
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 알고리즘
- 프로그래머스
- 백준
- 코딩테스트
- 자바
- 코엑스맛집
- 개발
- dfs
- bigdata engineer
- 양평
- Trino
- hadoop
- bigdata engineering
- 삼성역맛집
- 여행
- 맛집
- HIVE
- BigData
- 코딩
- 코테
- Iceberg
- Data Engineering
- 용인맛집
- BFS
- java
- 영어
- 코엑스
- 파이썬
- Data Engineer
- apache iceberg
- Today
- Total
지구정복
[Iceberg] Iceberg Guide Book Summary | CHAPTER 6. Apache Spark 본문
[Iceberg] Iceberg Guide Book Summary | CHAPTER 6. Apache Spark
noohhee 2025. 3. 9. 21:12
CHAPTER 6 Apache Spark
Configuration
Configuring Apache Iceberg and Spark
Configuring via the CLI
As a first step, you’ll need to specify the required packages to be installed and used with the Spark session. To do so, Spark provides the --packages option, which allows Spark to easily download the specified Maven-based packages and its dependencies to add them to the classpath of your application.
Here is the command to start a Spark shell with Apache Iceberg:
| spark-shell --packages org.apache.iceberg:iceberg-spark-runtime-3.3_2.12:1.3.0 |
Similarly, if you want to make these configurations in your Spark SQL session, you can include the package name, as shown in the following command:
| spark-sql --packages org.apache.iceberg:iceberg-spark-runtime-3.3_2.12:1.3.0 |
This JAR contains the Iceberg classes and extensions needed for Spark to interpret and manipulate Iceberg tables. Including the JAR file can be done via the command line when starting a Spark shell or Spark submit:
| ./bin/spark-shell --jars /path/to/iceberg-spark-runtime.jar |
Configuring via Python code (PySpark)
Before you start a PySpark session with Apache Iceberg, you will need to have the following installed:
• Java (v8 or v11)
• PySpark
• Apache Spark (the version depends on the Iceberg version)
To start a PySpark Session that includes all the Iceberg-related libraries, you will need to use the SparkSession.builder object in PySpark.
from pyspark.sql import *
from pyspark import SparkConf
# Create a Spark Configuration
conf = SparkConf()
# Set Configurations
conf.set("spark.jars.packages", "org.apache.iceberg:iceberg-sparkruntime-
3.3_2.12:1.2.0")
# Create Spark Session
spark = SparkSession.builder.config(conf=conf).getOrCreate()
## Spark Session Object can then be used to run queries with
## the spark.sql("SELECT * FROM table") function
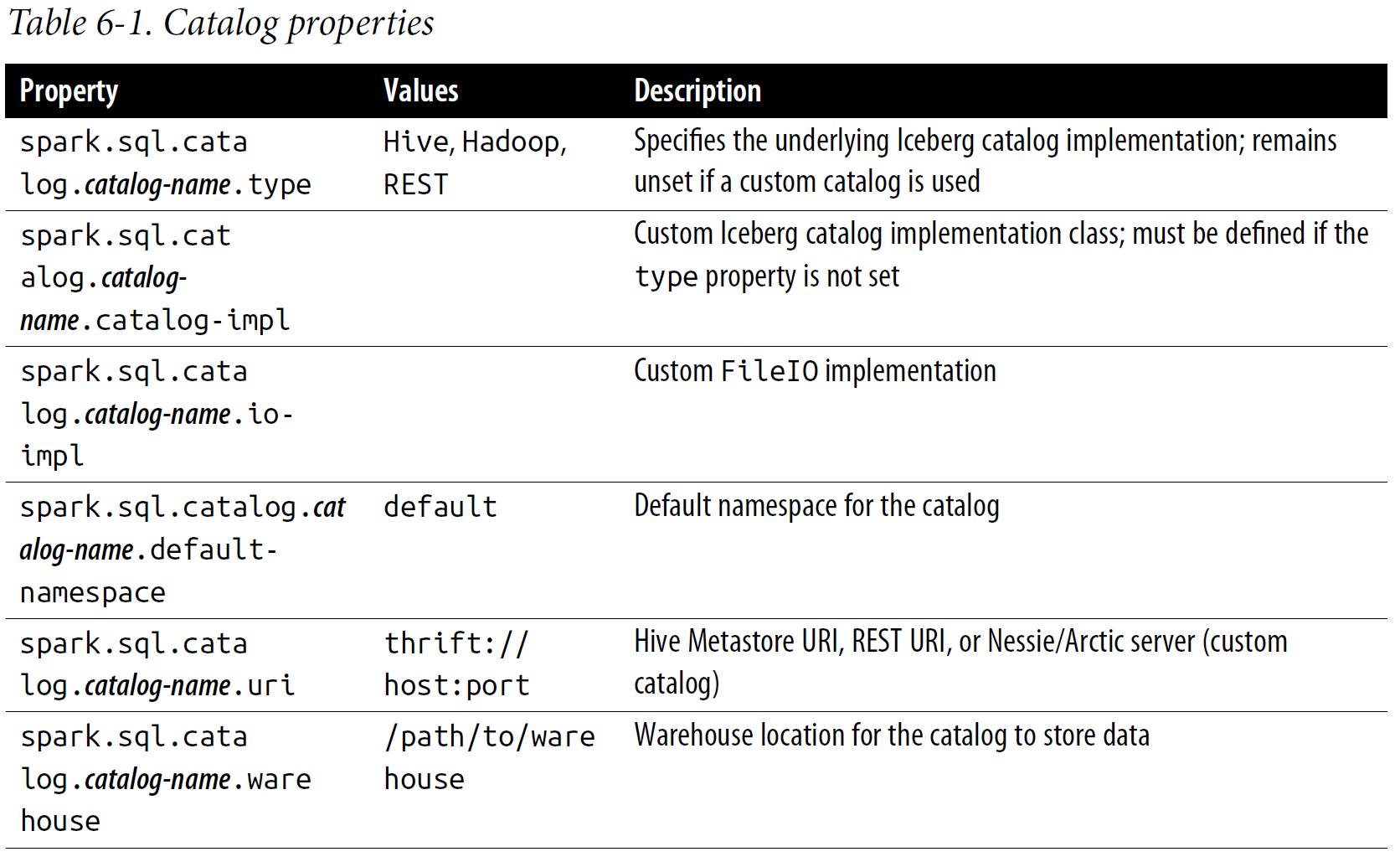
Configuring the Catalogs
In a nutshell, a catalog is a logical namespace that holds metadata information about the Iceberg tables and provides a unified view of the data to various compute engines, bringing in reliability and consistency guarantees for the transactions.
Therefore, a catalog is one of the first things you would configure to work with Iceberg tables.
Configuring a catalog in Spark involves defining and naming it in the Spark session configuration, either programmatically in your PySpark code or in the Spark shell.
This is done by setting the Spark property spark.sql.catalog.<catalog-name> with an implementation class for its value.
| spark.sql.catalog.my_catalog =org.apache.iceberg.spark.SparkCatalog |
Using org.apache.iceberg.spark.SparkCatalog
When configured to use a Hive Metastore (by setting the catalog type to hive), SparkCatalog uses Hive’s Metastore to store table metadata, allowing you to leverage Hive’s metadata management features.
Alternatively, if you set the catalog type to hadoop, SparkCatalog will use a directory-based catalog in Hadoop or any other filesystem to store table metadata. Here is an example of how to configure a SparkCatalog with Hive:
| spark.sql.catalog.hive_catalog = org.apache.iceberg.spark.SparkCatalog spark.sql.catalog.hive_catalog.type = hive spark.sql.catalog.hive_catalog.uri = thrift://metastore-host:port |
Using org.apache.iceberg.spark.SparkSessionCatalog
The SparkSessionCatalog is a more specialized implementation that wraps around Spark’s built-in session catalog, adding support for Iceberg tables. This could benefit scenarios when you want to use Iceberg tables seamlessly alongside non-Iceberg tables in your Spark session.
Here, all the non-Iceberg tables are managed by the built-in Spark catalog while the tables specific to Iceberg are managed separately through the SparkSessionCatalog class.
Here is an example of this configuration:
| spark.sql.catalog.hive_spark_catalog = org.apache.iceberg.spark.SparkSessionCatalog spark.sql.catalog.hive_spark_catalog.type = hive spark.sql.catalog.hive_spark_catalog.uri = thrift://localhost:9083 |
Data Definition Language Operations
CREATE TABLE
spark.sql("""
CREATE TABLE glue.test.employee (
id INT,
role STRING,
department STRING,
salary FLOAT,
region STRING)
USING iceberg
""")
Create a table with partitions
spark.sql("""
CREATE TABLE glue.test.emp_partitioned (
id INT,
role STRING,
department STRING)
USING iceberg
PARTITIONED BY (department)
""")
Apache Iceberg also supports hidden partitioning, which means you don’t have to add or manage explicit partition columns, unlike in table formats such as Hive.
Iceberg takes a column and internally transforms it into a partition value while keeping track of the relationship.
This happens behind the scenes, so users won’t have to deal with it when querying data.
spark.sql("""
CREATE TABLE glue.test.emp_partitioned_month (
id INT,
role STRING,
department STRING,
join_date DATE
)
USING iceberg
PARTITIONED BY (months(join_date))
""")
This statement will create an Iceberg table called emp_partitioned_month that is partitioned by month of join_date. In this case, Iceberg does the transformation of join_date to months(ts) internally and tracks the relationship between these two,
avoiding the need to create an additional partition column. This way, users don’t have to worry about the physical layout of the table. Other supported transformations include the following:
• year(ts): Partition by year.
• months(ts): Partition by month.
• days(ts) or date(ts): dateint partitioning.
• hours(ts) or date_hour(ts): dateint and hour partitioning.
• bucket(N, col): Partition by hash value mod N (Number) buckets.
• truncate(L, col): Partition by value truncated to L (Length).
Use the CREATE TABLE…AS SELECT statement
The CREATE TABLE…AS SELECT (CTAS) statement allows you to create and populate a new table with records simultaneously.
One important thing to note when running CTAS in the context of Apache Iceberg is that it works as an atomic operation only when using the SparkCatalog class. If you use the SparkSessionCata log class, CTAS is supported but is not atomic, which may cause inconsistencies when concurrent writes are occurring.
spark.sql("""
CREATE TABLE glue.test.employee_ctas
USING iceberg
AS SELECT * FROM glue.test.sample
""")
Note that the original table’s partition specification and other properties are not automatically inherited when using CTAS. You can manually set these properties by using the PARTITIONED BY clause and the TBLPROPERTIES command in your CTAS statement.
spark.sql("""
CREATE TABLE glue.test.emp_ctas_partition
USING iceberg
PARTITIONED BY (category)
TBLPROPERTIES (write.format.default='avro')
AS SELECT *
FROM glue.test.sample
""")
ALTER TABLE
Rename a table
spark.sql("""
ALTER TABLE glue.test.employee RENAME TO glue.test.emp_renamed
""")
Set table properties
spark.sql("""
ALTER TABLE glue.test.employee SET TBLPROPERTIES ('write.wap.enabled'='true')
""")
Add a column
spark.sql("""
ALTER TABLE glue.test.employee ADD COLUMN manager STRING
""")You can add multiple columns at the same time using separated commas:
spark.sql("""
ALTER TABLE glue.test.employee ADD COLUMN details STRING, manager_id INT
""")
Rename a column
spark.sql("""
ALTER TABLE glue.test.employee RENAME COLUMN role TO title
""")
Modify a column
spark.sql("""
ALTER TABLE glue.test.employee ALTER COLUMN id TYPE BIGINT
""")
Drop a column
spark.sql("""
ALTER TABLE glue.test.employee DROP COLUMN department
""")
Alter a Table with Iceberg’s Spark SQL Extensions
Apache Iceberg has an extension module in Spark that allows you to run additional operations that are not part of standard SQL.
import pyspark
from pyspark.sql import SparkSession
import os
conf = (
pyspark.SparkConf()
.setAppName('app_name')
# This property allows us to add any extensions that we want to use
.set('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions')
spark = SparkSession.builder.config(conf=conf).getOrCreate()
Add/drop/replace a partition
spark.sql("""
ALTER TABLE glue.test.employee ADD PARTITION FIELD region
""")
spark.sql("""
ALTER TABLE glue.test.employee DROP PARTITION FIELD department
""")
spark.sql("""
ALTER TABLE glue.test.employee REPLACE PARTITION FIELD region WITH department
""")The preceding example replaces the existing region partition field with a new partition field, department, in the employee table.
Set the write order
To set a sort order for a table, Iceberg provides the ALTER TABLE...WRITE ORDERED BY command.
spark.sql("""
ALTER TABLE glue.test.employee WRITE ORDERED BY id ASC
""")
Set the write distribution
Iceberg gives you control over how the data is distributed among writers.
The default implementation of this feature uses hash distribution.
spark.sql("""
ALTER TABLE glue.test.employee WRITE DISTRIBUTED BY PARTITION
""")
Upon executing this query, every partition in the employee table will be handled by an individual writer.
Set/drop identifier fields
spark.sql("""
ALTER TABLE glue.test.employee SET IDENTIFIER FIELDS id
""")In the preceding example, the id field is set as the identifier for the employee table, uniquely identifying each record.
spark.sql("""
ALTER TABLE glue.test.employee DROP IDENTIFIER FIELDS id
""")
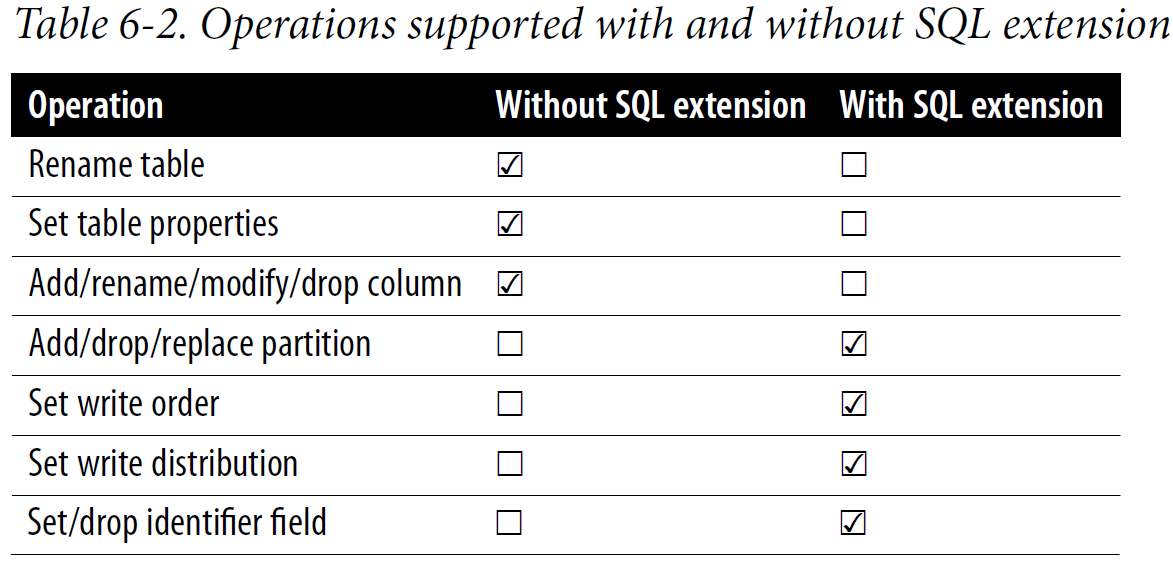
Table 6-2 provides a brief overview of the ALTER operations covered in this section, outlining situations where SQL extensions could be necessary and where they are not required.
DROP TABLE
spark.sql("DROP TABLE glue.test.employee")
If you intend to delete the table and its contents, you can use the DROP TABLE…PURGE command:
spark.sql("DROP TABLE glue.test.employee PURGE")
Reading Data
The Select All Query
spark.sql("SELECT * FROM glue.test.employee").show()The Filter Rows Query
spark.sql("SELECT * FROM glue.test.employee WHERE department = 'Marketing'").show()
Aggregation Queries
생략
Writing Data
INSERT INTO
MERGE INTO
MERGE INTO is used to update an existing row based on whether a specific condition is met or not. If it is not met, you just insert the new record into the table.
spark.sql("""
MERGE INTO glue.test.employee AS target
USING (SELECT * FROM employee_updates) AS source
ON target.id = source.id
WHEN MATCHED AND source.role = 'Manager' AND source.salary > 100000 THEN
UPDATE SET target.salary = source.salary
WHEN NOT MATCHED THEN
INSERT *
""")
INSERT OVERWRITE
Apache Spark provides two overwrite modes for this operation: static and dynamic (by default, the mode is static).
Static overwrite
In static overwrite mode, Spark converts the PARTITION clause into a filter (predicate) for determining which partitions to overwrite.
If you run the query without the PARTITION clause, it will replace all partitions.
Note that this mode cannot replace hidden partitions because the PARTITION clause can only reference table columns.
spark.sql("""
INSERT OVERWRITE glue.test.employees
PARTITION (region = 'EMEA')
SELECT *
FROM employee_source
WHERE region = 'EMEA'
""")
Dynamic overwrite
To configure dynamic overwrite mode, set the Spark config property, spark.sql.sources.partitionOverwriteMode=dynamic.
In this mode, any partitions that correspond to rows returned by the SELECT query are replaced:
In the following query, any partition in the employee table that matches the data produced by the SELECT query will be replaced.
Since we filter the employee_source table with only the EMEA region data, only the corresponding EMEA partition will be
overwritten in the employee table.
spark.sql("""
INSERT OVERWRITE glue.test.employee
SELECT * FROM employee_source
WHERE region = 'EMEA'
""")
The dynamic overwrite mode is generally recommended when writing to Iceberg tables because it provides granular control over which partitions get overwritten based on the query’s outcome.
DELETE FROM
DELETE FROM allows you to remove records from an Iceberg table based on a filter.
spark.sql("DELETE FROM glue.test.employee WHERE id < 3")
UPDATE
spark.sql("""
UPDATE glue.test.employee
SET region = 'APAC', salary = 6000
WHERE id = 6
""")spark.sql("""
UPDATE glue.test.employee AS e
SET region = 'NA'
WHERE EXISTS (SELECT id FROM emp_history WHERE emp_NA.id = e.id)
""")
Iceberg Table Maintenance Procedures
Expire Snapshots
Any modification to the data in Iceberg—be it an insert, update, delete, or upsert generates a new snapshot.
Over a period of time you might end up with a lot of snapshots and not all of them might be necessary.
The expire_snapshots procedure in Spark helps remove these older, unnecessary snapshots along with their
datafiles.
# Generic procedure
CALL catalog_name.system.expire_snapshots(table, older_than, retain_last)
spark.sql("CALL glue.system.expire_snapshots('test.employees', date_sub(current_
date(), 90), 50)")This procedure deletes snapshots from the employee table that are older than 90 days from the current date, while preserving the most recent 50 snapshots.
Rewrite Datafiles
The number of datafiles in a table has a direct impact on the performance of the queries since there is a huge cost associated with opening, reading, and closing each of the datafiles that are covered by the query.
Also, a larger number of small files may cause unnecessary metadata overhead.
The rewrite_data_files procedure in Spark allows you to compact these small files into larger ones for addressing these issues.
# Generic procedure
CALL catalog_name.system.rewrite_data_files(table, strategy, sort_order, options)
spark.sql("CALL glue.system.rewrite_data_files('test.employee')")
The preceding procedure rewrites the datafiles by combining the small files in the employee table using the default binpack algorithm and splits larger ones into smaller files as per the default write size of the table.
Rewrite Manifests
Manifest files in Iceberg tables play a crucial role in optimizing scan planning as they keep statistical information about the datafiles.
The rewrite_manifests procedure allows you to rewrite these manifests in parallel, thereby improving the speed and efficiency of data scans.
# Generic procedure
CALL catalog_name.system.rewrite_manifests(table)
spark.sql("CALL test.system.rewrite_manifests('test.employee')")
Remove Orphan Files
Over time, certain datafiles in an Iceberg table might lose their reference in any metadata files and become “orphaned.”
These files take up unnecessary storage space and might lead to inconsistencies.
The remove_orphan_files procedure takes care of removing these orphaned files.
# Generic procedure
CALL catalog_name.system.remove_orphan_files(table, older_than, dry_run)
CALL glue.system.remove_orphan_files(table => 'test.employee', dry_run => true)



