
- 지구정복과정 (519)

- 데이터 엔지니어링 정복 (417)
- Elastic Stack (2)
- Hadoop Ecosystem (27)
- HTML-CSS-JavaScript-Spring-.. (43)
- JAVA & JSP (46)
- Python (28)
- SQL (14)
- Cloud(AWS, Ncloud) (8)
- Docker&Kubernetes (2)
- Linux (11)
- Git-GitHub (9)
- Algorithm (159)
- HDFS (4)
- Iceberg (6)
- Hive (5)
- Hue (1)
- Yarn (1)
- Spark (8)
- MapReduce (2)
- Airflow (2)
- Sqoop (2)
- Tez (0)
- Trino (2)
- Kafka (12)
- Zookeeper (2)
- Flume (2)
- Oozie (1)
- Hbase (3)
- Ranger (1)
- OpenSearch (1)
- Ansible & AWX (2)
- AD & LDAP (0)
- NiFi (3)
- Ambari (1)
- Infra Solr (2)
- 데이터 애널리틱스 정복 (3)
- 프로젝트 (5)
- 자격증 정복 (33)
- 영어 정복 (7)
- 건강 정복 (5)
- 주식 정복 (가능 ?) (0)
- 이것저것 (38)
- 데이터 엔지니어링 정복 (417)
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- pyspark
- 코엑스
- 코엑스맛집
- apache iceberg
- 알고리즘
- Kafka
- 백준
- 여행
- Data Engineering
- Data Engineer
- 코딩테스트
- bigdata engineer
- HIVE
- 용인맛집
- Spark
- java
- Trino
- 자바
- hadoop
- 개발
- 코딩
- 프로그래머스
- 삼성역맛집
- 맛집
- 코테
- bigdata engineering
- Apache Kafka
- BigData
- 영어
- Iceberg
- Today
- Total
지구정복
[Kafka] 8. Offset 본문
1. What is a Kafka offset?
카프카의 운영 구조는 프로듀서, 소비자, 그리고 브로커로 구성됩니다.
프로듀서는 카프카 주제에 메시지를 생성하는 애플리케이션입니다.
카프카 브로커는 프로듀서로부터 메시지를 수신하고 이를 지속적으로 저장합니다.
소비자는 카프카 주제로부터 데이터를 읽는 애플리케이션입니다.
카프카 주제는 특정 비즈니스 목표와 관련된 데이터의 논리적인 그룹입니다. 주제는 병렬 처리를 지원하기 위해 파티션으로 나뉩니다. 카프카는 파티션 내에서 메시지를 추적하기 위해 오프셋이라는 식별자를 사용합니다.
모든 메시지는 고유한 오프셋 또는 식별값을 가집니다.
내부적으로 카프카는 메시지를 로그에 기록하며, 카프카 오프셋은 해당 파티션의 로그 내에서 메시지의 위치를 나타냅니다.
이는 메시지가 파티션 로그의 시작으로부터 얼마나 떨어져 있는지를 나타냅니다.

2. Why are Kafka offsets necessary?
여러 프로듀서는 동시에 카프카 주제에 메시지를 작성할 수 있으며, 여러 소비자는 주제에서 메시지를 병렬로 처리할 수 있습니다.
소비자 그룹은 동일한 주제로부터 데이터를 소비하는 소비자 세트를 말합니다.
카프카는 파티션이 한 번에 오직 하나의 소비자에게만 할당되도록 보장합니다.
이를 통해 카프카는 여러 소비자와 함께 단일 파티션 내에서 메시지를 공유하는 복잡성을 제거할 수 있습니다.
남아 있는 유일한 문제는 소비자들이 할당된 파티션으로부터 신뢰할 수 있는 데이터를 받도록 보장하는 것입니다.
여기서 오프셋이 중요한 역할을 합니다.
카프카는 오프셋을 사용하여 메시지를 초기 작성에서 최종 처리 완료까지 추적합니다.
오프셋 덕분에 카프카는 소비자가 프로듀서가 메시지를 작성한 동일한 순서로 메시지를 가져오도록 보장합니다.
시스템은 또한 장애로부터 원활하게 복구하고 정확한 실패 지점에서 계속 진행할 수 있습니다.
각 메시지는 고유한 오프셋을 가지고 있지만, 스트림 내의 주요 오프셋을 추적하기 위해 특정 용어가 사용됩니다.
- Log-end-offset : 카프카 파티션에 존재하는 마지막 메시지
- High watermark offset : 모든 메시지가 파티션 복제본에 동기화된 로그의 지점
- Committed offset : 소비자가 성공적으로 처리한 마지막 메시지
아래는 카프카가 오프셋을 사용하는 몇 가지 예시입니다.
2.1. Managing partition replication
메시지가 주제에 도착하면, 해당 파티션의 모든 복제본과 동기화되는 데 시간이 걸립니다.
소비자가 메시지를 가져올 때, 먼저 브로커로부터 High watermark offset을 가져오고 그 오프셋까지의 메시지만 처리하려고 합니다.
이는 카프카가 소비자가 완전히 복제된 메시지만 고려하도록 보장하는 데 도움이 됩니다.
2.2. Managing consumer failure
소비자가 두 개의 인접한 커밋 간격 사이에서 충돌하면 메시지를 잃어버릴 수 있습니다.
소비자가 커밋 간격 사이에서 메시지 세트를 처리한 직후에 실패하면 중복된 메시지를 가져올 수 있습니다.
오프셋은 카프카가 소비자의 진행 상황을 추적하는 데 사용되는 식별자를 제공합니다.
소비자가 종료되고 다시 시작할 경우, 카프카 오프셋은 소비자가 올바른 메시지에서 재개할 수 있도록 보장합니다.
2.3. Message delivery guarantees with Kafka offsets
기본적으로 카프카는 마이크로 배치의 메시지를 수집하고 주기적인 간격으로 오프셋을 커밋합니다.
이 메커니즘은 자동 커밋 전략(auto-commit strategy)이라고 합니다.
자동 커밋 모드에서는 카프카가 메시지 전달을 보장하지 않습니다.
실패 시나리오에 따라 메시지가 손실되거나 중복으로 전달될 수 있습니다.
프로듀서는 메시지를 단순히 전송하고 무시합니다.
즉, 기본적인 Auto-Commit Strategy를 사용하면 컨슈머가 메시지들을 받고나서 처리한 뒤에 Commited-offset을 설정하면 좋은데
단순히 받고나서 Commited-offset을 설정해버리기 때문에 만약 컨슈머쪽에서 메시지 처리 중에 고장이 났고 다시 처리해야된다고 했을 때는 처리중이었던 메시지들을 건너뛰어버립니다.
이는 data loss를 초래하게 됩니다.
오프셋 커밋과 관련된 설정을 조정하면 더 엄격한 메시지 전달 보장을 설정할 수 있습니다.
그러나 이는 프로듀서와 소비자의 설정 모두에 따라 달라집니다.
카프카는 세 가지 종류의 전달 보장을 지원합니다.
### 최대 한 번(at most once)
프로듀서 확인 응답 구성 매개변수 'acks'를 '1' 또는 'all'로 설정합니다.
소비자 측에서는 메시지가 도착하는 즉시 오프셋이 커밋되며, 처리 전에 커밋됩니다.
이 경우, 처리 중 소비자 실패가 발생하면 메시지가 손실될 수 있지만, 중복된 메시지는 처리되지 않습니다.
### 최소 한 번(at least once)
최소 한 번 보장은 메시지가 누락되지 않도록 보장하지만, 메시지가 중복 처리될 수 있는 가능성이 있습니다.
프로듀서 확인을 활성화하고, 메시지를 처리한 후에만 오프셋을 커밋하도록 소비자를 구현합니다.
소비자 실패는 메시지가 두 번 처리되는 결과를 초래할 수 있지만, 메시지 손실의 위험은 매우 낮습니다.
### 정확히 한 번(exactly once)
정확히 한 번 의미론은 메시지가 손실되거나 중복되지 않도록 보장합니다.
프로듀서에서 idempotence 구성을 사용하여 동일한 메시지가 두 번 파티션에 전송되지 않도록 방지합니다.
- 프로듀서에서 `enable.idempotence=true` 매개변수를 설정합니다.
- 스트림 애플리케이션에서 `processing.guarantee=exactly_once` 매개변수를 설정합니다.
이 메시지가 작성되는 시점에서, 이는 소비자의 output이 다른 원격 동기화가 아닌 카프카 주제 자체로 전송될 때만 가능합니다.
이 경우 오프셋 커밋과 소비자의 메시지 처리 작업이 단일 트랜잭션으로 발생하여, 소비자 측에서 메시지가 두 번 처리될 가능성을 제거합니다.
만약 트랜잭션이 실패하면, 모든 효과가 되돌려져 전체 작업이 원자적으로 처리됩니다.
2.4. Monitoring consumer lag
오프셋 모니터링은 카프카 클러스터의 성능 문제를 식별하는 데 도움이 됩니다.
카프카의 주요 성능 지표 중 하나는 **소비자 지연(consumer lag)**입니다.
프로듀서가 데이터를 넣는 속도가 컨슈머가 가져가는 속도보다 빠른 경우, 이때 생기는 프로듀서가 넣은 데이터의 오프셋과 컨슈머가 가져간 데이터의 오프셋의 차이 또는 토픽의 가장 최신 오프셋과 컨슈머 오프셋의 차이를 kafka consumer lag이라 부른다.
소비자 지연은 커밋된 오프셋과 로그 끝 오프셋(log-end offset) 간의 차이를 나타냅니다.
정상 작동 중에는 로그 끝 오프셋과 커밋된 오프셋 간의 간극이 최소화되는 것이 기대됩니다.
그러나 지연이 증가하면 시스템에 문제가 발생할 수 있습니다.
일례로, lag이 상승하고 있다면 아래의 이슈 중 하나에 해당할 것이므로, 정확한 원인을 파악하여 이에 대응하기 위한 모니터링 작업이 필요하다.
consumer의 성능에 비해 producer가 순간적으로 많은 record를 보내는 이슈
consumer의 polling 빈도 수가 느려지는 이슈 (polling 이후 처리 속도로 인해)
Network 지연 이슈
Kafka broker 내부 이슈
기타 이슈
### 주요 원인
- **예측 불가능한 수신 메시지 급증**:
- 가장 일반적인 소비자 지연 원인은 들어오는 메시지의 예기치 않은 급증입니다.
이로 인해 소비자가 메시지를 처리하는 속도보다 훨씬 더 빨리 메시지가 쌓이게 됩니다.
- **주제 내 파티션 간 데이터 분포 불균형**:
- 기본적으로 Kafka는 메시지 키의 해시를 기준으로 데이터를 파티션으로 나눕니다.
만약 특정 키를 커스터마이즈하고 그 키에 할당된 메시지의 양이 다른 키보다 많으면, 그 파티션을 처리하는 소비자는 높은 부하를 경험하게 되고, 이로 인해 소비자 지연이 발생합니다.
- **처리 작업의 본질적 느림**:
- 본질적으로 느린 처리 작업이나 파이프라인 구성 요소의 오류도 소비자 지연의 다른 이유가 될 수 있습니다.
이로 인해 소비자는 메시지를 처리하는 데 더 오랜 시간이 소요되므로 지연이 증가할 수 있습니다.
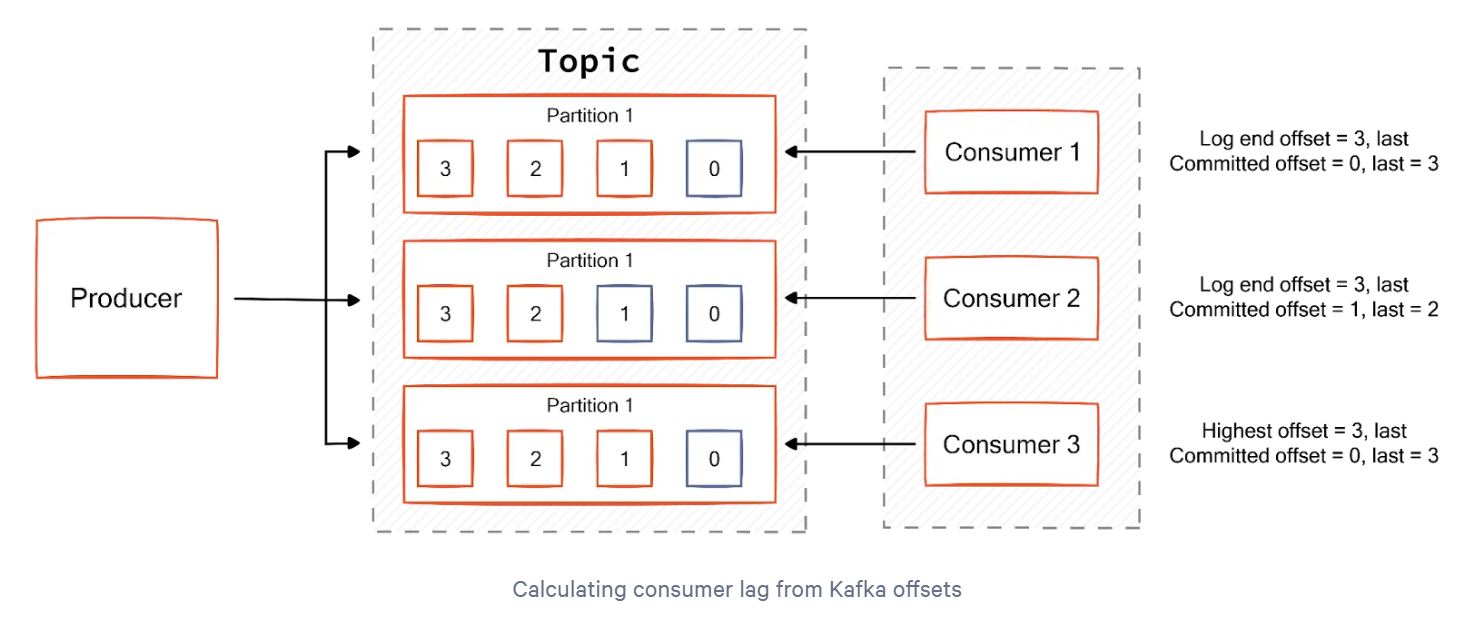
프로듀서와 컨슈머의 오프셋은 파티션을 기준으로 한 값이므로, 토픽에 여러 파티션이 존재하는 경우라면 lag은 여러 개 존재할 수 있다.
만약 컨슈머 그룹이 1개이고 파티션이 2개인 토픽에서 데이터를 가져간다면 lag는 두 개가 측정될 수 있다.
이렇게 여러 개 존재하는 lag 중에서 가장 높은 숫자를 갖는 lag을 records-lag-max라고 부른다.
주로 컨슈머의 상태를 분석할 때 사용하므로, 컨슈머 랙(consumer lag)이라고 부르기도 한다.
3. Working with Kafka offsets
카프카는 오프셋 처리 프로세스의 동작을 세밀하게 조정하고 최적의 성능을 달성할 수 있는 여러 가지 옵션을 제공합니다.
몇 가지 주요 오프셋 구성 및 사용 시기를 살펴보겠습니다.
3.1. Resetting the consumer offset
때때로 개발자는 소비자의 오프셋을 재설정하고 오프셋의 시작 또는 끝에서부터 처리를 다시 시작해야 할 필요가 있습니다.
이는 주로 소비자 로직에서 문제를 식별했을 때 발생하며, 모든 메시지에 대한 로직을 실행하여 상태를 재생성해야 할 때입니다.
이런 경우 아래 명령어가 유용합니다.
이 명령어는 모든 소비자가 아닌 특정 소비자 그룹에 적용된다는 점에 유의하시기 바랍니다.
./kafka-consumer-groups.sh --bootstrap-server localhost:9000 --group groupName --reset-offsets --to-earliest --topic topic_name-execute
또한, 현재 소비자 그룹의 이름을 변경하여 새로운 소비자 그룹을 사용하면 이 작업을 수행할 수 있습니다.
3.2. Auto offset reset configuration
이 구성은 초기 커밋된 오프셋이 없는 상태에서 소비자가 시작될 때의 동작을 정의합니다.
예를 들어, 소비자가 처음으로 시작될 때가 해당합니다.
커밋된 오프셋이 없거나, 소비자가 커밋된 오프셋 이후의 다음 오프셋을 찾을 수 없는 실패 시나리오에서도 발생할 수 있습니다.
이러한 시나리오에 대해 카프카가 반응하는 방식을 ‘auto.offset.reset’ 매개변수를 사용하여 구성할 수 있습니다.
가능한 값은 ‘earliest’, ‘latest’, 또는 ‘none’입니다.
값이 ‘earliest’로 설정되면 소비자는 해당 파티션에 존재하는 첫 번째 오프셋부터 처리를 시작합니다.
‘latest’ 값은 소비자에게 가장 최근의 사용 가능한 오프셋부터 처리를 시작하도록 지시하며,
‘none’으로 설정하면 커밋된 오프셋이 없을 경우 예외가 발생합니다.
커밋된 오프셋이 존재하면, 소비자는 이 설정의 값에 관계없이 마지막 커밋된 오프셋에서 읽습니다.
3.3. Changing automatic offset committing interval
기본적으로 카프카는 주기적인 간격에 따라 오프셋을 커밋합니다.
이 간격은 ‘auto.commit.interval.ms’ 매개변수를 사용하여 변경할 수 있습니다.
기본값은 5초입니다.
이 매개변수를 낮은 값으로 설정하면 커밋 빈도가 증가하고, 소비자가 처리 완료 이전에 커밋이 발생할 수 있는 위험이 있습니다.
이러한 경우 소비자가 실패하면 메시지가 손실될 수 있습니다.
반면에, 이 값을 높게 설정하면 소비자가 중복 메시지를 처리할 위험이 증가합니다.
3.4. Disabling automatic offset committing
자동 오프셋 커밋은 소비자들이 오프셋을 커밋하기 위한 복잡한 로직을 구현할 필요가 없게 해 줍니다.
그러나 이 전략은 메시지 손실이나 중복 메시지가 해로운 중요한 사용 사례에는 실제적이지 않습니다.
‘enable.auto.commit’ 속성을 false로 설정하면 자동 오프셋 커밋을 비활성화할 수 있습니다.
이를 통해 최대 한 번, 최소 한 번 또는 정확히 한 번 보장을 적용할 수 있는 가능성이 열립니다.
4. Best practices while configuring the Kafka offset
카프카 오프셋 구성은 처리량과 메시지 전달 보장 간의 균형을 요구합니다.
메시지 전달 보장이 증가할수록 처리량은 감소하게 됩니다.
이는 메시지 보장을 강제하기 위해 시스템에 오버헤드가 발생하기 때문입니다.
예를 들어, 전송 후 확인(acknowledgment)이나 멱등성(idempotence)을 채택하면 전송 후 잊기(fire-and-forget) 접근 방식에 비해 프로듀서의 처리량이 감소하게 됩니다.
마찬가지로, 소비자는 다양한 전략을 통해 오프셋 커밋에 대한 추가 작업을 부담하게 됩니다.
자동 커밋 전략을 사용할 때는 기본 값이나 그보다 높은 값을 사용하는 것이 좋습니다. ( auto.commit.interval.ms )
낮은 값으로 설정하면 브로커에 대해 많은 오버헤드를 발생시키고 불필요한 CPU 사용이 초래될 수 있습니다.
반대로 높은 값으로 설정하면 중복된 메시지가 발생할 위험을 감수하면서 손실된 메시지의 위험이 줄어듭니다.
카프카의 기본 자동 커밋 전략은 최종 상태만이 중요한 사용 사례에 가장 적합하며, 메시지가 시스템의 최종 상태를 나타냅니다.
이러한 경우에는 몇 개의 메시지가 손실되거나 몇 개의 중복 메시지가 발생하더라도 장기적으로 큰 문제가 되지 않습니다.
예를 들어, 모니터링 사용 사례에서 소량의 데이터 손실은 무의미하며, 기본 접근 방식이나 최대 한 번(at-most-once) 보장을 사용할 수 있습니다.
자동 오프셋 리셋 구성은 사용 사례에 따라 결정해야 합니다.
이 값을 'earliest'로 설정하고 브로커에 소비자가 시작되기 전에 이미 많은 데이터가 축적되어 있는 경우, 소비자는 최신 데이터에 접근할 수 있기까지 더 많은 시간을 소요하게 됩니다.
이전 데이터를 놓치는 것이 중요하지 않은 사용 사례에는 이 매개변수를 'latest'로 설정할 수 있습니다.
5. Conclusion
카프카 오프셋은 해당 파티션의 시작부터 메시지의 순서를 나타내는 숫자 값입니다.
이 숫자 값은 카프카가 파티션 내에서의 진행 상황을 추적하는 데 도움을 줍니다.
또한 카프카가 수평으로 확장하면서도 장애에 강한 특성을 유지할 수 있게 합니다.
오프셋 저장에 사용되는 로직은 카프카의 메시지 전달 보장과도 밀접한 관련이 있습니다.
카프카는 오프셋 관리 프로세스의 동작을 변경할 수 있는 여러 구성 매개변수를 제공합니다.
최적의 구성을 달성하기 위해서는 사용 사례를 신중하게 고려하고 각 매개변수의 영향을 분석해야 합니다.
'데이터 엔지니어링 정복 > Kafka' 카테고리의 다른 글
| [Kafka] 10. Kafka Tools (1) | 2025.05.02 |
|---|---|
| [Kafka] 9. Zookeeper (0) | 2025.05.02 |
| [Kafka] 7. Partition (1) | 2025.05.01 |
| [Kafka] 6. Topics (1) | 2025.04.30 |
| [Kafka] 5. Cluster (2) | 2025.04.29 |


