
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 여행
- pyspark
- Data Engineer
- 영어
- Spark
- 맛집
- Trino
- bigdata engineer
- BigData
- HIVE
- Data Engineering
- Linux
- 알고리즘
- 용인맛집
- 코테
- 백준
- Iceberg
- hadoop
- apache iceberg
- 삼성역맛집
- Kafka
- HDFS
- 코딩
- 프로그래머스
- java
- 코딩테스트
- 코엑스맛집
- 자바
- bigdata engineering
- Apache Kafka
- Today
- Total
지구정복
[Kafka] 1. Kafka Architecture 본문
해당 글 번역
https://www.redpanda.com/guides/kafka-architecture
1. Kafka Architecture
카프카는 분산된 이벤트 처리 플랫폼이다.
카프카는 메시지의 순서, 메시지 손실 제로, 정확히 한번 처리 등을 보장하는 시스템이다.
이제 카프카의 기본 요소들에 대해서 알아본다.
2. Summary of Key Kafka Architecture Concepts
|
Component
|
Description |
| Kafka | 분산 메시지 처리 시스템 |
| Event | 카프카로 들어오는 데이터 혹은 카프카가 작성한 데이터를 의미(=message, =data) |
| Broker | 데이터(Event)를 받는 카프카 서버이며 브로커들이 모여서 하나의 카프카 시스템을 구성한다. 즉, 카프카를 구성하는 서버 |
| Producer | 카프카 토픽에 데이터를 넣는 주체(외부 어플리케이션이 될 수도 있고, 서비스들이 될 수도 있음) |
| Topic | 데이터(Event)들이 모이는 곳 |
| Partition | 토픽에 속하는 데이터들을 특정 기준으로 나눠서 저장될 때 사용되는 개념. 즉, 토픽의 부분집합. 토픽의 파티션에 이벤트가 저장될 때 순서가 보장된다. 이 순서를 message offset이라고 하고 고유한 offset number 를 가진다. 새로운 메시지가 들어오면 카프카는 토픽의 어느 파티션에 저장할 지 결정한다. 파티션에는 오로지 append-only만 가능하다. 기본적으로 하나의 토픽에는 적어도 하나의 파티션이 존재한다. |
| Consumer | 토픽에 쌓인 data(=message)를 소비하는 외부 어플리케이션 |
| Consumer group | Logical groupings of consumers subscribing to the same topic, sharing processing load. 같은 토픽에서 data를 가져가는 consumer들의 집합이고, 처리되는 과정을 공유한다. 그래서 만약 하나의 consumer가 실패하면 consumer group에 있는 다른 consumer가 이를 대신해서 처리한다. 여러 consumer는 하나의 topic의 각각 다른 partition으로부터 데이터를 소비한다. topic에 하나의 partition만 있을 경우 consumer도 하나만 올 수 있다. partition >= consumer 즉, consumer는 partition개수를 넘을 수 없다. 반대로 partition이 여러 개고 consumer 수가 적으면 consumer들은 여러 개의 partition으로부터 데이터를 소비한다. 여러 consumer group이 하나의 topic으로부터 데이터를 소비할 수 있다. 각 consumer group은 서로에게 독립적이다. |
| Zookeeper | kafka시스템에서 leader broker를 선출하거나 offset을 정하는 일, broker 상태를 확인 등의 역할을 하는 중요한 컴포넌트이다. |
아래 아키텍처 그림을 참고한다.
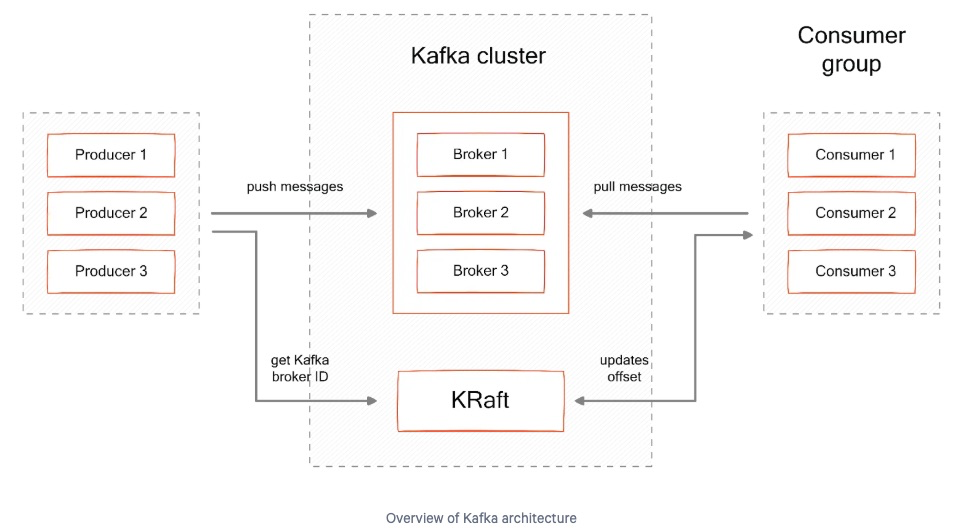
3. Kafka Architecture Components
3.1. Broker
카프카를 구성하는 하나의 서버를 하나의 broker server라고 한다.
각 broker server는 producer로부터 message를 받거나, 각 message에 offset을 할당, message를 disk storage에 쓰기 작업을 담당한다.
broker server의 하드웨어 스펙에 따라 다르겠지만 보통 하나의 broker server는 수 천개의 파티션들이나 몇 백만개의 message들을 초당 처리할 수 있다.

3.2. Message
Message(=event)는 외부에서 카프카에 데이터가 쓰여지거나 카프카가 외부에 쓰는 데이터들을 의미한다.
각 message들은 key-value 쌍을 가진다.
이 message들은 disk에 쓰여지기 전에 byte 배열로 직렬화된다.
* keys
keys는 토픽에서 올바른 partition으로 저장되기 위해 사용된다.
키는 보통 특정 시스템의 데이터를 가리키는 고유값(user id, order, device id)이 되고, string이거나 integer타입이다.
그러나 모든 message들은 모두 고유한 키를 가질 필요는 없다. 키는 null값이 되기도 한다.
null일 경우 partition에는 랜덤으로 들어가서 저장된다.
* values
message의 value에는 그 message의 상세정보를 가지고 있다.
기본적으로 언제 해당 message가 만들어졌는지에 대한 타임스탬프 정보를 가지고 있다.
그리고 optional로 headers, key-value에 대한 metadata 등에 대한 정보도 가지고 있을 수 있다.
3.3. Topic
kakfa로 들어오는 모든 message들은 topic안에 저장된다.
토픽은 event log라 불리는 순서를 가진 시퀀스라고 생각하면 된다.
다른 종류의 event들을 다른 topic에 저장할 수 있다.
외부 어플리케이션은 하나의 토픽에 데이터를 읽거나 필터링, transform(변환)할 수 있고,
다른 토픽에 데이터를 쓸 수 있다.
그리고 토픽은 오로지 append만 가능하다.
그리고 토픽은 immutable하여 한 번 topic에 데이터가 쓰여지면 변경될 수 없다.
토픽에 message가 들어가면 log의 마지막에 append된다.

메시징 큐(Messaging queues)와 달리 토픽에서 데이터를 읽는다고 해서 토픽의 데이터가 삭제되진 않는다.
따라서 message들은 여러 개의 외부 애플리케이션들에 의해 여러 번 읽힐 수 있다.
기본적으로 토픽에 쌓인 메시지들은 7일간 브로커 서버들의 디스크에 저장되어 있다.
이 기간은 설정값으로 변경가능하다.
3.4. Partition
토픽은 partitions들로 이루어져 있다.
하나의 파티션은 하나의 로그라고 생각하면 된다.
그리고 Message(데이터)는 이 로그에 append되면서 쓰여진다.
그리고 처음 쓰여진 순서대로 읽힌다.
토픽이 생성될 때 몇 개의 파티션을 가질 지 정할 수 있다.
새로운 Message가 토픽에 들어오면 어느 파티션에 쓰여질지 정해진다.

각 파티션은 다른 브로커 서버에 위치하고 있다. 이 말은 즉슨 하나의 토픽은 수평적으로 확장될 수 있기 때문에 성능상에 이점이 있다.
추가적으로 파티션은 다른 서버들에 복제되어서 특정 브로커 서버가 문제있을 때 대신 사용된다.
3.5. Partition Offset
각 파티션에 append되는 message들은 순차적으로 증가하는 Integer값인 Offset을 가진다.
Offset은 0부터 1씩 증가되며 Message들에 부여된다.
따라서 파티션에 쓰여진 message들은 offset이란 고유한 번호를 가진다.
만약 key값이 없는 Message의 경우 라운드로빈 방식으로 파티션들에게 고르게 분배된다.
partition0 -> partitoin1 -> partition2 -> ...
이는 모든 파티션들이 균등하게 message들을 받게된다.
Key는 해싱함수를 통해 처리되어서 정수로 변환된다.
이 결과는 파티션을 선택될 때 사용된다.
그래서 같은 key를 가지는 message들은 언제나 같은 파티션에 같은 순서로 보내진다.
따라서 카프카에서는 하나의 파티션 내에서 message들의 순서를 보장하지만 다른 파티션들에 저장된 Message들 간에는 순서가 보장되지 않는다.
또한 오래된 message가 지워졌다고 해도 Offset은 재사용되지 않는다.
offset은 계속 순차적으로 증가한다.
파티션에서 데이터가 읽히면 존재하는 offset중에서 가장 낮은 offset부터 순차적으로 읽힌다.
3.6. Partition Replication - Leaders and Followers
카프카 토픽들은 브로커 서버들에 저장된다.
하나의 브로커는 하나의 토픽 파티션을 가지고 있다.
이러한 브로커를 Partition의 Leader라고 부른다.
토픽은 replication factor라는 설정을 가지고 이는 1보다 항상 커야한다.
토픽 내 파티션에 있는 데이터가 몇 개의 브로커에 복제되어야 하는지를 결정한다.
복제된 파티션은 다른 브로커 서버에 할당되는데 이렇게 복제된 파티션을 가지고 있는 브로커를 Partition의 Follower라고 한다.
이러한 복제 파티션은 파티션 내의 메시지의 복제를 제공하여 Follower는 다른 Follower나 Leader가 고장났을 때 이를 대비해준다.
아래 그림에서 Partition 0의 Leader는 Broker server1에 있고 이의 Follower들은 Broker2, Broker3에 있는 것을 확인할 수 있다.

4. Reading from and Writing Data to the Kafka Architecture
4.1. Producers
프로듀서는 카프카 토픽에 메시지를 쓰는 주체이다.
프로듀서는 카프카 클라이언트 라이브러리를 사용하여 메시지를 작성한다.
프로듀서는 key-value 쌍을 가지는 데이터를 만들어서 이를 이진형식으로 직렬화하고 카프카 토픽에 메시지로 작성한다.
4.2. Consumers
컨슈머는 카프카 토픽에 있는 메시지를 읽는(=소비하는) 주체이다.
컨슈머는 하나 이상의 토픽의 메시지를 읽고 이때 토픽의 각 파티션에 쓰여진 순서대로 메시지를 읽는다.
메시지 읽는 방식은 Polling 방식이며 이는 컨슈머가 특정 주기마다 데이터 전송을 요청한다.
메시지들은 파티션 내에서 순서대로 읽힌다.
만약 컨슈머가 동일한 토픽의 여러 파티션에서 데이터를 읽는다고 가정해보자.
이럴 경우 여러 파티션에 저장된 메시지의 순서는 보장되지 않는다.
예를 들어 컨슈머가 partition 0에서 메시지를 읽고 그 다음 partition 2 그리고 partition 1 그리고 다시 Partition 0에서 읽는다고 가정해보자.
맨 처음 partition 0에서 읽었던 메시지들은 순서가 보장되지만 그 이후 partition2, partition1에서 읽은 메시지들은 읽었기 때문에 다시 partition 0을 읽었을 때는 순서가 보장되지 않는다.
컨슈머는 메시지들의 Offset을 추적하면서 이미 읽힌 message들을 추적한다.
따라서 각 파티션에 다음으로 읽혀야 할 Offset값을 저장하면서 컨슈머는 어느 지점부터 메시지를 읽으면 되는지 알 수 있다.
그리고 컨슈머가 메시지를 읽는다고해서 메시지는 삭제되지 않는다.
메시지는 여전히 다른 컨슈머에서 읽힐 수 있기 때문에 유지된다.
모든 프로듀서는 메시지를 작성하기 위해 Leader partition에 연결되지만 컨슈머는 leader 또는 Follower 한 군데에 연결해서 메시지를 가져올 수 있다.
4.3. Consumer Groups
하나의 컨슈머를 가지면 생기는 문제는 만약 파티션의 개수를 늘리고 더 많은 메시지가 쓰여지면(produced) 컨슈머는 너무 많은 메시지에 압도되고 처리 능력이 떨어진다.
이러한 이슈를 해결하기 위해 컨슈머는 하나의 그룹에 속하는 부분으로서 동작한다.
하나의 컨슈머 그룹에는 여러 개의 컨슈머가 있고, 이러한 여러 개의 컨슈머는 하나의 토픽으로부터 메시지를 같이 읽는다.
이러한 방법은 토픽의 파티션이 늘어남에 따라 컨슈머를 수평적으로 확장할 수 있다.
만약 컨슈머 중 하나가 고장나면 컨슈머 그룹의 다른 컨슈머가 이를 대체한다.

토픽의 파티션 개수는 컨슈머 그룹의 컨슈머 개수를 정하는데 도움을 준다.
만약 다섯 개의 파티션을 가지는 토픽이 있는 경우 컨슈머 그룹에는 컨슈머를 최대 다섯 개까지 생성할 수 있다.
만약 그 이상을 만들면 나머지 컨슈머는 그냥 가만히 있는다.
컨슈머를 컨슈머 그룹에 추가할 때 카프카는 리밸런싱 과정을 거쳐 자동적으로 파티션을 컨슈머들에게 재분배한다.
각 파티션은 오로지 하나의 컨슈머와 매칭된다.
그러나 하나의 컨슈머는 여러 개의 파티션에서 메시지를 읽는다.
또한 다른 컨슈머 그룹끼리는 같은 토픽에서 메시지를 읽을 수 있다.
4.4. Example
프로듀서는 컨슈머와 분리되어 있다.
이들의 속도는 서로에게 영향을 끼치지 않는다.
아래는 간단한 프로듀서와 컨슈머가 토픽에 메시지를 쓰고 읽는 자바를 사용한 카프카 예제이다.
-Producer
import java.util.Properties;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.KafkaProducer;
public class TestProducer {
public static void main(String[] args) {
// Producer configuration
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// Create producer
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// Define topic and data
String topic = "test-topic";
String data = "Simple string message from the producer!";
// Send message
producer.send(new ProducerRecord<>(topic, data));
// Flush data
producer.flush();
// Close producer
producer.close();
}
}
-Consumer
import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
public class TestConsumer {
public static void main(String[] args) {
// Consumer configuration
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// Create consumer
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// Subscribe to topic
consumer.subscribe(Arrays.asList("test-topic"));
// Continuously poll for messages
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Received message: key = %s, value = %s\n", record.key(), record.value());
}
}
// Close consumer
consumer.close();
}
}
4.5. Schema Registry
스키마 레지스트리는 중앙에서 토픽의 메시지의 스키마를 관리하고 검증하는 레포지토리이다.
또한 메시지를 직렬화, 역직렬화하는 기능도 제공한다.
한번 메시지의 스키마가 스키마 레지스트리에 등록되면 스키마는 다른 시스템들이나 애플리케이션에 공유되고 재사용된다.
애플리케이션이 브로커에게 메시지를 보내면 데이터의 스키마는 메시지 헤더에 포함된다.
스키마 레지스트리는 그 스키마가 토픽에 있는 예상되는 스키마와 비교해서 유효한지 그리고 호환되는지를 확인한다.
즉, schema registry는 토픽 메시지의 스키마를 관리하여 프로듀서가 제공하는 메시지와 컨슈머가 읽는 데이터의 일관성있는 스키마를 유지시키게 해준다.
스키마 레지스트리는 대표적으로 다음과 같은 기능을 제공한다.
-프로듀서와 컨슈머가 데이터의 스키마를 정확히 일치시킬 수 있도록 도와준다.
-스키마 변경시 명확한 호환성 규칙을 통해 스키마 진화(변화)를 관리한다.
-전체 스키마 정의를 전달하는 대신 스키마ID를 전달하여 전송 간 부하를 최적화한다.

만약 Schema registry가 없을 경우 프로듀서에서 제공하는 메시지의 스키마 변화가 있을 때 컨슈머 기존과 다른 스키마의 메시지가 넘어와서 문제를 일으킬 수 있다.
따라서 Schema Registry에 스키마 정보를 저장해두고 프로듀서에서 제공되는 스키마 변화가 바뀌더라도 schema registry에 저장되어있는 스키마로만 컨슈머에서 처리되도록 한다.
4.6. Zookeeper
주키퍼는 설정 정보들을 유지, 네이밍, 분산환경에서 동기화를 제공, 그룹핑 등의 기능을 제공한다.
카프카는 주키퍼를 브로커 서버들의 클러스터링에 활용한다.
또한 주키퍼는 다음의 내용들을 추적한다.
-어느 브로커 서버가 카프카 클러스터에 포함되는지
-어느 브로커 서버가 특정 파티션의 Leader인지
-토픽이 어떻게 설정되어 있는지(파티션 개수, 컨슈머 그룹의 위치 등)
-토픽에 메시지를 쓰거나 읽을 수 있는지 권한관리
최근에는 주키퍼없이 카프카의 자체 클러스터링 도구를 사용하기도 한다.
그러나 운영환경에서는 여전히 주키퍼를 주로 사용한다.
5. Security in Kafka Architecture
카프카는 SASL(Simple Authentication and Security Layer)프레임워크를 통해 인증과 보안 서비스를 제공한다.
이는 프로듀서나 컨슈머가 카프카 클러스터에 접근할 때 인증을 확인한다.
이를 통해 오로지 인증된 유저나 애플리케이션만 카프카에 연결이 가능하다.
SASL은 암호화와 데이터 무결성을 통해 카프카 브로커와 클라이언트 간에 안전한 통신을 가능하게 한다.
카프카는 또한 ACLs(Access Control Lists)와 인터페이스들을 통해 객체나 오퍼레이션에 대한 세부적인 접근 제어할 수 있다.
ACLs는 Security layer와 함께 특정 데이터나 특정 오퍼레이션을 실행 권한이 있는 사용자들이 데이터에 접근할 수 있도록 도와준다.
이러한 ACLs는 다음과 같은 상황에서 사용된다.
-오로지 특정 유저나 애플리케이션한 특정 토픽에 message를 produce하거나 consume하도록 할 때
-허가되지 않은 유저나 애플리케이션은 새로운 토픽을 만들거나 삭제할 수 없도록 할 때
-오로지 권한이 있는 유저나 애플리케이션에서 토픽 리스트를 확인하거나 consumer group 을 확인하고 싶을 때
6. Kafka In the Real World
카프카는 여러 시스템들 간에 데이터를 효율적으로 주고받을 수 있도록 해주었다.
아래는 쓰임의 예시이다.

-User Activity Tracking
-Log Aggregation
-Metrics Collection
-Commit log
-Stream Processing
'데이터 엔지니어링 정복 > Kafka' 카테고리의 다른 글
| [Kafka] 5. Cluster (2) | 2025.04.29 |
|---|---|
| [Kafka] 4. Broker (0) | 2025.04.29 |
| [Kafka] 3. Consumer Group (0) | 2025.04.28 |
| [Kafka] 2. Kafka Producer (2) | 2025.04.28 |
| [Kafka] Kafka Topic, Producer, Consumer 생성하기 (0) | 2021.05.07 |



