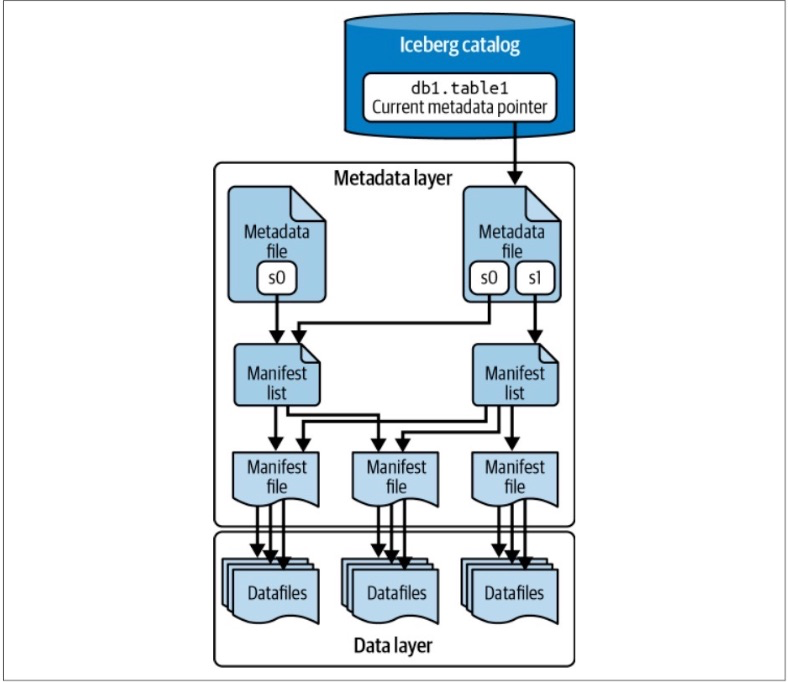
1.1. Catalog
This central place where you go to find the current location of the current metadata pointer is the Iceberg catalog.
The primary requirement for an Iceberg catalog is that it must support atomic operations for updating the current metadata pointer.
This support for atomic operations is required so that all readers and writers see the same state of the table at a given point in time.
=Iceberg를 사용을 위해 어떤 데이터 소스를 쓸 것 인가 (해당 데이터 소스는 원자성을 보장해야한다.)
the Hadoop Distributed File System (HDFS),
Amazon Simple Storage Service (Amazon S3),
Azure Data Lake Storage (ADLS),
Google Cloud Storage (GCS),
Hive Metastore
AWS Glue
Nessie
1.2. Datafiles
Datafiles store the data itself.
Apache Parquet, Apache ORC, and Apache Avro
=실제 데이터가 저장되어 있는 파일
1.2.1. Delete Files
Delete files track which records in the dataset have been deleted.
Delete files only apply to MOR tables.
데이터 파일을 다시 쓰는것보다 delete file에 수정되거나 삭제된 데이터 적어놓고 참조하게 하는게 더 나은 경우 사용
MOR이 적용된 테이블에만 사용된다.
1.2.2. Puffin Files
This is a specification for Puffin, a file format designed to store information such as indexes and statistics about data managed in an Iceberg table that cannot be stored directly within the Iceberg manifest.
=> Iceberg 테이블 성능을 높이기 위해 추가적인 각종 통계 및 인덱스 정보를 가지고 있는 파일포맷
그러나 여러 시스템에서 범용적으로 쓰려면 Parquet 포맷이 좋다.
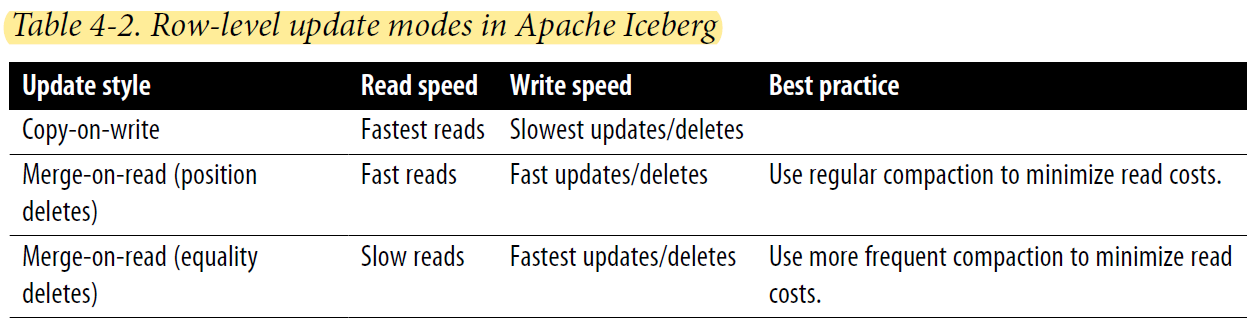
1.2.3. Copy-on-Write(COW) Versus Merge-on-Read(MOR)
결론부터 말하면
Trino Engine은 COW만 가능
Spark Engine은 COW, MOR 둘 다 가능
Trino는 MOR적용된 테이블 읽을 순 있지만 write는 안됨
when you want to update preexisting rows to either update or delete them, there are some considerations you need to be aware of:
COW, MOR
Copy-on-Write
The default approach is referred to as copy-on-write (COW).
In this approach, if even a single row in a datafile is updated or deleted, that datafile is rewritten and the new file takes its place in the new snapshot.
update or delete 쿼리시 전체 파일이 다시 쓰여진다.

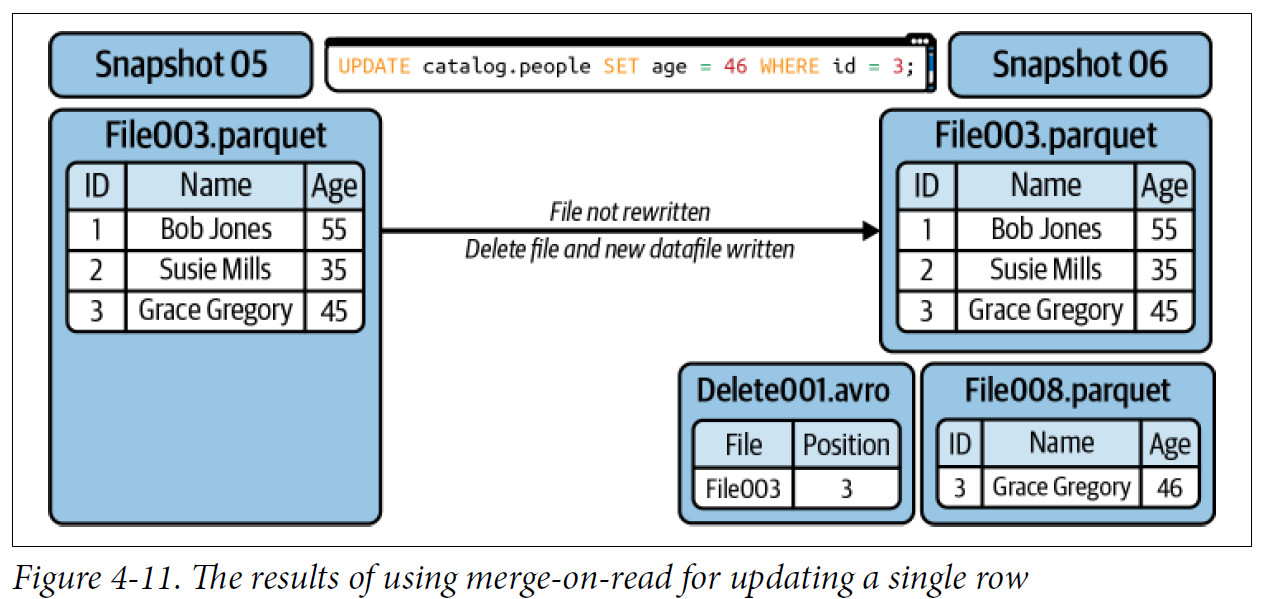
Merge-on-Read
If you are updating a record:
• The record to be updated is tracked in a delete file.
• A new datafile is created with only the updated record.
• When a reader reads the table it will ignore the old version of the record because of the delete file and use the new version in the new datafile.
update or delete쿼리 실행시 전체 파일이 다시 쓰여지는게 아니라
영향을 받은 row만 delete 파일에 표시되고, 새로운 row의 데이터는 새로운 parquet파일에 생성된다.
나중에 조회시
기존 전체 파일 읽고 -> delete file 조회하여 내용 조회하여 최종 출력한다.
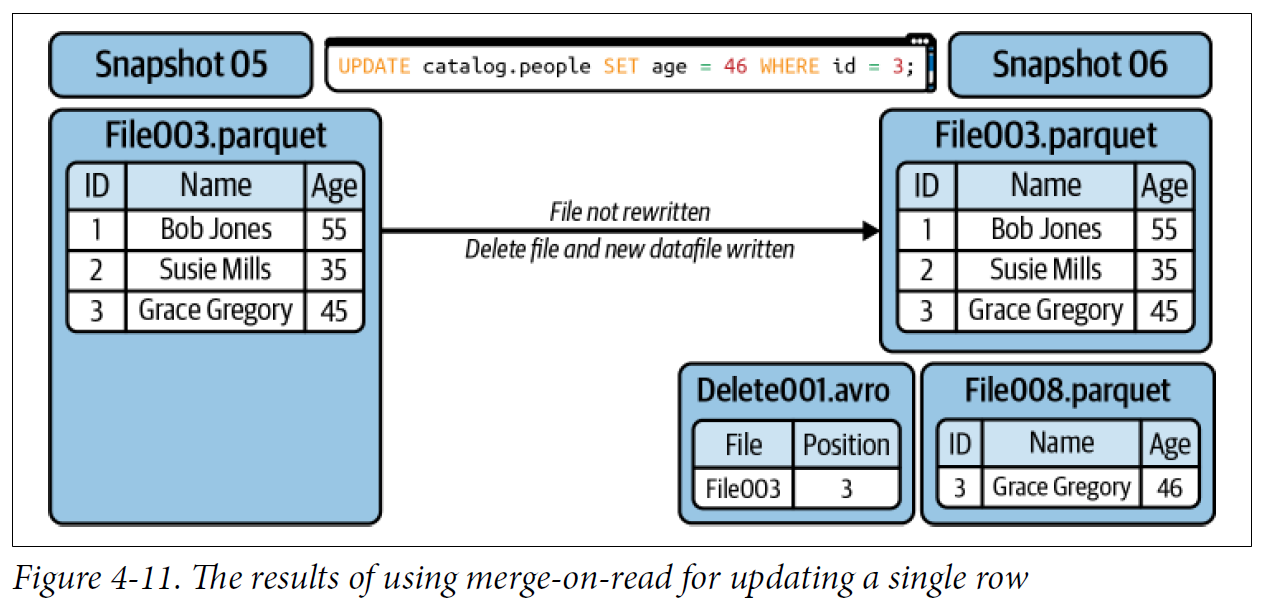
To minimize the cost of reads, you’ll want to run regular compaction jobs, and to keep those compaction jobs running efficiently
여러 개의 parquet파일을 읽으면 비용이 많이 드니 compaction 작업을 통해 datafile을 묶어주면 더 성능이 좋아진다.
delete file에는 두 가지 종류가 존재한다.
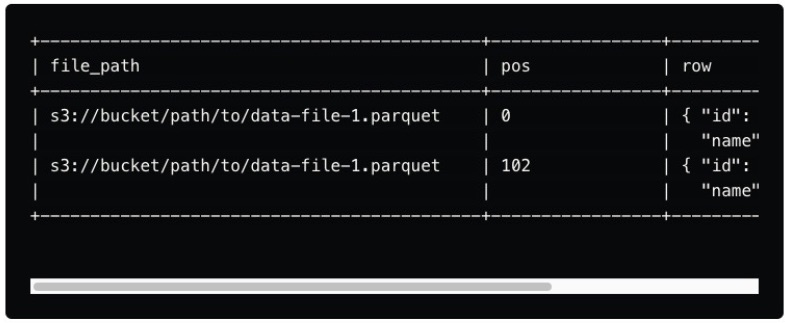
Positional delete files
These delete files specify the exact position of rows within a data file that should be considered deleted.
They are used when the physical location of the data (i.e., the row's position in the file) is known.
Delete 파일에 update 혹은 delete된 row 번호가 적혀있다.
조회할 때 먼저 전체 parquet파일 읽은 뒤 delete 파일 조회해서 여기에 적힌 데이터를 빼거나
update된 경우라면 새로운 parquet파일에서 추가로 조회한다.
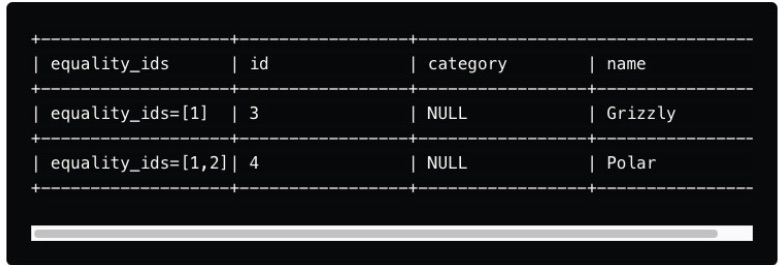
Equality delete files
These delete files mark rows for deletion based on specific column values rather than their position.
For example, suppose a record with a particular ID needs to be deleted.
In that case, an equality delete file can specify that any row matching this ID should be excluded from query results.
delete file에 update or delete쿼리로부터 영향받은 row의 특정 조건이 쓰여있다.
따라서 나중에 select조회시 delete file로부터 이 조건에 맞는 컬럼을 빼거나 수정된 값으로 바꿔서 출력해준다.

--Create시 옵션으로 설정하기
CREATE TABLE catalog.people (
id int,
first_name string,
last_name string
) TBLPROPERTIES (
'write.delete.mode'='copy-on-write',
'write.update.mode'='merge-on-read',
'write.merge.mode'='merge-on-read'
) USING iceberg;
--테이블 생성후 alter쿼리로 설정하기
ALTER TABLE catalog.people SET TBLPROPERTIES (
'write.delete.mode'='merge-on-read',
'write.update.mode'='copy-on-write',
'write.merge.mode'='copy-on-write'
);
퀴즈)
Iceberg에서 Catalog는 데이터베이스와 동일하다. (O / X)
Iceberg의 Catalog로 HDFS를 사용할 수 있다. (O / X)
Trino엔진 사용시 MOR을 사용할 수 있다. (O / X)
COW방식을 사용하면 update/delete될 시 delete file을 생성된다. (O / X)
Equality delete file은 특정 조건을 만족하는 방식으로 처리한다. (O / X)
사용자가 Positional delete file과 Equality delete file 둘 중에 하나를 선택할 수 있다. (O / X)
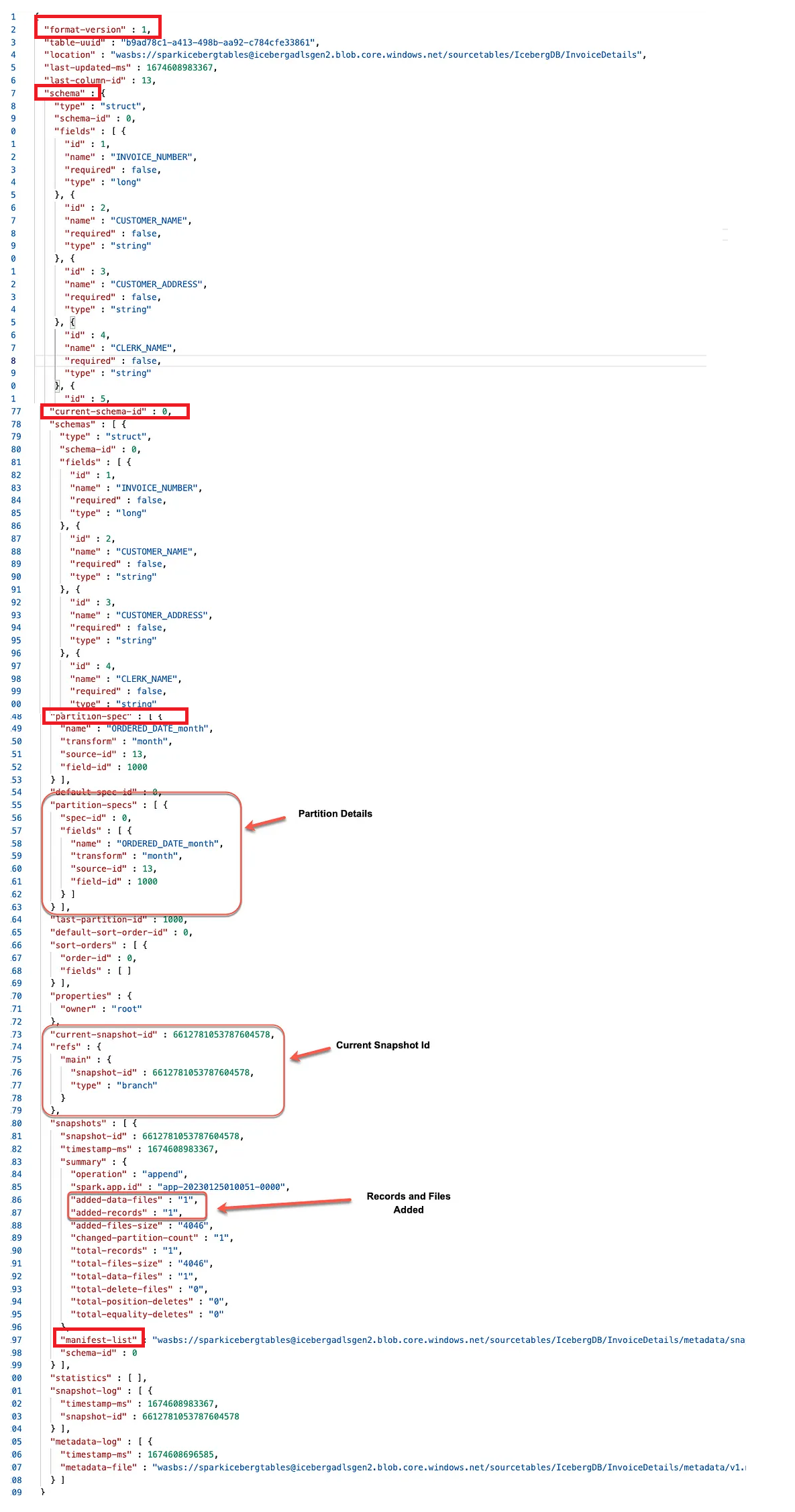
1.3. The Metadata Layer
The metadata layer is an integral part of an Iceberg table’s architecture and contains
all the metadata files for an Iceberg table.
1.3.1. Manifest Files
Manifest files keep track of files in the data layer (i.e., datafiles and delete files) as well as additional details and statistics about each file, such as the minimum and maximum values for a datafile’s columns.
=data layer에 있는 data files와 delete files를 기록하고 추가로 해당 데이터 컬럼의 최소/최대값도 기록해놓는다.

1.3.2. Manifest Lists
A manifest list is a snapshot of an Iceberg table at a given point in time.
A manifest list contains an array of structs, with each struct keeping track of a single manifest file.
=> 매니페스트 리스트 파일은 특정 시점의 아이스버그 테이블이 어떤 매니페스트 파일들을 포함하고 있는지 기록하는 파일
이 파일은 메타데이터 파일한테 특정 시점의 스냅샷에 어떤 매니페스트 파일들이 관여하고 있는지 알려준다.
{
"manifest-list": [
{
"manifest_path": "s3://bucket/path/to/manifest1.avro",
"manifest_length": 1048576,
"partition_spec_id": 1,
"content": 0,
"sequence_number": 1001,
"min_sequence_number": 1000,
"added_files_count": 5,
"existing_files_count": 10,
"deleted_files_count": 2,
"added_rows_count": 500000,
"existing_rows_count": 1000000,
"deleted_rows_count": 200000,
"partitions": [
{
"contains_null": false,
"contains_nan": false,
"lower_bound": "2023-01-01",
"upper_bound": "2023-01-31"
}
]
},
{
"manifest_path": "s3://bucket/path/to/manifest2.avro",
"manifest_length": 2097152,
"partition_spec_id": 2,
"content": 0,
"sequence_number": 1002,
"min_sequence_number": 1001,
"added_files_count": 8,
"existing_files_count": 7,
"deleted_files_count": 3,
"added_rows_count": 750000,
"existing_rows_count": 700000,
"deleted_rows_count": 150000,
"partitions": [
{
"contains_null": true,
"contains_nan": false,
"lower_bound": "2023-02-01",
"upper_bound": "2023-02-28"
}
]
}
]
}
1.3.3. Metadata Files
Manifest lists are tracked by metadata files.
The metadata file stores information about a table schema, partition information, and the snapshot details for the table.
=> Iceberg 테이블의 정보(스키마, 파티션 정보, 스냅샷정보-매니페스트 리스트파일)들을 가지고 있음
2. Hands-On Session
2.1. Create & Insert Query
Iceberg Table을 Create했을 시 어떤 일이 일어날까?
Trino엔진 사용시 Iceberg의 데이터타입과 매핑되는지 확인하고 사용한다.
https://trino.io/docs/current/connector/iceberg.html#trino-to-iceberg-type-mapping
CREATE TABLE iceberg.db1_test.jh (
id INT,
name VARCHAR,
created_at TIMESTAMP(6)
)
WITH (
format = 'PARQUET',
partitioning = ARRAY['name'],
);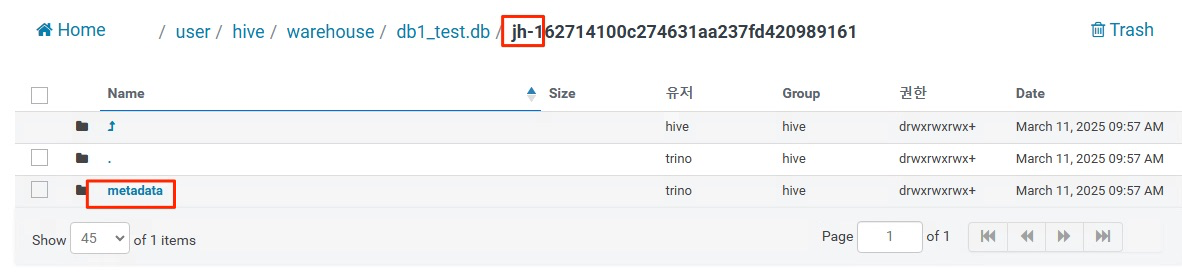
아직 메타데이터 파일과 스냅샷 파일만 존재
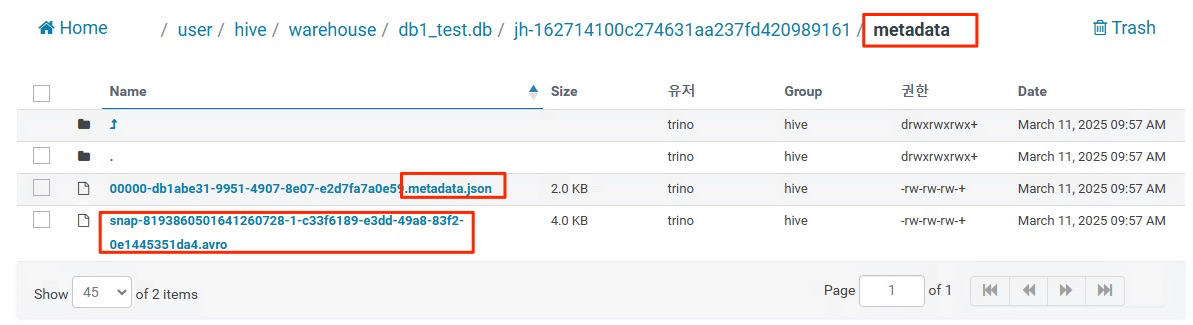
참고
-USING iceberg 문구는 Trino에서 쓰이지 않는다.(Hive, Spark에서 사용됨)
-Catalog명을 사용하지 않으면 기본 카탈로그인 hive 카탈로그를 사용하게된다.
(이와 같이 사용해야 한다. catalog_name.db_name.table_name)
이제 Insert쿼리로 데이터를 추가해본다.
INSERT INTO iceberg.db1_test.jh (id, name, created_at)
VALUES
(1, 'Alice', TIMESTAMP '2025-03-10 10:00:00'),
(2, 'Bob', TIMESTAMP '2025-03-10 11:30:00'),
(3, 'Charlie', TIMESTAMP '2025-03-10 12:45:00');
아래와 같이 data 디렉터리가 생겼다.
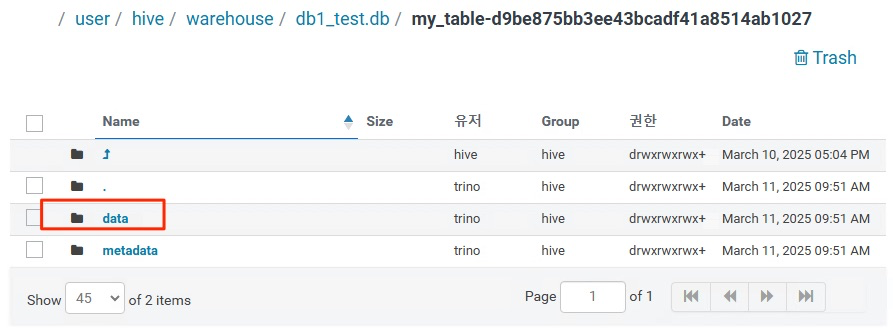
파티션컬럼이 name이므로 파티션 디렉터리가 있다.
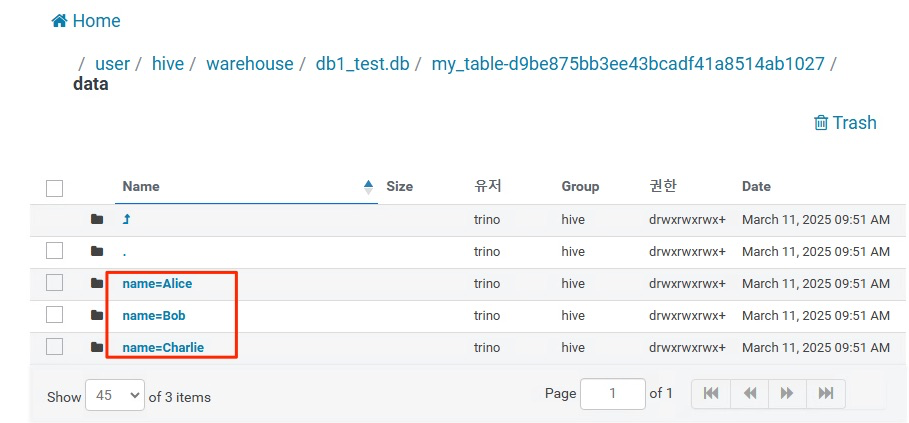
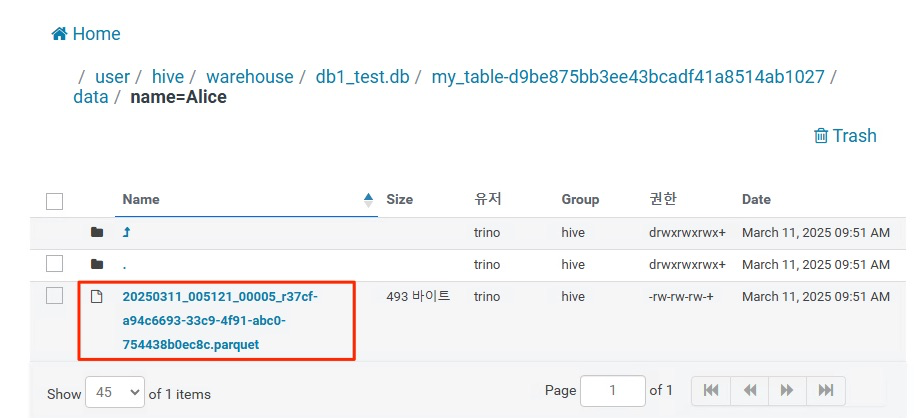
안에 들어가보면 데이터 파일이 있다.
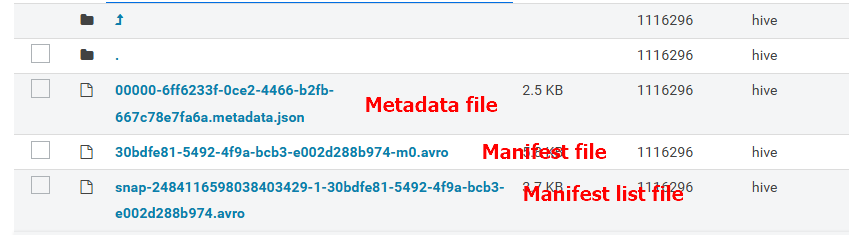
The connector exposes several metadata tables for each Iceberg table.
These metadata tables contain information about the internal structure of the Iceberg table.
You can query each metadata table by appending the metadata table name to the table name:
이제 메타데이터 테이블( 메타데이터 파일 아님 )에 쿼리도 실행할 수 있다.
위와 같은 특정 테이블의 메타정보들(스냅샷정보, 매니페스트 파일 정보, 등등)을 일일이 HDFS에 들어가서 확인하기 어려우니 쿼리를 이용해서 확인할 수 있다.
manifest = manifest file
new sanpshot = manifest list file
테이블의 적용된 설정값 확인
SELECT * FROM iceberg.db1_test."jh$properties"꼭 위에처럼 써줘야지 메타데이터 테이블에 쿼리가 가능하다.

SELECT * FROM iceberg.db1_test."jh$history";
스냅샷 정확한 정보 확인
SELECT * FROM iceberg.db1_test."jh$snapshots";

여러가지 존재
SELECT * FROM "test_table$manifests"; --매니페스트파일관련
SELECT * FROM "test_table$partitions"; --파티션관련
SELECT * FROM "test_table$files"; --데이터 파일 관련공식문서 참고
Insert 쿼리를 여러번 진행해본다.
INSERT INTO iceberg.db1_test.jh (id, name, created_at) VALUES (4, 'Ji', TIMESTAMP '2025-03-10 11:00:00');
INSERT INTO iceberg.db1_test.jh (id, name, created_at) VALUES (5, 'Min', TIMESTAMP '2025-03-10 11:00:01');
INSERT INTO iceberg.db1_test.jh (id, name, created_at) VALUES (6, 'Sun', TIMESTAMP '2025-03-10 11:00:02');
INSERT INTO iceberg.db1_test.jh (id, name, created_at) VALUES (7, 'Dong', TIMESTAMP '2025-03-10 11:00:03');
INSERT INTO iceberg.db1_test.jh (id, name, created_at) VALUES (8, 'Hak', TIMESTAMP '2025-03-10 11:00:04');
INSERT INTO iceberg.db1_test.jh (id, name, created_at) VALUES (9, 'Tae', TIMESTAMP '2025-03-10 11:00:05');
INSERT INTO iceberg.db1_test.jh (id, name, created_at) VALUES (10, 'byeong', TIMESTAMP '2025-03-10 11:00:06');
그리고 hdfs 확인해본다.
| # hdfs dfs -ls /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata Found 26 items -rw-rw-rw-+ 3 trino hive 2011 2025-03-11 09:57 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/00000-db1abe31-9951-4907-8e07-e2d7fa7a0e59.metadata.json -rw-rw-rw-+ 3 trino hive 3079 2025-03-11 10:00 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/00001-883e0325-940e-4670-9e43-3ba1bd3fb670.metadata.json -rw-rw-rw-+ 3 trino hive 4147 2025-03-11 11:02 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/00002-8309486d-ce81-48e7-9c52-b1e88a97325f.metadata.json -rw-rw-rw-+ 3 trino hive 5215 2025-03-11 11:02 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/00003-5804837e-11f7-4485-a1d8-c3d2524b77b4.metadata.json -rw-rw-rw-+ 3 trino hive 6283 2025-03-11 11:02 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/00004-58711e7a-1cef-49f2-a317-85b1b0096ee9.metadata.json -rw-rw-rw-+ 3 trino hive 7346 2025-03-11 11:02 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/00005-04ca5d50-33ae-4698-bad6-7b0d866cc84e.metadata.json -rw-rw-rw-+ 3 trino hive 8415 2025-03-11 11:03 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/00006-639bcb75-12c1-4334-9428-24d2591877fe.metadata.json -rw-rw-rw-+ 3 trino hive 9483 2025-03-11 11:03 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/00007-7ccaa1a1-ec9e-4867-a69a-189192f31875.metadata.json -rw-rw-rw-+ 3 trino hive 10553 2025-03-11 11:03 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/00008-d3f60419-c0ea-4eb0-ad96-b43980ae4b7f.metadata.json -rw-rw-rw-+ 3 trino hive 6860 2025-03-11 11:03 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/1a70d037-966e-4897-abae-2992c66ffedb-m0.avro -rw-rw-rw-+ 3 trino hive 6858 2025-03-11 11:02 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/1ecf991c-2657-44d4-ae6c-9a284516fdd3-m0.avro -rw-rw-rw-+ 3 trino hive 6860 2025-03-11 11:02 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/3dee1668-01f0-4974-8dcf-e5c341b3c651-m0.avro -rw-rw-rw-+ 3 trino hive 6858 2025-03-11 11:03 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/9928ba6a-48b4-4664-b750-603aa990d646-m0.avro -rw-rw-rw-+ 3 trino hive 7001 2025-03-11 10:00 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/ab042f8d-10b2-496f-ba24-7af3d2060267-m0.avro -rw-rw-rw-+ 3 trino hive 6867 2025-03-11 11:03 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/ba560004-f1e0-4e80-ad4f-2bb887ad7f62-m0.avro -rw-rw-rw-+ 3 trino hive 6863 2025-03-11 11:02 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/bd35d283-2e52-47af-bc33-2deea47fd66c-m0.avro -rw-rw-rw-+ 3 trino hive 6858 2025-03-11 11:02 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/c0e4c07a-dbf3-4f80-ba38-df6f7d6f9d13-m0.avro -rw-rw-rw-+ 3 trino hive 4567 2025-03-11 11:02 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/snap-182139645478558741-1-3dee1668-01f0-4974-8dcf-e5c341b3c651.avro -rw-rw-rw-+ 3 trino hive 4328 2025-03-11 10:00 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/snap-1869625828739141539-1-ab042f8d-10b2-496f-ba24-7af3d2060267.avro -rw-rw-rw-+ 3 trino hive 4508 2025-03-11 11:02 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/snap-2163238739461654767-1-c0e4c07a-dbf3-4f80-ba38-df6f7d6f9d13.avro -rw-rw-rw-+ 3 trino hive 4671 2025-03-11 11:03 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/snap-3965304458163973624-1-1a70d037-966e-4897-abae-2992c66ffedb.avro -rw-rw-rw-+ 3 trino hive 4458 2025-03-11 11:02 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/snap-4061274609989317383-1-1ecf991c-2657-44d4-ae6c-9a284516fdd3.avro -rw-rw-rw-+ 3 trino hive 4399 2025-03-11 11:02 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/snap-4721261737924717847-1-bd35d283-2e52-47af-bc33-2deea47fd66c.avro -rw-rw-rw-+ 3 trino hive 4734 2025-03-11 11:03 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/snap-5241083456698083612-1-ba560004-f1e0-4e80-ad4f-2bb887ad7f62.avro -rw-rw-rw-+ 3 trino hive 4620 2025-03-11 11:03 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/snap-8151748187868208771-1-9928ba6a-48b4-4664-b750-603aa990d646.avro -rw-rw-rw-+ 3 trino hive 4125 2025-03-11 09:57 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/metadata/snap-8193860501641260728-1-c33f6189-e3dd-49a8-83f2-0e1445351da4.avro # hdfs dfs -ls /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/data Found 10 items drwxrwxrwx+ - trino hive 0 2025-03-11 10:00 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/data/name=Alice drwxrwxrwx+ - trino hive 0 2025-03-11 10:00 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/data/name=Bob drwxrwxrwx+ - trino hive 0 2025-03-11 10:00 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/data/name=Charlie drwxrwxrwx+ - trino hive 0 2025-03-11 11:02 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/data/name=Dong drwxrwxrwx+ - trino hive 0 2025-03-11 11:02 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/data/name=Hak drwxrwxrwx+ - trino hive 0 2025-03-11 11:02 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/data/name=Ji drwxrwxrwx+ - trino hive 0 2025-03-11 11:02 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/data/name=Min drwxrwxrwx+ - trino hive 0 2025-03-11 11:02 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/data/name=Sun drwxrwxrwx+ - trino hive 0 2025-03-11 11:03 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/data/name=Tae drwxrwxrwx+ - trino hive 0 2025-03-11 11:03 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/data/name=byeong # hdfs dfs -ls /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/data/name=Ji Found 1 items -rw-rw-rw-+ 3 trino hive 498 2025-03-11 11:02 /user/hive/warehouse/db1_test.db/jh-162714100c274631aa237fd420989161/data/name=Ji/20250311_020225_00018_r37cf-eaf4b9f7-b8c4-45a4-98a2-c41f23afedc7.parquet |
select * from iceberg.db1_test.jh;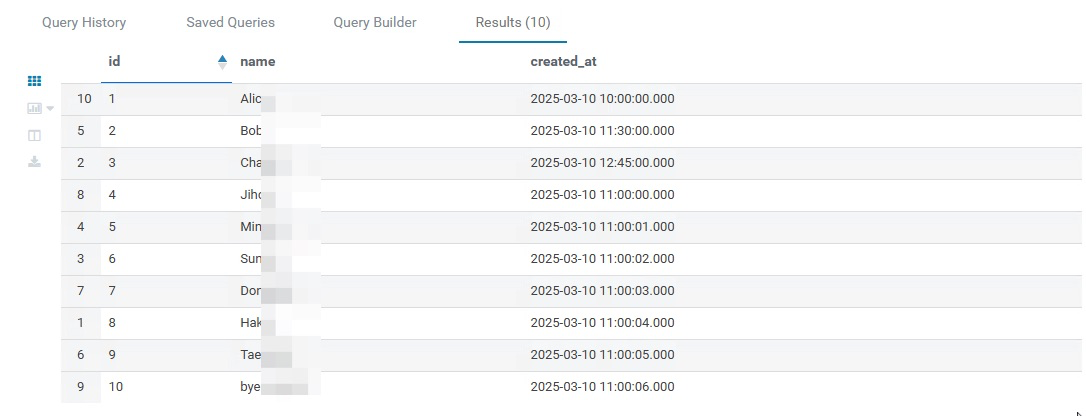
2.2. Time Traveling & Roll Back Query
2.2.1 Time Traveling Query
먼저 스냅샷 목록을 확인한다.
SELECT * FROM iceberg.db1_test."jh$snapshots";
스냅샷 ID나 시간대를 이용해서 그 당시 시점 테이블로 쿼리를 실행할 수 있다.
SELECT *
FROM iceberg.db1_test.jh FOR VERSION AS OF 8193860501641260728;
SELECT *
FROM iceberg.db1_test.jh FOR VERSION AS OF 1869625828739141539;
SELECT *
FROM iceberg.db1_test.jh FOR TIMESTAMP AS OF TIMESTAMP '2025-03-11 11:02:00.000 Asia/Seoul';
SELECT *
FROM iceberg.db1_test.jh FOR TIMESTAMP AS OF TIMESTAMP '2025-03-11 11:03:00.000 Asia/Seoul';
2.2.2. Roll Back Query
아예 특정 스냅샷 시점으로 테이블을 되돌릴 수 있다.
트리노 공식 홈페이지에서는 ALTER 쿼리를 사용하라고 하는데 우리환경에서는 CALL 프로시저로 해야한다..
--alter 쿼리 안됨
ALTER TABLE iceberg.db1_test.jh EXECUTE rollback_to_snapshot(8193860501641260728);
--아래 쿼리로 해야함
CALL iceberg.system.rollback_to_snapshot('db1_test', 'jh', 8193860501641260728);
이제 위 테이블은 삭제시켜준다.
drop table iceberg.db1_test.jh;
퀴즈)
메타데이터 파일에는 스냅샷 정보, 파티션 정보, 스키마 정보들을 포함한다. (O / X)
What is time travel in Apache Iceberg?
A) A feature that allows users to access data as it existed at a previous point in time.
B) A method to compress data efficiently.
C) A way to delete old versions of data permanently.
D) A technique used for data encryption.
What is the incorrect syntax to perform a time travel qeury in Iceberg?
A) SELECT * FROM table_name FOR TIMESTAMP AS OF 'timestamp';
B) SELECT * FROM table_name FOR VERSION AS OF 'snapshot_id';
C) SELECT * FROM table_name WHERE VERSION = 'timestamp';
When would you use the rollback query in Apache Iceberg?
A) To permanently delete old data from the system.
B) To restore a table to its state at a specified version.
C) To update records in a table.
D) To create a snapshot of the current data.
What is the correct syntax to perform a roll back query in BCS's Iceberg?
A) ALTER TABLE table_name EXECUTE rollback_to_snapshot('snapshot_id');
B) CALL iceberg.system.rollback_to_snapshot('db_name', 'table_name', snapshot_id );
C) ROLLBACK TABLE table_name TO 'snapshot_id';
2.3. Optimizing the Iceberg Table
2.3.1. Metadata file
| Spark3 |
|
CREATE TABLE my_iceberg_table (
id BIGINT,
name STRING,
timestamp TIMESTAMP
)
USING iceberg
PARTITIONED BY (days(timestamp))
TBLPROPERTIES (
'read.parquet.vectorization.enabled' = 'true',
'write.metadata.delete-after-commit.enabled' = 'true',
'write.metadata.previous-versions-max' = '5',
'history.expire.max-snapshot-age-ms' = '3600000', -- 1 hour (3600000 ms)
'history.expire.min-snapshots-to-keep' = '3' -- Keep at least 3 snapshot
);
|
| Trino |
| Trino 402버전에서 미지원 |
2.3.2. Manifest file
| Spark3 |
|
CALL catalog_name.system.rewrite_manifests('db_name.table_name')
|
| Trino |
| Trino 402버전에서 미지원 |
2.3.3. Snapshot file
| Spark3 |
|
CALL catalog_name.system.expire_snapshots(
table => 'db_name.table_name',
older_than => now(),
retain_last => 5
)
|
| Trino |
| ALTER TABLE iceberg.db1_test.jh1 EXECUTE expire_snapshots; ALTER TABLE iceberg.db1_test.jh1 EXECUTE expire_snapshots(retention_threshold => '1m'); |
Iceberg 카탈로그 설정(iceberg.expire_snapshots.min-retention=7d)의 기본값을 초과할 수 없다.
2.3.4. Orphan file
| Spark3 |
|
CALL catalog_name.system.remove_orphan_files(
table => 'db_name.table_name'
)
#특정 로케이션의 고아파일을 지우고 싶은 경우
CALL catalog_name.system.remove_orphan_files(
table => 'db_name.table_name',
location => 'table_location/data'
)
|
| Trino |
|
ALTER TABLE iceberg.db1_test.jh1 EXECUTE remove_orphan_files;
ALTER TABLE iceberg.db1_test.jh1 EXECUTE remove_orphan_files(retention_threshold => '1m');
|
Iceberg 카탈로그 설정( iceberg.remove_orphan_files.min-retention =7d)의 기본값을 초과할 수 없다.
* 참고
Trino 402버전에서 사용가능한 Iceberg catalog configuration들은 Coordinator Node의 Trino Log에서 확인할 수 있다.
| $ vim /var/log/trino/server.log |
| iceberg.catalog.type HIVE_METASTORE HIVE_METASTORE iceberg.compression-codec ZSTD ZSTD iceberg.delete-schema-locations-fallback false false Whether schema locations should be deleted when Trino can't determine whether they contain external files. iceberg.dynamic-filtering.wait-timeout 0.00s 0.00s Duration to wait for completion of dynamic filters during split generation iceberg.expire_snapshots.min-retention 7.00d 1.00m Minimal retention period for expire_snapshot procedure iceberg.experimental.extended-statistics.enabled false false Allow ANALYZE and use of extended statistics collected by it. Currently, the statistics are collected in Trino-specific format iceberg.file-format ORC PARQUET iceberg.format-version 2 2 Default Iceberg table format version iceberg.hive-catalog-name ---- ---- Catalog to redirect to when a Hive table is referenced iceberg.materialized-views.storage-schema ---- ---- Schema for creating materialized views storage tables iceberg.max-partitions-per-writer 100 100 Maximum number of partitions per writer iceberg.minimum-assigned-split-weight 0.05 0.05 Minimum weight that a split can be assigned iceberg.projection-pushdown-enabled true true Read only required fields from a struct iceberg.remove_orphan_files.min-retention 7.00d 1.00m Minimal retention period for remove_orphan_files procedure iceberg.table-statistics-enabled true true Enable use of table statistics iceberg.target-max-file-size 1GB 128MB Target maximum size of written files; the actual size may be larger iceberg.unique-table-location true true Use randomized, unique table locations iceberg.use-file-size-from-metadata true true iceberg.security ALLOW_ALL ALLOW_ALL |
2.4. Migration Hive Table
https://iceberg.apache.org/docs/1.4.1/hive-migration/
Trino 402버전에서는 Hive Table을 migration할 수 있는 쿼리가 없다.
따라서 Spark3를 사용해야 한다.
현재 Hue에 Spark3-sql 설정했지만 Memory부족이슈로 쉘에서 진행한다.
Apache Hive supports ORC, Parquet, and Avro file formats that could be migrated to Iceberg.
ORC, Parquet, Avro파일 형식을 가진 Hive은 Iceberg table로 마이그레이션 가능
Iceberg supports all three migration actions: Snapshot Table, Migrate Table, and Add Files for migrating from Hive tables to Iceberg tables.
마이그레이션 방법은 세 가지가 있다. (Snapshot Table, Migrate Table, Add Files)
일단 예제로 Spark3에서 Iceberg사용할 수 있도록 셋팅한다.
Ambari > spark3 > configs > Custom spark3-defaults

이때 spark_catalog로 이름짓는다.
그리고 Spark3 재기동
사용할 External Hive Table을 만든다.
| spark-sql> show catalogs; spark_catalog Time taken: 3.572 seconds, Fetched 1 row(s) spark-sql> show schemas in spark_catalog; db1_test default information_schema jh_test sys test_de01 vcrm_master Time taken: 0.212 seconds, Fetched 7 row(s) spark-sql> CREATE EXTERNAL TABLE spark_catalog.db1_test.example_hive1 ( id INT, name STRING, age INT ) STORED AS parquet LOCATION '/user/hive/warehouse/db1_test.db/example_hive1'; |
대량 데이터 Insert를 위해 pyspark3사용
| $ pyspark3 sc.stop() from pyspark.sql import Row spark = SparkSession.builder \ .appName("Insert Data into Example Hive Table") \ .enableHiveSupport() \ .getOrCreate() # 1,000,000개의 데이터 생성 data = [Row(id=i, name=f"Name_{i}", age=20 + (i % 30)) for i in range(1, 1000001)] df = spark.createDataFrame(data) # 테이블에 데이터 삽입 df.write.mode("append").insertInto("spark_catalog.db1_test.example_hive1") |
Migration시 한계점
-Due to a bug in Apache Iceberg it is not possible to migrate tables that are partitioned by string columns having a partition value that contains the forward slash ‘/’ character.
Partition된 Hive table의 Partition column이 string이고 값에 '/'이 있을 경우 불가능
-Some column types supported by Hive tables are not supported by Iceberg tables, such as tinyint or smallint. Tables with such columns are not migrated to Iceberg.
tinyint, smallint 등과 같이 hive data type과 Iceberg data type 호환이 안되는 경우 불가능
- The original Hive table must be in AVRO, ORC, or Parquet format.
Hive table의 파일 포맷은 Avro, Orc, Parquet만 가능
-Importing or migrating tables are supported only on existing external Hive tables.
오로지 Hive External Table만 지원된다.
2.4.1. Snapshot Table (단순히 hive table의 스키마만 마이그레이션, 데이터는 X)
기존의 Hive table으로부터 Iceberg table의 snapshot만 만들어주는 프로시저이다.
CALL spark_catalog.system.snapshot('db1_test.example_hive1', 'db1_test.mig_hive_1');
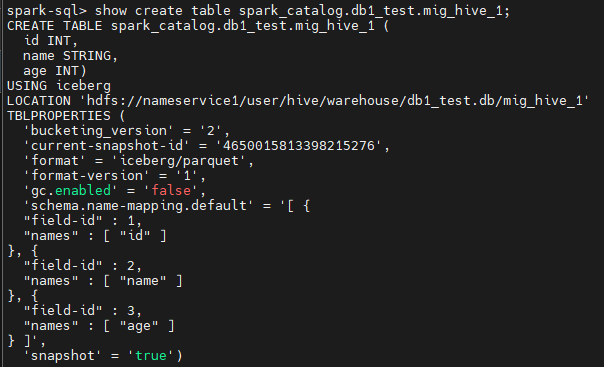
| # hdfs dfs -ls /user/hive/warehouse/db1_test.db/mig_hive_1/* Found 3 items /user/hive/warehouse/db1_test.db/mig_hive_1/metadata/00000-bc1479ee-962d-4a1f-81dd-1053b58f8ae9.metadata.json /user/hive/warehouse/db1_test.db/mig_hive_1/metadata/ae3b668d-1d9e-4534-ba83-42a58fcb9cd4-m0.avro /user/hive/warehouse/db1_test.db/mig_hive_1/metadata/snap-4650015813398215276-1-ae3b668d-1d9e-4534-ba83-42a58fcb9cd4.avro |
여러 옵션값들과 함께 사용될 수도 있다.
CALL <catalog>.system.snapshot(
source_table => '<src>',
table => '<dest>',
properties => map('format-version', '2', 'write.delete.mode', '<delete-mode>', 'write.update.mode', '<update-mode>', 'write.merge.mode', '<merge-mode>'));
| 구분 | 결과 |
| 기존 하이브 테이블 | 변동없음 |
| 아이스버그 테이블 | 새로 생성됨 |
| 실제 데이터파일 | 변동없음 |
2.4.2. Migrate Hive Table To Iceberg (스키마와 데이터 모두 마이그레이션)
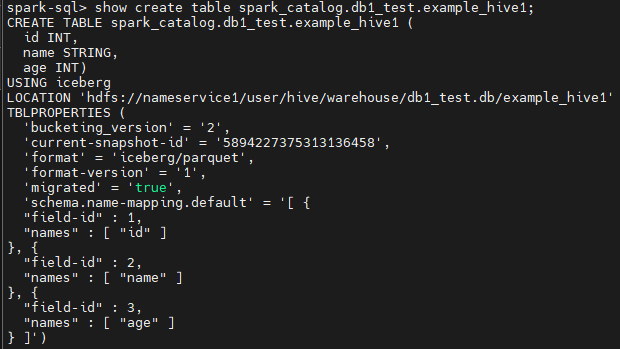
CALL spark_catalog.system.migrate('db1_test.example_hive1');
위 프로시저 실행하면 기존 hive table은 백업본이 생기고,
기존 하이브 테이블명과 동일한 Iceberg 테이블이 생성된다.
| # hdfs dfs -ls /user/hive/warehouse/db1_test.db/example_hive1/* | awk '{print $NF}' /user/hive/warehouse/db1_test.db/example_hive1/metadata/00000-6ff6233f-0ce2-4466-b2fb-667c78e7fa6a.metadata.json /user/hive/warehouse/db1_test.db/example_hive1/metadata/30bdfe81-5492-4f9a-bcb3-e002d288b974-m0.avro /user/hive/warehouse/db1_test.db/example_hive1/metadata/snap-2484116598038403429-1-30bdfe81-5492-4f9a-bcb3-e002d288b974.avro /user/hive/warehouse/db1_test.db/example_hive1/part-00000-9bfe60fd-6dd4-4ae0-b67a-c5c34234e64c-c000.snappy.parquet /user/hive/warehouse/db1_test.db/example_hive1/part-00001-9bfe60fd-6dd4-4ae0-b67a-c5c34234e64c-c000.snappy.parquet |
따로 data 디렉터리가 만들어지지 않는다.
여러가지 옵션값과 함께 사용될 수 있다.
CALL <catalog>.system.migrate('<src>', map('format-version', '2', 'write.delete.mode', '<delete-mode>', 'write.update.mode', '<update-mode>', 'write.merge.mode', '<merge-mode>'))
| 구분 | 결과 | 비고 |
| 기존 하이브 테이블 | 변동없음, 백업용 하이브테이블 생성됨 | 백업용 테이블의 데이터 로케이션도 기존 하이브 테이블 로케이션과 동일 즉, 기존 하이브 로케이션 = 백업된 하이브 로케이션 = 마이그레이션된 아이스버그 로케이션 |
| 아이스버그 테이블 | 기존 하이브 테이블이 아이스버그 테이블이 됨 | |
| 실제 데이터파일 | 변동없음 | data디렉터리는 안생긴다. 기존 데이터 파일은 기존 하이브 디렉터리에서 그냥 가만히 있음. |
2.4.3. Add Files From Hive Table to Iceberg
-아이스버그 테이블이 미리 존재해야 한다.
-add_files 프로시저 실행하면 단순히 iceberg의 manifest file에서 data path를 기존 path를 가리키게 된다.
(데이터가 옮겨지는게 아님)
테스트를 위해 다시 Hive external table을 하나 만들어주고, 기존 example_hive1테이블의 parquet파일을 복사해서 옮겨준다.
| spark-sql> CREATE EXTERNAL TABLE spark_catalog.db1_test.example_hive2 ( id INT, name STRING, age INT ) STORED AS parquet LOCATION '/user/hive/warehouse/db1_test.db/example_hive2'; # hdfs dfs -cp /user/hive/warehouse/db1_test.db/example_hive1/*.parquet /user/hive/warehouse/db1_test.db/example_hive2/ |
위에서 만들었던 껍데기 Iceberg테이블에 기존 Hive테이블의 데이터를 넣어주려면 아래 명령어를 실행
CALL spark_catalog.system.add_files(
table => 'db1_test.mig_hive_1',
source_table => 'db1_test.example_hive2'
);
| 구분 | 결과 | 비고 |
| 기존 하이브 테이블 | 변동없음 | |
| 아이스버그 테이블 | manifest file에서 data path만 추가됨 | Iceberg테이블이 미리 존재해야 한다. |
| 실제 데이터파일 | 변동없음 |
따라서 웬만해선 migrate 프로시저를 사용하는 것을 권장한다.
기타 참고
Spark에서 iceberg table drop시 Hive metastore엔 적용이 돼서 테이블은 드랍되지만 HDFS에 실제 데이터는 남아있다.
Trino에선 테이블, 실제 데이터 모두 삭제된다.
다음엔 Spark를 이용한 Iceberg 테이블 관련한 내용을 준비할 예정



