
- 지구정복과정 (521)

- 데이터 엔지니어링 정복 (419)
- Elastic Stack (2)
- Hadoop Ecosystem (27)
- HTML-CSS-JavaScript-Spring-.. (43)
- JAVA & JSP (46)
- Python (28)
- SQL (14)
- Cloud(AWS, Ncloud) (8)
- Docker&Kubernetes (2)
- Linux (11)
- Git-GitHub (9)
- Algorithm (159)
- HDFS (4)
- Iceberg (6)
- Hive (5)
- Hue (1)
- Yarn (1)
- Spark (9)
- MapReduce (2)
- Airflow (2)
- Sqoop (2)
- Tez (0)
- Trino (3)
- Kafka (12)
- Zookeeper (2)
- Flume (2)
- Oozie (1)
- Hbase (3)
- Ranger (1)
- OpenSearch (1)
- Ansible & AWX (2)
- AD & LDAP (0)
- NiFi (3)
- Ambari (1)
- Infra Solr (2)
- 데이터 애널리틱스 정복 (3)
- 프로젝트 (5)
- 자격증 정복 (33)
- 영어 정복 (7)
- 건강 정복 (5)
- 주식 정복 (가능 ?) (0)
- 이것저것 (38)
- 데이터 엔지니어링 정복 (419)
반응형
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- hadoop
- Trino
- BigData
- 여행
- 코딩
- 알고리즘
- HIVE
- bigdata engineering
- java
- 삼성역맛집
- 용인맛집
- Data Engineer
- 프로그래머스
- pyspark
- Iceberg
- 백준
- 영어
- Apache Kafka
- 자바
- bigdata engineer
- 코테
- 맛집
- 코엑스
- apache iceberg
- Spark
- Data Engineering
- 코딩테스트
- 개발
- Kafka
- 코엑스맛집
Archives
- Today
- Total
지구정복
[SQLD] 7. 정규화와 성능 본문
728x90
반응형
1. 정규화를 통한 성능 향상 전략
- 정규화는 기본적으로 데이터의 중복을 제거하여 주고, 데이터가 관심사별로 처리되는 경우가 많아 정규화를 통해서 대체적으로 성능이 향상됨
- 데이터베이스에서의 성능은 DML작업성능과 Select 작업성능으로 크게 구분됨
- DML작업성능과 Select작업성능은 Trade-off 되는 경우가 많음
- 아래그림을 통해 일반적으로 정규화된 모델은 DML작업시 반정규화된 모델에 비해 처리성능이 향상됨
- 단, Select작업성능은 초리 조건에 따라 저하될 수도 있음

| 정규화 vs 반정규화 |
반정규화만이 조회성능을 향상시킨다는 고정관념에서 탈피해야함, |
2. 반정규화된 테이블의 성능저하 사례1

- 위 그림에서 화살표 왼쪽은 반정규화(2차 정규화:모든속성은 식별자에 완전종속), 오른쪽은 정규화된 테이블의 모습
- '관서 번호가 1000이고, 납부자번호가 A1000인 관서명과 공무원명을 조회하라'라고 한다면
반정규화
SELECT 관서명,공무원명
FROM 정부보관금관서원장
WHERE 관서번호=1000 AND 납부자번호 ='A1000';-
정규화
SELECT A.관서명, B.공무원명
FROM 관서 A, 정부보관금관서원장 B
WHERE A.관서번호=B.관서번호 AND A.관서번호=1000 AND B.납부자번호 ='A1000';- 오른쪽의 정규화된 테이블의 경우 PK를 통해 조인을 하여 데이터를 조회하기 때문에(Unique Index 사용) 반정규화된 경우와 비교하여 성능차이는 미미함
SELECT 관서명,공무원명
FROM 정부보관금관서원장
WHERE 관서번호=1000 AND 납부자번호 ='A1000';
- 만일 '관서등록일자가 2010년 이후 관서를 모두 조회하라'라고 한다면
- 반정규화
SELECT DISTINCT 관서명
FROM 정부보관금관서원장
WHERE 관서등록일자 >= TO_DATE('20100101', 'YYYYMMDD');-
정규화
SELECT 관서명
FROM 정부보관금관서원장
WHERE 관서등록일자 >= TO_DATE('20100101', 'YYYYMMDD');- 반정규화의 경우 납부자번호만큼 누적된 데이터를 읽고 중복을 제거하여 결과를 보여주지만, 정규화된 경우 관서수만큼만 존재하는 데이터를 읽어 결과를 보여주기 때문에 성능이 우수함
3. 반정규화된 테이블의 성능저하 사례2

- 위 그림에서 '서울 7호'에서 매각된 총매각금액, 총유찰금액을 산출하는 조회용 SQL문장을 작성하면
반정규화
SELECT B.총매각금액 , B.총유찰금액
FROM (SELECT DISTINCT 매각일자
FROM 일자별매각물건
WHERE 매각장소 = '서울 7호') A , 매각일자별매각내역 B
WHERE A.매각일자 = B.매각일자 AND A.매각장소 = B.매각장소;- 조인조건이 되는 대상을 찾기위해 인라인뷰를 사용
- 100만건의 데이터를 읽고 조건에 맞는 데이터를 가져오기위해 중복을 제거하는 과정에서 성능저하가 발생

- 위 그림은 2차 정규화를 적용하여 매각일자를 PK로 지정하였고, 같은 데이터를 조회하기 위해 쿼리를 작성하면
정규화
SELECT B.총매각금액 , B.총유찰금액
FROM 매각기일 A, 매각일자별매각내역 B
WHERE A.매각장소 = '서울 7호' AND A.매각일자 = B.매각일자 AND A.매각장소 = B.매각장소;- 2차 정규화된 매각기일이 5천건밖에 되지 않고 드라이빙 테이블이 될 경우, 매각일자별매각내역은 PK로 조회되므로 반정규화에 비해 성능향상
4. 반정규화된 테이블의 성능저하 사례3


- 위 그림의 경우 동일한 속성 형식을 두 개 이상의 속성으로 나열한 반정규화 모델임(1차 정규화 : 속성은 원자값을 가짐)
- 만일, 위 모델에 유형기능분류코드에 따라 데이터의 조회가 많이 나타나 인덱스를 생성한다면 총 9개의 인덱스를 생성해야 함 ---> SELECT성능은 향상되나 DML성능은 저하됨
- 만약 각 유형코드별로 조건을 부여하여 모델코드와 모델명을 조회하는 SQL문장을 작성한다면
반정규화
SELECT 모델코드, 모델명
FROM 모델
WHERE ( A유형기능분류코드1 = '01' ) OR ( B유형기능분류코드2 = '02' )
OR ( C유형기능분류코드3 = '07' ) OR ( D유형기능분류코드4 = '01' )
OR ( E유형기능분류코드5 = '02' ) OR ( F유형기능분류코드6 = '07' )
OR ( G유형기능분류코드7 = '03' ) OR ( H유형기능분류코드8 = '09' )
OR ( I유형기능분류코드9 = '09' ) ;
-
위 그림은 1차 정규화를 진행하여, 모델기능분류코드를 분리하였음
- 인덱스를 생성시 모델기능분류코드에만 1개 생성
- 유형코드별로 조건을 부여하여 모델코드와 모델명을 조회하는 SQL문장을 다시 작성한다면
정규화
SELECT A.모델코드, A.모델명
FROM 모델 A, 모델기능분류코드 B
WHERE ( B.유형코드 = 'A' AND B.기능분류코드 = '01' AND A.모델코드 = B.모델코드 )
OR ( B.유형코드 = 'B' AND B.기능분류코드 = '02' AND A.모델코드 = B.모델코드 )
OR ( B.유형코드 = 'C' AND B.기능분류코드 = '07' AND A.모델코드 = B.모델코드 )
OR ( B.유형코드 = 'D' AND B.기능분류코드 = '01' AND A.모델코드 = B.모델코드 )
OR ( B.유형코드 = 'E' AND B.기능분류코드 = '02' AND A.모델코드 = B.모델코드 )
OR ( B.유형코드 = 'F' AND B.기능분류코드 = '07' AND A.모델코드 = B.모델코드 )
OR ( B.유형코드 = 'G' AND B.기능분류코드 = '03' AND A.모델코드 = B.모델코드 )
OR ( B.유형코드 = 'H' AND B.기능분류코드 = '09' AND A.모델코드 = B.모델코드 )
OR ( B.유형코드 = 'I' AND B.기능분류코드 = '09' AND A.모델코드 = B.모델코드 ) ;- 위 SQL구문은 유형코드+기능분류코드+모델코드에 인덱스가 걸려 있으므로 인덱스를 통해 데이터를 조회함으로써 성능이 향상
5. 반정규화된 테이블의 성능저하 사례4
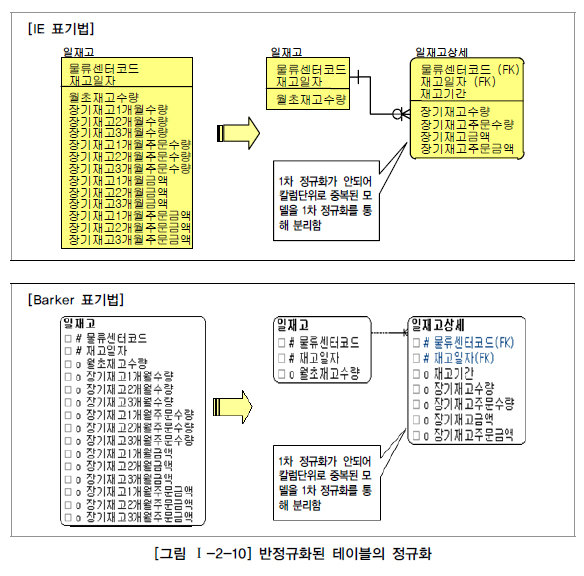
- '반정규화된 테이블의 성능저하 사례3'과 동일한 사례임
6.함수적 종속성(Functional Dependency)에 근거한 정규화 수행 필요

- 위 그림은 이름, 출생지, 호주라는 속성은 주민등록번호 속성에 종속된다는 의미
- 만약 어떤 사람의 주민등록번호가 신고되면 그 사람의 이름, 출생지, 호주가 생성되어 단지 하나의 값만을 가지게 된다면, 다음과 같이 표현할 수 있음
주민등록번호 -> (이름, 출생지, 호주)
- 즉 '주민등록번호가 이름, 출생지, 호주를 함수적으로 결정한다.'라고 말할 수 있음
정규화의 궁극적인 목적 반복적인 데이터를 분리하고 각 데이터가 종속된 테이블에 적절하게(프로세스에 의해 데이터의 정합성이 지켜질 수 있어야 함) 배치되도록 하는 것
[출처]
http://wiki.gurubee.net/pages/viewpage.action?pageId=27427181&
728x90
반응형
'자격증 정복 > SQLD(보유)' 카테고리의 다른 글
| [SQLD] 9. 대량 데이터에 따른 성능 (0) | 2020.11.09 |
|---|---|
| [SQLD] 8. 반정규화와 성능 (0) | 2020.11.09 |
| [SQLD] 6. 성능 데이터 모델링의 정의 (0) | 2020.11.09 |
| [SQLD] 5. 식별자(Identifiers) (0) | 2020.11.09 |
| [SQLD] 4. 관계(Relationship) (0) | 2020.11.09 |
'자격증 정복/SQLD(보유)' Related Articles
more




Comments