
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- bigdata engineering
- 알고리즘
- 여행
- Spark
- 코테
- pyspark
- Kafka
- 자바
- 용인맛집
- Iceberg
- 영어
- Apache Kafka
- 코엑스
- 삼성역맛집
- 코엑스맛집
- hadoop
- bigdata engineer
- 코딩
- HIVE
- 코딩테스트
- Data Engineer
- Data Engineering
- 개발
- 맛집
- Trino
- apache iceberg
- 프로그래머스
- 백준
- BigData
- java
- Today
- Total
지구정복
[Kafka] 3. Consumer Group 본문
1. What are Kafka Consumer Groups?
Kafka 소비자는 컨슈머 그룹(consumer group)의 일부로 동작할 수 있으며, 하나 이상의 소비자가 같은 토픽에서 메시지를 소비할 수 있습니다.
이들은 서로 간섭하지 않고 하나의 메시지 스트림을 읽습니다.
하지만 왜 컨슈머 그룹이 필요한 걸까요?
1.1. Need for Consumer Groups
Kafka 설계에서 확장성(Scalability)은 필수적인 요소입니다.
확장을 용이하게 하기 위해, Kafka 토픽은 여러 프로듀서가 이벤트를 기록하고 여러 컨슈머가 해당 이벤트를 구독할 수 있도록 설계되어 있습니다.
Kafka 토픽에서 메시지를 읽는 클라이언트 애플리케이션을 생각해봅시다.
이 애플리케이션은 컨슈머 객체를 생성하고, 적절한 토픽을 구독한 다음 메시지 수신을 시작합니다.
수신한 메시지를 검증한 후 저장합니다.
하지만 여러 프로듀서가 빠른 속도로 토픽에 메시지를 기록하면, 하나의 컨슈머 객체로는 이 메시지들을 충분히 빠르게 처리할 수 없습니다.
클라이언트 애플리케이션은 증가한 메시지 수신 속도를 감당할 수 없게 됩니다.
이럴 때 토픽 소비를 확장하기 위해 추가 컨슈머를 도입해야 하며, 바로 여기서 컨슈머 그룹이 등장합니다.
컨슈머 그룹은 여러 컨슈머가 동일한 토픽을 읽을 수 있게 하며, 파티션을 서로 나누어 처리하게 합니다.
메시지는 컨슈머 그룹 구성원들 간에 분산되어, 각 메시지는 단 하나의 컨슈머만 소비하게 됩니다.
이러한 데이터 분산 구조는 확장성에 필수적이며, 다수의 이벤트를 동시에 읽을 수 있게 해줍니다.
2. How does a Kafka Consumer Group Work?
Kafka 토픽은 순서가 보장된 파티션으로 세분화됩니다.
프로듀서가 토픽에 새로운 이벤트를 기록할 때마다, 해당 이벤트는 파티션의 끝에 추가됩니다.
동일한 컨슈머 그룹의 구성원들은 토픽 파티션의 서로 다른 하위 집합으로부터 메시지를 수신합니다.
실제로, 각 파티션은 그룹 내 단 하나의 컨슈머에 의해 소비됩니다.
컨슈머 그룹은 파티션을 자동으로 균형 있게 조정하면서 메시지 또는 파티션을 여러 컨슈머 간에 분배하는 작업을 관리합니다.
이제 다양한 시나리오를 살펴보면서 이를 더 자세히 이해해봅시다.
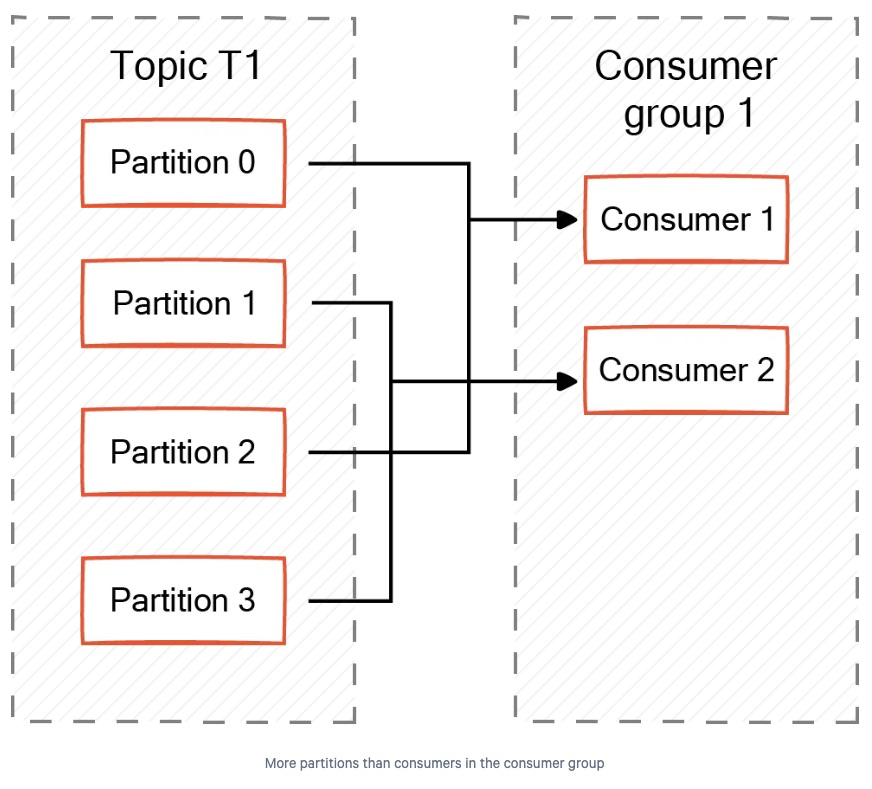
2.1. More Partitions than Consumers
Kafka 토픽의 파티션 수가 컨슈머 그룹 내 컨슈머 수보다 많을 경우, 모든 파티션은 컨슈머들 사이에서 자동으로 균형 있게 분배됩니다.
각 컨슈머는 일부 파티션을 할당받아, 파티션이 고르게 분산되도록 보장합니다.
예를 들어, 사용자 요청을 처리하고 이를 Kafka 토픽에 기록하는 웹 애플리케이션이 있다고 가정해봅시다.
이 토픽은 4개의 파티션을 가지고 있고, 요청을 처리하기 위해 2개의 컨슈머로 구성된 컨슈머 그룹이 존재합니다.
이 경우, 각 컨슈머는 서로 다른 2개의 파티션을 할당받습니다.
이러한 방식 덕분에, 단일 컨슈머가 모든 요청을 혼자 처리할 필요가 없으며, 시스템의 가용성(availability) 또한 높아집니다.
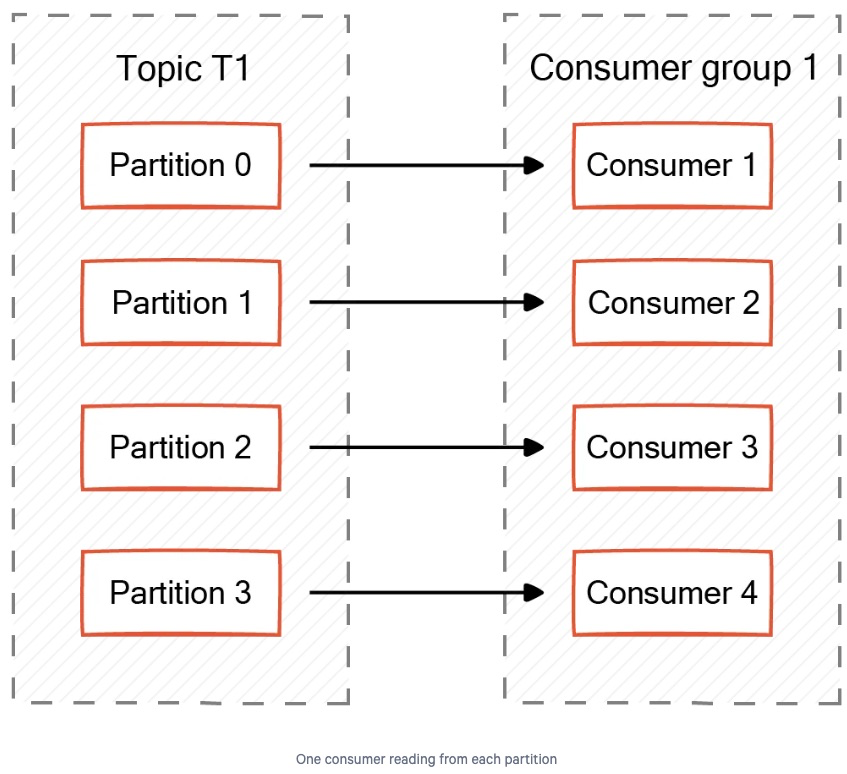
2.2. Partitions Equal to Consumers
Kafka 토픽의 파티션 수가 컨슈머 그룹 내 컨슈머 수와 같을 경우, 각 컨슈머는 하나의 파티션을 할당받습니다.
예를 들어, 지역별로 컨슈머가 그룹화된 이커머스 플랫폼을 생각해봅시다.
이 Kafka 토픽은 해당 지역에 따라 4개의 파티션으로 분할되어 있습니다.
이 설정에서는 각 컨슈머가 하나의 파티션에 할당되어 특정 지역의 모든 주문이나 요청을 소비합니다.
이 경우, 자체 밸런싱(self-balancing)이 필요하지 않으며, 메시지 처리 또한 더욱 효율적으로 이루어집니다.
2.3. Partitions less than Consumers
Kafka 토픽의 파티션 수가 컨슈머 그룹 내 컨슈머 수보다 적을 경우, 항상 메시지를 소비하지 않고 대기하는 컨슈머가 존재하게 됩니다.
이 대기 중인 컨슈머는, 파티션이 할당된 컨슈머 중 하나가 실패했을 때 도움을 줄 수 있습니다.
중요한 점은, 만약 어떤 컨슈머가 실패하면 사용 가능한 다른 컨슈머가 자동으로 해당 파티션을 인계받게 되며, 이로 인해 대기 상태인 컨슈머가 없어지게 된다는 것입니다.
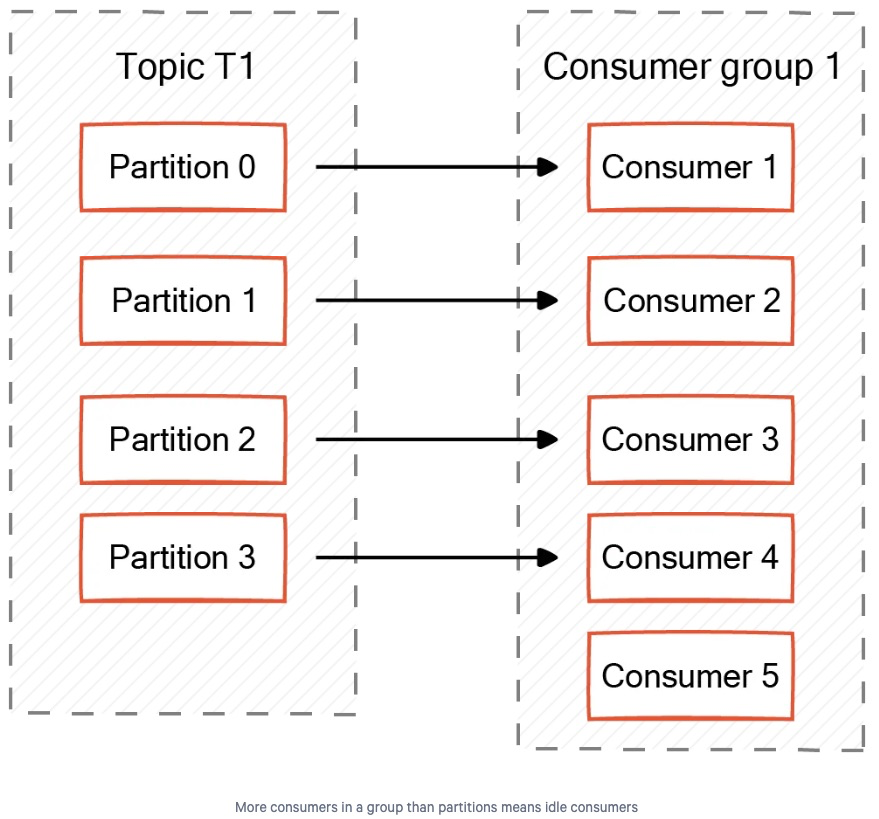
예를 들어, 고객 지원 서비스를 제공하는 회사가 있다고 가정해봅시다.
이 회사에는 5명의 상담원(컨슈머)이 있으며, 이들은 하나의 컨슈머 그룹으로 구성되어 있습니다.
Kafka 토픽은 들어오는 요청이나 전화를 처리합니다.
이 토픽에는 4개의 파티션이 있습니다.
파티션 수가 컨슈머 수보다 적기 때문에, 항상 1명의 상담원이 대기 상태가 됩니다.
이 대기 중인 상담원은, 활성 상담원이 장애를 겪거나 사용 불가능해질 경우에만 요청을 처리하게 됩니다.
덕분에 고객들은 서비스 중단을 경험하지 않게 됩니다.
대기 중인 상담원은 자연스럽게 요청을 인계받아 고객의 문제를 즉시 해결할 수 있습니다.
2.4. Multiple Consumer Groups
하나의 Kafka 토픽을 소비하는 여러 개의 컨슈머 그룹이 존재할 수 있습니다.
하나의 컨슈머 그룹 내에서는, 각 컨슈머가 오직 하나의 파티션만 소비합니다.
하지만 여러 컨슈머 그룹이 존재하는 경우, 서로 다른 그룹에 속한 여러 컨슈머가 동일한 파티션으로부터 메시지를 읽을 수 있습니다.

예를 들어, 소셜 미디어 플랫폼이 있다고 가정해봅시다.
이 플랫폼은 게시물과 댓글을 기준으로 파티셔닝된 데이터 스트림을 처리하기 위해 Kafka 토픽을 유지 관리하고 있습니다.
여기에는 두 개의 컨슈머 그룹이 존재합니다.
하나는 실시간 분석을 위한 그룹이고, 다른 하나는 이력 분석을 위한 데이터 저장을 담당하는 그룹입니다.
두 그룹 모두 동일한 토픽에 멤버를 할당하고, 동일한 파티션으로부터 메시지를 소비할 수 있습니다.
이러한 구조는 리소스 최적화를 가능하게 하며, 서로의 작업을 방해하지 않고 독립적으로 기능할 수 있도록 보장합니다.
3. How are partitions assigned within Kafka consumer groups?
그룹 코디네이터(Group Coordinator)는 컨슈머 그룹 구성원 간에 파티션을 균등하게 분배하는 작업을 지원합니다.
이는 그룹 멤버십에 변화가 생길 때에도 적용됩니다.
그룹 코디네이터는 Kafka 브로커(Kafka broker) 또는 Kafka 서버의 일부입니다.
그룹 코디네이터는 그룹 메타데이터(group metadata)를 유지하고 관리하기 위해 내부 Kafka 토픽을 활용하여 파티션 할당을 수행합니다.
3.1. Group Coordinator Functions
그룹 코디네이터는 다음과 같은 기능을 수행합니다.
-파티션 할당(Assigning Partitions)
컨슈머가 그룹에 가입하거나 그룹을 떠날 때, 그룹 코디네이터는 리밸런싱 알고리즘을 사용하여 남아 있는 컨슈머들 간에 파티션을 다시 할당합니다.
-하트비트 메커니즘(Heartbeat Mechanism)
그룹 코디네이터는 하트비트(heartbeat)라 불리는 주기적인 신호를 통해 컨슈머의 상태를 모니터링합니다. 컨슈머가 정기적으로 하트비트를 보내는 한, 해당 컨슈머는 정상적으로 온라인 상태로 간주됩니다.
만약 컨슈머가 지정된 타임아웃 시간 내에 하트비트를 보내지 못하면, 그룹 코디네이터는 해당 컨슈머를 비활성 상태로 표시하고 리밸런스를 트리거하여 그 컨슈머가 담당하던 파티션을 다른 활성 컨슈머들에게 재할당합니다. Kafka 컨슈머 지연(Kafka consumer lag) 관리에 대한 자세한 내용은 관련 가이드를 참고할 수 있습니다.
-메시지 소비 추적(Tracking Message Consumption)
그룹 코디네이터는 컨슈머 그룹이 소비한 메시지를 추적합니다. "컨슈머 오프셋(consumer offset)"이라는 고유 식별자가 그룹이 소비한 각 메시지를 식별합니다. 그룹 코디네이터는 이 컨슈머 오프셋을 __consumer_offsets라는 내부 토픽에 저장합니다.
컨슈머가 재시작하거나 일시적인 장애를 겪은 경우, 마지막으로 커밋된 오프셋을 그룹 코디네이터에 요청하여 그 지점부터 메시지 소비를 재개합니다. 이를 통해 컨슈머 그룹은 데이터에 대한 일관된 뷰를 유지하고 중복 메시지 처리를 방지할 수 있습니다.
3.2. Partition Assignment Strategy
그룹 코디네이터는 파티션 할당 전략(partition assignment strategy)을 사용하여 Kafka 컨슈머 그룹 내 컨슈머들에게 파티션을 할당합니다.
Kafka 아키텍처 내에서 PartitionAssignor 클래스가 이 결정자 역할을 수행합니다.
PartitionAssignor는 컨슈머들과 그들이 구독한 토픽에 대한 정보를 입력받아, 그룹 내 각 컨슈머에게 특정 파티션(메시지 조각)을 할당하는 매핑 결과를 출력합니다.
Kafka에서는 다음과 같은 파티션 할당 전략을 제공합니다.
-Range 방식
Range 파티션 할당에서는, 각 컨슈머가 구독한 토픽으로부터 연속적인 파티션들을 할당받습니다.
즉, 첫 번째 파티션은 첫 번째 컨슈머에게, 두 번째 파티션은 두 번째 컨슈머에게 순차적으로 할당되는 방식입니다.
토픽별로 파티션 수가 고르지 않을 경우 일부 컨슈머가 대기 상태가 될 수 있습니다.
예를 들어, 두 명의 컨슈머 C1과 C2가 두 개의 토픽 T1과 T2를 구독하고 있으며, 각 토픽은 두 개의 파티션을 가지고 있다고 가정해봅시다.
이 경우, C1은 두 토픽 모두에서 파티션 1을, C2는 두 토픽 모두에서 파티션 2를 할당받게 됩니다.
-Round Robin 방식
Round Robin 방식에서는, 구독된 모든 토픽의 모든 파티션을 순서대로 하나씩 컨슈머에게 할당합니다.
이 방식은 대기 상태에 있는 컨슈머 수를 줄이는 데 유리합니다.
예를 들어, 컨슈머 C1과 C2가 있고 세 개의 파티션이 존재한다고 가정하면, C1은 파티션 0을, C2는 파티션 1을 할당받고, 마지막 남은 파티션은 다시 C1에게 할당되어 라운드 로빈 순환이 반복됩니다.

4. Creating Kafka Consumer Groups
다음 코드 스니펫은 KafkaConsumer를 생성하고, group.id Kafka 프로퍼티를 사용하여 컨슈머 그룹을 지정하는 방법을 보여줍니다.
Properties props = new Properties();
props.put("bootstrap.servers", "broker1:9092,broker2:9092");
props.put("group.id", "CountryCounter");
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
위 코드에서 사용된 프로퍼티들의 목적은 다음과 같습니다.
bootstrap.servers — 시작 시 연결할 하나 이상의 Kafka 브로커를 지정합니다.
group.id — 컨슈머 그룹에 가입할 때 사용되는 이름입니다.
key.deserializer — 메시지 키를 역직렬화(deserialization)하는 데 필요합니다.
value.deserializer — 메시지 값을 역직렬화하는 데 필요합니다.
4.1. Best Practices with Kafka Consumer Groups
컨슈머는 항상 자신이 효율적으로 처리할 수 있는 만큼만 메시지를 소비해야 합니다.
소비한 양이 컨슈머가 처리할 수 있는 범위를 초과하면, 컨슈머는 멈추게 되고 이후 컨슈머 그룹에서 제거됩니다.
이러한 이유로, 고정 크기 버퍼(fixed-size buffers)에 메시지를 소비하는 것이 중요합니다.
추가적인 팁:
-분산된 컨슈머 그룹(distributed consumer groups)을 사용하여 수평적 확장성(horizontal scalability)과 장애 복원력(resilience to faults)을 확보하세요.
-Kafka의 통합 메트릭스(integrated metrics)나 외부 모니터링 도구를 사용하여 컨슈머 그룹의 성능을 지속적으로 모니터링하세요.
-토픽당 하나의 컨슈머 그룹만 유지하여 컨슈머 그룹 멤버십 간 충돌을 방지하세요.
만약 하나의 토픽에서 메시지를 소비하는 여러 개의 컨슈머 그룹을 만들고 싶다면 아래와 같이 합니다.
-Kafka에서는 컨슈머 그룹이 단순히 group.id로 정의됩니다.
-두 컨슈머가 서로 다른 group.id를 가지고 있다면, 서로 다른 그룹에 속하게 됩니다.
각 컨슈머 그룹은 토픽을 독립적으로 읽습니다.
서로 간섭하지 않습니다.
각 그룹은 자신만의 메시지 사본을 받습니다.
예를 들어, user-events라는 토픽이 있다고 가정해봅시다.
이제 다음과 같은 컨슈머 그룹을 구성하고자 합니다:
그룹 A: analytics-group
그룹 B: billing-group
컨슈머를 다음과 같이 설정합니다:
# Consumer for Group A
consumerA = KafkaConsumer(
'user-events',
bootstrap_servers='your.kafka.server:9092',
group_id='analytics-group'
)
# Consumer for Group B
consumerB = KafkaConsumer(
'user-events',
bootstrap_servers='your.kafka.server:9092',
group_id='billing-group'
)
이제:
analytics-group은 user-events 토픽의 모든 메시지를 독립적으로 소비합니다.
billing-group도 user-events 토픽의 모든 메시지를 독립적으로 소비합니다.
이 두 그룹은 서로에게 영향을 주지 않습니다.
'데이터 엔지니어링 정복 > Kafka' 카테고리의 다른 글
| [Kafka] 5. Cluster (2) | 2025.04.29 |
|---|---|
| [Kafka] 4. Broker (0) | 2025.04.29 |
| [Kafka] 2. Kafka Producer (2) | 2025.04.28 |
| [Kafka] 1. Kafka Architecture (2) | 2025.04.27 |
| [Kafka] Kafka Topic, Producer, Consumer 생성하기 (0) | 2021.05.07 |



