
- 지구정복과정 (538)

- 데이터 엔지니어링 정복 (434)
- Elastic Stack (2)
- Hadoop Ecosystem (27)
- HTML-CSS-JavaScript-Spring-.. (43)
- JAVA & JSP (46)
- Python (29)
- SQL (14)
- Cloud(AWS, Ncloud) (9)
- Docker&Kubernetes (2)
- Linux (12)
- Git-GitHub (9)
- Algorithm (159)
- HDFS (6)
- Iceberg (9)
- Hive (5)
- Hue (1)
- Yarn (1)
- Spark (10)
- MapReduce (2)
- Airflow (3)
- Sqoop (2)
- Tez (0)
- Trino (3)
- Kafka (12)
- Zookeeper (2)
- Flume (2)
- Oozie (1)
- Hbase (3)
- Ranger (1)
- OpenSearch (1)
- Ansible & AWX (2)
- AD & LDAP (0)
- NiFi (3)
- Ambari (2)
- Infra Solr (2)
- SuperSet (1)
- DataBricks (3)
- 데이터 애널리틱스 정복 (3)
- 프로젝트 (5)
- 자격증 정복 (35)
- 영어 정복 (7)
- 건강 정복 (5)
- 주식 정복 (가능 ?) (0)
- 이것저것 (38)
- 데이터 엔지니어링 정복 (434)
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
- 용인맛집
- 여행
- Data Engineer
- bigdata engineer
- Data Engineering
- hadoop
- pyspark
- 알고리즘
- 백준
- apache iceberg
- 코테
- Kafka
- BigData
- java
- 코엑스맛집
- bigdata engineering
- 맛집
- Trino
- Iceberg
- 자바
- 삼성역맛집
- Spark
- 개발
- Apache Kafka
- 영어
- 코딩
- Linux
- 코딩테스트
- HIVE
- 프로그래머스
- Today
- Total
지구정복
[Kafka] 5. Cluster 본문
1. Kafka Cluster
Kafka 클러스터는 서로 연결된 Kafka 브로커들의 집합으로, Kafka 시스템으로 들어오고 나가는 데이터 스트림을 함께 관리합니다.
각 브로커는 별도의 머신에서 독립적인 프로세스로 실행되며, 신뢰성 높고 고속인 네트워크를 통해 다른 브로커들과 통신합니다.
그렇다면 왜 Apache Kafka 클러스터를 사용해야 할까요? 그리고 그것이 어떻게 도움이 될까요?
사용자 활동이 증가함에 따라, 들어오는 데이터 스트림의 양과 속도를 감당하기 위해 추가적인 Kafka 브로커가 필요하게 됩니다.
Kafka 클러스터는 데이터 파티션을 여러 브로커에 복제(replication)할 수 있게 하여, 노드 장애가 발생하더라도 고가용성(high availability)을 유지할 수 있도록 합니다.
이를 통해 데이터 파이프라인은 탄력적으로 수요 변동에 대응할 수 있으며, 안정적이고 빠르게 동작할 수 있습니다.
2. Kafka Cluster Architecture
Kafka 클러스터의 핵심에는 브로커(broker)가 있습니다. 브로커는 데이터 스트림을 저장하고 관리하는 기본 단위입니다.
각 브로커는 특정 데이터 파티션을 수신하여 저장하고, 요청이 있을 때 이를 제공합니다.
데이터 파티션은 적절한 분산을 보장하고 중복 가능성을 줄이는 역할을 합니다.
또한, 데이터가 증가함에 따라 브로커를 추가함으로써 확장성(scalability)도 손쉽게 확보할 수 있습니다.
Kafka 클러스터 운영에 있어 또 하나의 핵심 요소는 메타데이터(metadata)입니다.
메타데이터는 토픽, 브로커, 파티션, 컨슈머 그룹 및 이들 간의 통신 정보를 담고 있으며,
Kafka가 데이터 스트림의 분산, 복제, 소비에 대해 효과적인 결정을 내릴 수 있도록 합니다.
기존에는 이 메타데이터가 별도로 저장되었지만, Apache Kafka Raft (KRaft)는 대안적인 접근 방식을 제시합니다.
KRaft는 메타데이터 조정 기능을 Kafka 브로커에 직접 통합함으로써, 별도의 ZooKeeper 클러스터가 필요 없게 만듭니다.
이를 통해 조직은 아키텍처를 단순화하고, 운영 부담을 줄이며, 더 높은 효율성을 달성할 수 있습니다.
Kafka 클러스터 아키텍처에는 두 가지 주요 유형이 있습니다.
이제 각 유형을 개별적으로 설명하고, 그에 따른 과제와 장점을 함께 살펴보겠습니다.

2.1. Single Kafka Cluster
이름에서 알 수 있듯이, 이것은 중앙 집중식 관리가 이루어지는 단일 Kafka 클러스터입니다.
단일 Kafka 클러스터는 단순한 Kafka 설정과 동일한 구성 요소와 원칙을 기반으로 동작하며, 기반 인프라도 동일합니다.
위의 다이어그램에 나타난 바와 같이, 단일 Kafka 클러스터는 모든 구성 요소를 하나의 단위로 배포할 수 있습니다. 이 구성 요소에는 다음이 포함됩니다:
-데이터를 저장하고 제공하는 모든 브로커들
-Zookeeper or KRaft 프로토콜을 통한 전체 메타데이터 관리
-브로커들 간에 파티셔닝되고 복제된 토픽들
클라이언트 애플리케이션은 이러한 브로커들과 직접 상호작용하여 메시지를 생산(produce)하거나 소비(consume) 할 수 있습니다.
2.2. Multiple Kafka Cluster
다중 Kafka 클러스터 구성(multiple Kafka cluster setup)은 분산형 접근 방식으로, 서로 다른 워크로드를 처리하기 위해 별도의 클러스터들을 운영합니다.
이렇게 워크로드를 분리하면 리소스 간 간섭이 줄어들고, 교착 상태(deadlock)가 완화됩니다.
또한, 각 Kafka 클러스터는 워크로드 요구에 따라 독립적으로 확장할 수 있습니다.
다중 Kafka 클러스터 배포에는 여러 가지 모델이 존재합니다:
-Stretched Cluster (확장형 클러스터)
확장형 클러스터는 여러 지리적 위치에 걸쳐 있는 단일 논리 클러스터입니다.
개발자들은 클러스터의 복제본을 데이터 센터 간에 균등하게 분산시켜, 장애 발생 시에도 높은 중복성(redundancy)과 내결함성(fault tolerance)을 확보합니다.
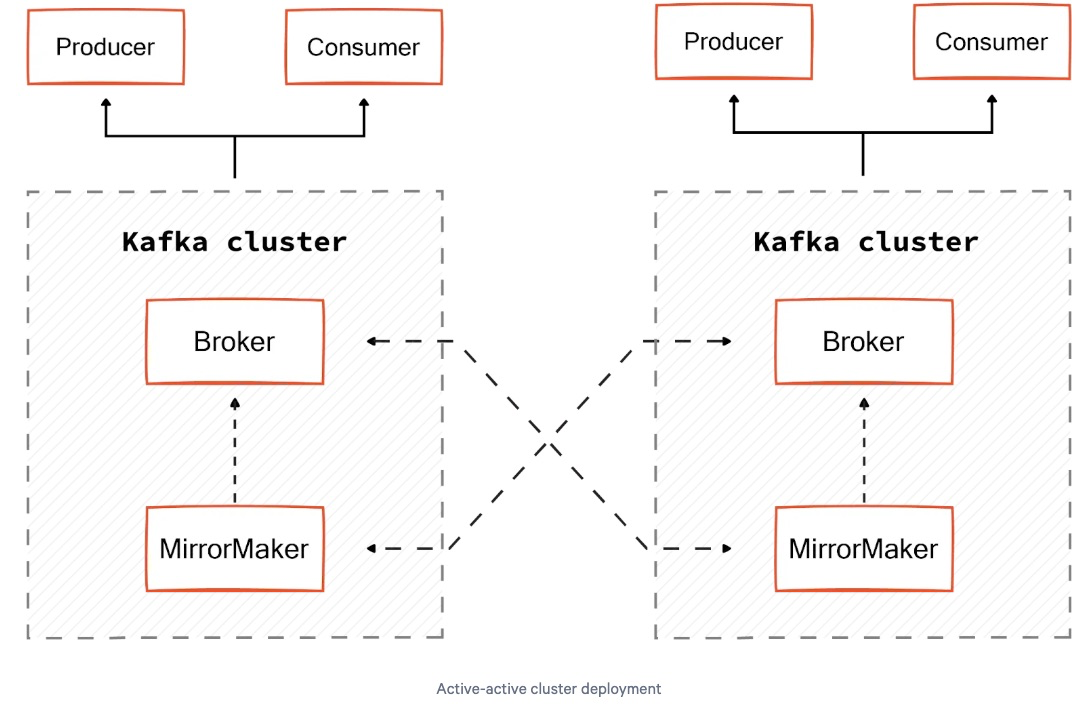
-Active-Active Cluster (활성-활성 클러스터)
가장 선호되는 모델로, 두 개의 동일한 클러스터가 양방향 비동기 미러링을 수행합니다.
이 미러링은 MirrorMaker를 통해 설정되며, Kafka 컨슈머가 소스 클러스터에서 메시지를 읽고, 이를 내장 Kafka 프로듀서를 통해 타겟 클러스터에 재전송합니다.
이 모델의 가장 큰 장점은 클라이언트 애플리케이션이 미러링 완료를 기다리지 않아도 된다는 점입니다.
각 클러스터에는 별도의 Kafka 프로듀서 및 컨슈머가 존재하지만, 미러링 덕분에 양쪽 클러스터 모두 동일한 데이터를 보유하게 됩니다.
-Active-Passive Cluster (활성-수동 클러스터)
이 모델에서는 두 클러스터 간에 단방향 미러링이 이뤄집니다.
즉, 데이터는 활성 클러스터에서 수동 클러스터로만 복제됩니다.
활성 클러스터에 장애가 발생하면, 클라이언트 애플리케이션은 수동 클러스터로 전환해야 합니다.
그러나 복제 지연(replication lag)이 클 경우, 수동 클러스터는 몇 개의 오프셋(offset)만큼 뒤처질 수 있습니다.
이로 인해, 활성 클러스터가 다운되면 일시적인 데이터 불일치가 발생할 수 있으며, 이것이 이 모델의 단점이 될 수 있습니다.
3. Choosing the Right Kafka Cluster Architectures
단일 Kafka 클러스터 아키텍처와 다중 Kafka 클러스터 아키텍처 중 선택은 조직의 필요에 따라 달라집니다.
-설정 복잡도 (Setup Complexity)
단일 클러스터 아키텍처는 데이터 관리를 간소화합니다.
들어오고 나가는 모든 데이터를 위한 중앙 허브 역할을 하여 데이터 아키텍처의 복잡성을 줄입니다.
복잡한 프로세스가 줄어들고 구성(configuration)도 단순해져서, 배포(deployment) 속도가 빨라집니다.
또한, 새로 합류한 팀원들이 더 쉽게 배우고 적용할 수 있습니다.
반면, 다중 Kafka 클러스터는 설정, 구성, 유지 관리 측면에서 복잡성이 증가할 수 있습니다.
이는 클러스터 간 미러링 및 통신 오버헤드가 추가되기 때문입니다.
-장애 허용성 (Fault Tolerance)
단일 Kafka 클러스터에서는 장애가 전체 시스템에 전파될 수 있으며, 데이터 가용성(data availability)이 영향을 받습니다.
또한, 장애를 식별하고 격리하는 것이 어려워, 장기적인 다운타임으로 이어질 수 있습니다.
반면, 다중 클러스터 배포는 데이터 스트림을 격리하여 장애 허용성을 향상시킵니다.
한 클러스터의 장애가 다른 클러스터에 영향을 미치지 않으며,
다수 클러스터 간 복제를 통해 데이터 손실 방지도 가능합니다.
또한, 다중 Kafka 클러스터를 위한 자동 장애 조치(failover) 메커니즘을 통해, 장애 발생 시 데이터 스트림을 정상 노드로 재라우팅할 수 있습니다.
(이는 이후 섹션에서 더 자세히 설명할 예정입니다.)
-확장성과 성능 (Scalability and Performance)
단일 Kafka 클러스터는 워크로드 분리가 없어 성능 병목(bottleneck)을 겪을 수 있습니다.
모든 데이터 스트림이 공유 리소스를 놓고 경쟁하게 되어, 교착 상태(deadlock)가 발생할 위험이 있습니다.
또한, 하드웨어 한계로 인해 확장성에도 제약이 발생하며, 이를 넘어서려면 대규모 업그레이드가 필요해 추가 확장이 어려워질 수 있습니다.
반대로, 데이터 스트림을 여러 Kafka 클러스터로 분리하면 워크로드 격리 효과를 얻을 수 있습니다.
특정 사용 사례에 맞게 리소스와 구성을 맞춤화할 수 있으며, 리소스 간 간섭을 줄여 전반적인 성능과 신뢰성이 향상됩니다.
조직은 각 클러스터를 개별 워크로드 요구사항에 맞춰 독립적으로 확장할 수 있어, 정밀한 리소스 할당과 최적화가 가능합니다.
-무결성 (Integrity)
장애 허용성과 확장성을 확보하는 것만큼이나, 데이터 무결성(data integrity)을 유지하는 것도 중요합니다.
다중 클러스터 환경에서는 복제(replication) 과정에서 일관성(consistency) 및 동기화(synchronization) 문제가 발생할 수 있습니다.
특히 복제 지연(replication lag)이 클 경우, 수동(passive) 클러스터는 활성(active) 클러스터보다 몇 개의 오프셋(offset)이 뒤처질 수 있습니다.
또한, 미러링 과정에서 발생하는 작은 실수가 전체 시스템의 데이터 무결성과 일관성을 위협할 수 있습니다.
단일 클러스터에서는 이러한 문제가 발생하지 않습니다.
-비용 (Cost)
다중 클러스터에서는 리소스 중복과 오버헤드로 인해, 운영비, 인프라비, 소프트웨어 라이선스비 등의 비용이 증가합니다.
반면, 복잡하지 않은 데이터 스트리밍 요구사항에는 단순한 단일 아키텍처가 더 효율적입니다.
가용 리소스를 효율적으로 사용함으로써 인프라 비용을 최적화하고, 운영 비용도 절감할 수 있습니다.
4. Deployment and Setup of Kafka Cluster
Kafka 클러스터를 배포하고 설정하며 관리하는 일은, 클러스터를 원활하게 구동시키고 지속적으로 효과적으로 운영되도록 만드는 작업입니다.
이는 실시간 데이터 스트림을 처리할 수 있는 강력한 기반을 구축하고 유지하는 것과 같습니다.
이제 이 개념들을 하나씩 살펴보겠습니다.
4.1. Comparing Kafka Cluster Deployment Environments
Kafka 클러스터 배포 환경 비교 (Comparing Kafka Cluster Deployment Environments)
Kafka 클러스터를 배포하는 방법은 크게 세 가지로 나눌 수 있습니다.
-온프레미스 배포 (On-premise Deployments)
온프레미스 배포는 Kafka 클러스터를 조직의 데이터 센터 내 전용 하드웨어에 직접 호스팅하는 방식입니다.
이를 통해 조직은 하드웨어 자원, 네트워크 구성, 보안 정책을 모두 직접 통제할 수 있습니다.
또한, 특정 요구 사항에 맞춰 환경을 자유롭게 커스터마이징할 수 있습니다.
데이터 프라이버시에 대한 우려가 큰 기업이라면, 온프레미스 배포를 통해 더 높은 보안성과 통제권을 확보할 수 있습니다.
하지만, 온프레미스 배포는 하드웨어 및 인프라 구매, 유지보수, 장애 대응 등에 선투자 비용이 많이 든다는 단점이 있습니다.
-클라우드 기반 배포 (Cloud-based Deployments)
Kafka 브로커를 클라우드에 호스팅할 수도 있습니다.
클라우드 기반 배포는 **확장성(scalability)**과 **유연성(flexibility)**을 제공합니다.
필요에 따라 자원을 확장하고, 사용한 만큼만 비용을 지불할 수 있습니다.
예를 들어, Amazon MSK는 Kafka를 클라우드에서 운영하는 완전 관리형 서비스입니다.
또한, Redpanda Cloud는 서버리스 Kafka 대안으로, 운영 인프라 부담 없이 고성능, 확장 가능한 메시징을 제공합니다.
-Kubernetes 배포 (Kubernetes Deployments)
Kubernetes(K8s)를 이용하면 Kafka 클러스터를 컨테이너화된 환경에 배포할 수 있습니다.
이를 통해 리소스 활용을 최적화할 수 있으며,
하이브리드 클라우드 및 멀티 클라우드 환경에서도 관리 일관성을 유지할 수 있습니다.
4.2. Setting up a Kafka Cluster
Kafka 클러스터를 구축하기 전에 다음과 같은 사전 조건을 갖추어야 합니다:
-분산 시스템(distributed systems) 개념에 대한 기본적인 지식이 있어야 합니다.
-Unix 계열 운영체제(예: Linux, macOS)에 접근할 수 있어야 합니다.
이 가이드에서는 Python으로 코드 예시를 제공하므로, Python에 대한 기본적인 이해가 필요합니다.
Kafka 설치하기 (Install Kafka)
Kafka 최신 버전을 다운로드하고 설치해야 합니다.
설치 후에는 다운로드한 압축 파일을 해제하고, Kafka 명령어 실행을 간편하게 하기 위해 **환경 변수(environment variables)**를 설정합니다.
다음은 이를 위한 Bash 명령어입니다:
tar -xzf kafka_<version>.tgz
export KRAFT_HOME=/path/to/kafka
export PATH=$PATH:$KRAFT_HOME/bin코드 설명:
tar -xzf: 압축된 Kafka 파일을 풀어 콘텐츠를 추출합니다.
KRAFT_HOME 환경 변수를 Kafka가 설치된 경로로 설정하여, Kafka 파일 및 디렉토리에 쉽게 접근할 수 있도록 합니다.
PATH에 Kafka의 bin 디렉토리를 추가하여, 터미널 어디서나 Kafka 명령어를 전체 경로 없이 실행할 수 있게 합니다.
Kafka 환경 구성 (Configure Kafka Environment)
Kafka 환경을 시작하려면, 제공된 KRaft 구성 파일을 사용해 Kraft를 구동해야 합니다.
이후, 각 브로커에 대해 별도의 터미널을 열어 커스텀 설정으로 Kafka 브로커를 설정합니다.
다음 명령어들을 사용합니다:
kraft-server-start.sh config/kraft.properties
kraft-broker-start.sh config/broker1.properties
kraft-broker-start.sh config/broker2.properties
Kafka 클러스터 상태 확인 (Verify the Kafka Cluster)
Kafka 클러스터의 운영 상태를 확인하려면 브로커 및 토픽의 상태를 점검해야 합니다.
현재 클러스터에서 활성화된 브로커들의 ID, 호스트명, 포트 번호 등의 세부 정보를 확인할 수 있습니다.
또한, 각 브로커의 지원 API 버전 및 호환성 정보도 표시됩니다.
kafka-broker-api-versions.sh --bootstrap-server localhost:9092
현재 Kafka 클러스터에 생성되어 있는 모든 토픽 목록을 조회할 수 있습니다.
토픽 이름, 파티션 수, 복제 계수(replication factor), 커스텀 설정 등이 포함됩니다.
kafka-topics.sh --list --bootstrap-server localhost:9092
토픽 생성하기 (Create Topics)
Kafka에서는 kafka-topics.sh 유틸리티를 이용하여 데이터를 조직화할 수 있습니다.
워크로드 요구에 맞게 파티션 수와 복제 계수를 정의할 수 있습니다.
kafka-topics.sh --create --topic test_topic --bootstrap-server localhost:9092 --replication-factor 3 --partitions 3
프로듀서와 컨슈머 설정하기 (Set up Producers and Consumers)
프로듀서(Producer)를 설정하여 이벤트(메시지)를 생성하고 지정된 토픽으로 전송합니다.
여기서는 "test_topic"에 메시지를 보냅니다.
프로듀서 예시 (Python 코드):
from kafka import KafkaProducer
from time import sleep
producer = KafkaProducer(bootstrap_servers='localhost:9092')
topic = 'test_topic'
messages = ['This is message 1', 'This is message 2', 'This is message 3']
for message in messages:
producer.send(topic, value=message.encode())
sleep(1)
컨슈머 예시 (Python 코드):
컨슈머는 "test_topic"의 메시지를 수신합니다.
from kafka import KafkaConsumer
consumer = KafkaConsumer('test_topic', bootstrap_servers='localhost:9092')
for message in consumer:
print(f"Received message: {message.value.decode()}")
'데이터 엔지니어링 정복 > Kafka' 카테고리의 다른 글
| [Kafka] 7. Partition (1) | 2025.05.01 |
|---|---|
| [Kafka] 6. Topics (1) | 2025.04.30 |
| [Kafka] 4. Broker (0) | 2025.04.29 |
| [Kafka] 3. Consumer Group (0) | 2025.04.28 |
| [Kafka] 2. Kafka Producer (2) | 2025.04.28 |



