
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 코테
- 프로그래머스
- apache iceberg
- 영어
- Linux
- hadoop
- Spark
- 용인맛집
- 맛집
- Apache Kafka
- Trino
- 코엑스맛집
- HIVE
- 여행
- 알고리즘
- 백준
- java
- Kafka
- Data Engineer
- bigdata engineer
- 삼성역맛집
- Data Engineering
- BigData
- 코딩테스트
- pyspark
- bigdata engineering
- Iceberg
- 개발
- 코딩
- 자바
- Today
- Total
지구정복
[2021_개인. 하둡 에코시스템 구축을 위한 파일럿 프로젝트] 본문
* 인프런 교육과정 : 빅데이터 파일럿 프로젝트 - 김강원
1. 프로젝트 개요
1-1. 배경 및 목적
4차 산업혁명으로 인해 모든 사물들이 연결되는 초연결 사회로 변화되고 있고 자동차 또한 최첨단 전자장치와 무선통신을 결합한 스마트카로 변화되고 있다. 그로인해 스마트카는 무수한 로그 데이터들이 만들어 내고 있다. 이러한 로그 데이터를 유의미하게 사용하기 위해서는 저장하고 분석할 수 있는 환경이 필요하고 분석결과를 토대로 새로운 인사이트를 발견하여 가치를 창출할 수 있어야 한다.
따라서 이번 프로젝트의 목적은 스마트카에서 발생되는 차량의 다양한 로그 데이터를 수집해서 차량 기능별 상태를 점검하고, 운전자의 운행 정보가 담긴 로그를 실시간으로 수집해서 운전자 주행 패턴을 분석하는 것이다.
또한 하둡 에코시스템을 실제로 구축해보면서 3V로 발생한 데이터를 어떻게 수집, 처리, 탐색, 분석하여 Value를 창출해내는 지에 대한 과정들을 공부한다. 세부적인 에코시스템들의 사용법보다는 전체 에코시스템 구축하는데 중점을 둔다.
*프로젝트 기간: 21.04 ~ 21.05
1-2. 데이터셋 확인
-스마트카 차량상태 데이터
| 구분 | 내용 |
| 데이터 발생 위치 | 100대의 시뮬레이션 차량 |
| 발생 데이터 종류 | 대용량 로그 파일 |
| 데이터 발생 주기 | 3초 |
| 데이터 수집 주기 | 24시간 |
| 데이터 수집 규모 | 100MB/100대 |
| 데이터 타입 | 텍스트(UTF-8), 반정형 |
| 데이터 분석 주기 | 일, 주, 월, 년 |
| 데이터 처리 유형 | 배치 |
| 데이터 구분자 | 콤마(,) |
| 데이터 스키마 | 로그 발생일시, 차량 고유번호, 차량 타이어 상태, 차량 라이트 상태, 차량 엔진 상태, 차량 브레이크 상태, 차량 배터리 충전 상태, 수집 작업 요청일 |
-스마트카 운전자 운행 데이터
| 구분 | 내용 |
| 데이터 발생 위치 | 100대의 시뮬레이션 차량 |
| 발생 데이터 종류 | 실시간 로그 파일 |
| 데이터 발생 주기 | 주행 관련 이벤트 발생 시 |
| 데이터 수집 주기 | 1초 |
| 데이터 수집 규모 | 초당 수집 규모: 약 400KB/100대 |
| 데이터 타입 | 텍스트(UTF-8), 반정형 |
| 데이터 분석 주기 | 실시간 |
| 데이터 처리 유형 | 실시간 |
| 데이터 구분자 | 콤마(,) |
| 데이터 스키마 | 로그 발생 일시, 차량 고유번호, 가속페달 이벤트, 브레이크 이벤트, 운전대 회전 이벤트, 방향지시등 이벤트, 차량 주행 속도, 운전 중인 구역 번호, 수집 작업 요청일 |
-스마트카 운전자 데이터
| 구분 | 내용 |
| 데이터 발생 위치 | 기존 만들어진 샘플 데이터 |
| 발생 데이터 종류 | 기존 데이터 |
| 데이터 발생 주기 | 스마트카 구입시 |
| 데이터 수집 주기 | 필요시 |
| 데이터 수집 규모 | 124KB |
| 데이터 타입 | 텍스트(UTF-8), 반정형 |
| 데이터 분석 주기 | 필요시 |
| 데이터 처리 유형 | 필요시 |
| 데이터 구분자 | | |
| 데이터 스키마 | 차량 고유번호, 성별, 나이, 결혼여부, 거주지역, 직업, 차량cc, 구매연도, 차량타입 |
-스마트카 물품 구매 이력 데이터
| 구분 | 내용 |
| 데이터 발생 위치 | 기존 만들어진 샘플 데이터 |
| 발생 데이터 종류 | 기존 데이터 |
| 데이터 발생 주기 | 스마트카에서 스마트스크린으로 물품 구매시 |
| 데이터 수집 주기 | 필요시 |
| 데이터 수집 규모 | 2.28MB |
| 데이터 타입 | 텍스트(UTF-8), 반정형 |
| 데이터 분석 주기 | 필요시 |
| 데이터 처리 유형 | 필요시 |
| 데이터 구분자 | 콤마(,) |
| 데이터 스키마 | 차량 고유번호, 물품번호, 구매수량, 구매월 |
1-3. 소프트웨어 및 하드웨어 아키텍처
-소프트웨어 아키텍처
구축하게될 하둡 에코 시스템은 다음과 같다.

스마트카 차량상태 데이터와 스마트카 운전자 운행 데이터를 Flume을 통해서 수집하고 적재 간에 버퍼역할을 위해 Kafka를 통해서 Storm으로 보내진다. Storm에서는 각 데이터를 HBase에 저장하는데 실시간 데이터인 스마트카 운전자 운행 데이터에서 특이사항 발생 시 Esper로 인지하여 Redis에 저장시킨다.
다음으로 Data Lake로부터 Data Warehouse, Data Mart를 만들기 위해 Hue 웹UI를 통해서 Hive쿼리를 선언하고 Oozie를 이용해 워크플로를 작성한다. 이 과정에서 분석에 필요한 Data Mart데이터를 만들어낸다.
다음 분석을 위해 Hue에서 Impala를 통해 스마트카 운행 지역별 평균 속도가 가장 높았던 스마트카 차량을 분석해본다.
그리고 Jeppelin에서 Spark 스칼라 코드를 통해 운행 지역별 평균 속도를 구한다.
그리고 Mahout을 통해 스마트카별 차량 용품을 추천해준다.
그리고 Jeppelin에서 SparkML의 랜덤포레스트 분석을 통해 현재 스마트카의 상태가 정상인지 비정상인지를 구별한다.
마지막으로 Mahout과 SparkML을 통해 스마트카 운전자에 대한 군집분석을 진행한다.
최종적으로 Sqoop을 통해 외부 데이터베이스에서 쓰일 테이블을 Export하는 작업을 진행한다.
또한 Cloudera Manager를 통해 하둡 에코시스템들을 프로비저닝, 매니지먼트, 모니터링하고
Zookeeper를 통해 하둡, HBase, Kafka, Storm에서 클러스터 멤버십 기능 및 환경설정 동기화 등을 처리한다.
-하드웨어 아키텍처

2. 하둡 에코시스템 구축
2-1. 수집 레이어
플럼은 스마트카에서 발생하는 로그를 직접 수집하는 역할을 담당한다. 100대의 스마트카에 대한 상태 정보 로그 파일이 로그 시뮬레이터를 통해 생성된다. 이렇게 만들어진 상태 정보 파일을 플럼 에이전트가 일 단위로 수집해서 하둡에 적재하고 향후 대규모 배치 분석에 활용한다.
두 가지 플럼 에이전트로 나뉜다.
첫 번째는 일일 단위 수집하는 스마트카 차량 상태 데이터이다. 또한 HBase에 바로 적재된다.

플럼 에이전트1은 배치성 플럼 에이전트이고 Source부분에서 Spooldir로 설정하여 특정 디렉토리를 모니터링하고 있다가 새로운 파일이 생성되면 이벤트를 감지해서 batchsize의 설정값 만큼 읽어서 Channel에 데이터를 전송한다.
Channel 타입은 Memory, File 등이 있는데 Memory는 Source로부터 받은 데이터를 메모리상에 중간 적재하므로 성능이 높지만 안정성이 낮다. File은 Source에서 받은 데이터를 로컬 파일시스템 경로인 dataDirs에 임시 저장했다가 Sink에게 데이터를 제공하므로 성능은 낮지만 안정성이 높다.
먼저 Sink의 타입을 Logger로 지정해서 수집한 데이터가 잘 넘어오는지를 테스트해야한다.
아래와 같이 Flume 구성 파일에서 플럼에이전트1과 플럼에이전트2 모두 작성해준다.

시뮬레이션을 통해 20160101에 3대의 차량에 대해서만 데이터를 발생시킨다.
그리고 아래 명령어로 스마트카 차량상태 데이터가 Flume의 표준 출력 로그로 전송됐는지 확인한다.
tail -f /var/log/flume-ng/flume-cmf-flume-AGENT-server02.hadoop.com.log아래와 같이 데이터가 잘 수집된 것을 확인할 수 있다.

두 번째는 실시간으로 발생되는 스마트카 운전자 운행 데이터이다. 실시간으로 수집된다. 이는 Kafka로 보내진다.

플럼 에이전트2는 실시간성 플럼 에이전트이다. 먼저 Kafka는 대규모로 발생되는 메시지성 혹은 실시간성 데이터를 비동기 방식으로 중계하는 역할을 한다. 원천 시스템으로부터 대규모 트랜잭션 데이터가 발생했을 때 중간에 데이터를 버퍼링하면서 타깃 시스템에 안정적으로 전송해 주는 중간 시스템 역할을 한다.
Kafka Consumer를 작동시키기 위해 아래 명령어를 실행한다.
$ kafka-console-consumer --bootstrap-server server02.hadoop.com:9092 --topic SmartCar-Topic --partition 0스마트카 운전자 운행 데이터가 실시간으로 Kafka Consumer로 유입되고 있다.

2-2. 적재 레이어
2-2-1. 스마트카 차량 상태 데이터 적재하기(배치데이터)
수집 레이어에서 스마트카 차량상태 데이터가 제대로 수집되는지 확인하기 위해 Sink를 logger로 했는데 이제 HDFS에 적재하기 위해 Sink를 HdfsSink로 교체한다.

이제 시뮬레이션을 통해 100대에 대한 스마트카 차량상태 데이터를 발생시키고 Flume을 통해서 HDFS에 적재되는지 확인한다.
아래와 같이 HDFS에 잘 적재된 것을 확인할 수 있다.

2-2-2. 스마트카 운전자 운행 데이터 적재하기(실시간데이터)
실시간 데이터는 하둡에 바로 적재하지 않는다. 왜냐하면 초당 수천 건의 트랜잭션이 발생할 경우 하둡 클러스터에 지나친 오버헤드가 발생하기 때문이다. 따라서 이때 중간에 특정 크기로 모았다가 한꺼번에 적재하기 위해 NoSQL 데이터베이스를 사용해서 적재한다.
아래 그림은 실시간 데이터 적재에 활용되는 기술 아키텍처이다.

Kafka에 저장돼 있는 데이터를 Storm이 받아서 스마트카 운전자 운행 데이터를 HBase에 저장시킨다. 이때 Asper를 통해 평균 시속이 80km/h를 초과하는 운전자 이벤트 정보를 실시간으로 감지해서 Redis Bolt로 보내고 Redis에 적재한다.
먼저 Storm의 Topology를 배포한다. 그리고 Storm UI에서 Topology가 활성화됐는지 확인한다.

Strom의 Topology가 정상적으로 만들어졌으니 이제 실시간 로그파일인 스마트카 운전자 운행 데이터를 발생시키고 Flume이 이를 수집해서 Kafka에 전송하고 이를 Storm이 다시 수신받아 모든 운행 데이터를 HBase에 적재하면서 동시에 속도 위반 차량에 대해서 Esper의 Role을 통해 Redis로 잘 적재가 되는 지 확인해보자.
먼저 Hbase에 적재되고 있는 지 확인한다. 먼저 10대에 차량에 대한 실시간 로그데이터를 발생시켰다.

해당 테이블의 컬럼명까지 나오도록 출력해보자.

A0008 차량을 예시로 보면 컬럼명과 데이터값을 확인할 수 있다.
다음으로 Redis에도 과속차량 데이터가 적재되는 지 확인해보자.

여태까지 총 6대의 과속 차량이 있었고 잘 적재된 것을 확인할 수 있다.
2-3. 처리/탐색 레이어
처리/탐색 레이어의 목적은 HBase에 적재된 Data Lake의 비정형(혹은 반정형) 데이터를 추출/정제/검증/분리/통합 등의 작업을 통해 반정규화된 Hive 테이블로 만들어서 Data Warehouse를 구축하고 여기서 다시 Hive QL을 이용하여 다양한 애드혹 분석으로 EDA를 진행해서 Data Mart를 만드는 것이다. 이렇게 만들어진 Data Mart의 데이터들은 데이터 분석 및 응용 레이어에서 중요하게 사용된다.
처리/탐색 레이어에서 주로 쓰일 에코시스템들은 Hive, Oozie, Hue, Spark이다.
또한 해당 시스템들의 아키텍처는 아래와 같다.

Hue 웹UI를 통해서 Data Lake -> Data Warehouse -> Data Mart로 테이블이 생성될 수 있도록 Hive QL들을 선언하고 이를 Oozie를 이용해서 워크플로를 선언하고 스케줄링한다.
먼저 HBase에 적재되어 있는 스마트카 차량상태 데이터와 스마트카 운전자 운행 데이터를 Hive QL을 이용해서 Hive External 영역에 테이블을 만든다.
-스마트카 차량상태 데이터 create문
create external table if not exists SmartCar_Status_Info (
reg_date string,
car_number string,
tire_fl string,
tire_fr string,
tire_bl string,
tire_br string,
light_fl string,
light_fr string,
light_bl string,
light_br string,
engine string,
break string,
battery string
)
partitioned by( wrk_date string )
row format delimited
fields terminated by ','
stored as textfile
location '/pilot-pjt/collect/car-batch-log/'-파티션 추가
ALTER TABLE SmartCar_Status_Info ADD PARTITION(wrk_date='20200311');
-스마트카 운전자 운행 데이터 create문
CREATE EXTERNAL TABLE SmartCar_Drive_Info(
r_key string,
r_date string,
car_number string,
speed_pedal string,
break_pedal string,
steer_angle string,
direct_light string,
speed string,
area_number string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
"hbase.columns.mapping" = "cf1:date,cf1:car_number,
cf1:speed_pedal,
cf1:break_pedal,
cf1:steer_angle,
cf1:direct_light,
cf1:speed,
cf1:area_number")
TBLPROPERTIES(
"hbase.table.name" = "DriverCarInfo");
그리고 추가적으로 위에서 소개한 스마트카 운전자 데이터와 스마트카 물품 구매 이력 데이터까지 HBase에 업로드 시킨 뒤 Hive External Table로 정의한다.
-스마트카 운전자 데이터 create문
create external table SmartCar_Master(
car_number string,
sex string,
age string,
marriage string,
region string,
job string,
car_capacity string,
car_year string,
car_model string
)
row format delimited
fields terminated by '|'
stored as textfile
location '/pilot-pjt/collect/car-master/'
-스마트카 물품 구매 이력 데이터 create문
create external table SmartCar_Item_BuyList (
car_number string,
item string,
score string,
month string
)
row format delimited
fields terminated by ','
stored as textfile
location '/pilot-pjt/collect/buy-list'
다음으로 스마트카 운전자 데이터에서 Age가 18세 이하인 데이터는 차량의 실소유주가 아닐 수 있으므로 정제하는 작업을 진행한다. 먼저 Jeppelin에서 Spark를 사용할 수 있지만 Spark-shell을 이용해서 테이블을 만들어본다.
이때 만들어지는 테이블은 Hive의 Managed영역에 생성된다.

1번은 변수 smartcar_master_df에 Hive에서 생성한 스마트카 운전자 데이터를 조회하는 Spark 쿼리를 실행해서 저장한다.
2번에서 변수에 해당 테이블 정보가 잘 담겼는지 확인한다.
3번에서 Hive Manged영역에 SmartCar_Master_Over18이라는 테이블명으로 저장한다.
이제 Data Mart를 Oozie의 워크플로를 이용해서 만들어본다. 현재 파일럿 프로젝트에서는 Data Warehouse와 Mart영역을 하나로 합쳐서 진행한다.
총 5개의 주제영역의 데이터셋을 만들 예정이다.
1. 스마트카 차량상태 모니터링 정보
2. 스마트카 운전자 운행기록 정보
3. 이상 운전 패턴 스마트카 정보
4. 긴급 점검이 필요한 스마트카 정보
5. 운전자의 차량용품 구매 이력 정보
위 다섯 가지 데이터는 분석/응용 단계에서 쓰일 예정이다.
먼저 로그 시뮬레이션으로 20200322 날짜로 100대의 스마트카 차량상태 데이터와 운전자 운행 데이터를 발생시킨다.
그리고 각 주제영역의 테이블을 만들기 위해 Hive QL을 정의하고 Oozie의 workflow를 만든다.
아래는 1번 주제영역에 관한 workflow이다. 나머지 4개도 아래와 같이 만들었다.
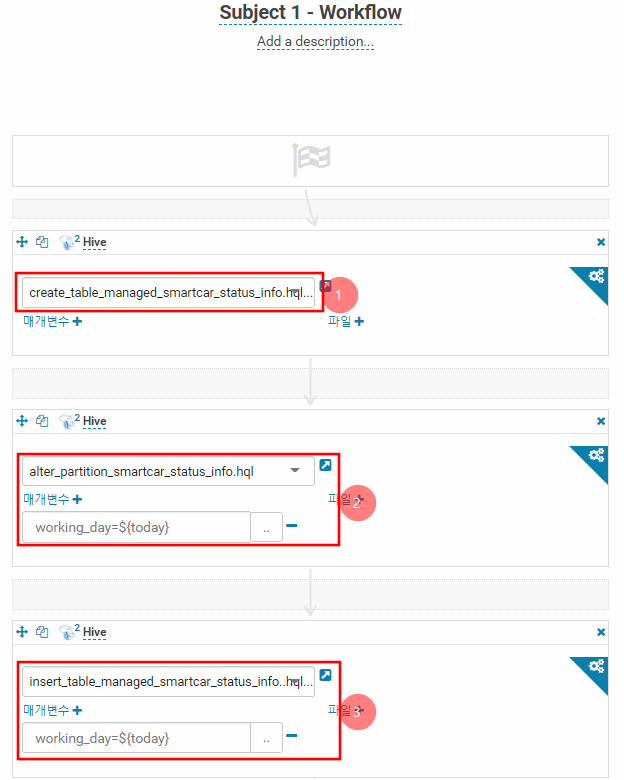
첫 번째 작업인 1번은 managed영역에 생성될 테이블을 만드는 작업이다.
2번은 파티션을 선언해주는 데 매개변수로 오늘 날짜를 넣어준다. 이는 Hive QL안에서 동적 파티션값을 사용하기 위함이다.
3번은 위에서 18세 이상의 스마트카 운전자 테이블 정보를 insert하는 작업이다.
이와 같이 workflow를 정의하고 예약을 걸어둔다. 아래와 같이 예약된 시간이 되면 workflow가 실행된다.

나머지 4개의 주제영역별 Data Mart를 만들면 아래와 같이 총 11개의 테이블이 생성된다.
이때 5개는 Data Mart(Hive Managed영역)의 데이터이다.
앞에 managed_~ 가 붙은 테이블들이다.

2-4. 분석/응용 레이어
분석에 사용될 아키텍처는 아래와 같다. 이때 4, 5, 6번은 머신러닝 개념이므로 제외한다.

왼쪽이 처리/탐색 레이어에서 만든 Data Mart의 주제영역별 5개 테이블이다.
1: Impala-SQL을 이용해서 '상습 과속 지역'을 알아본다.
2: Zeppelin의 웹 UI에서 Spark-SQL로 "운전자 운행 정보"를 분석해서 '지역별 상습 과속 차량'을 추출한다.
3: Mahout의 추천 라이브러리를 이용해서 "차량용품 구매 정보" 테이블을 분석해서 취향이 비슷한 운전자에게 구매 가능성이 높은 차량 용품을 추천한다.
이러한 분석결과 데이터는 테이블로 만들어서 Sqoop을 이용해서 외부 데이터베이스에 Export시킨다.
1. Impala를 이용한 상습 과속 차량 분석
스마트카 운행 지역별 평균 속도가 가장 높았던 스마트카 차량을 출력해보면 다음과 같다.
select
T2.area_number, T2.car_number, T2.speed_avg
from (
select
T1.area_number,
T1.car_number,
T1.speed_avg,
rank() over(partition by T1.area_number order by T1.speed_avg desc) as ranking
from (
select area_number, car_number, avg(cast(speed as int)) as speed_avg
from managed_smartcar_drive_info
group by area_number, car_number
) T1
) T2
where ranking = 1
위 결과를 보면 각 운행지역별로 과속하는 차량 번호를 알려주는데 A01~03에서는 F0076이라는 차량이 평균속도 160 이상 상습적으로 과속하는 것을 알 수 있다. 이러한 데이터를 이용해서 외부 어플리케이션으로 해당 차량에 경고나 주의를 주는 서비스를 만들 수 있다.
2. Zeppelin을 이용한 운행 지역 분석
스마트카가 운행한 지역들의 평균 속도를 구하고, 평균 속도가 높은 순서대로 출력하면 다음과 같다.
select T1.area_num, T1.avg_speed
from (select area_num, avg(speed) as avg_speed
from DriveInfo
group by area_num
) T1
order by T1.avg_speed desc

3. Mahout을 이용한 스마트카 차량용품 추천
각 차량번호에게 Mahout 추천 알고리즘을 통해서 선호할만한 차량용품 3가지를 추천해준다.
실행 결과는 아래와 같다.
$ mahout recommenditembased -i /pilot-pjt/mahout/recommendation/input/item_buylist.txt -o /pilot-pjt/mahout/recommendation/output/ -s SIMILARITY_COOCCURRENCE -n 3
3. 결론 및 보완사항
해당 교육과정을 통해서 처음으로 하둡 에코시스템을 구축하고 데이터를 수집, 전처리, 적재, 분석하는 과정들을 경험해 볼 수 있었다.
교육과정에서 주어진 코드들을 응용해서 나만의 파일럿 프로젝트를 만들어보는 것도 귀중한 경험이 될 것 같다.
'프로젝트' 카테고리의 다른 글
| [2021_팀. 하둡과 웹크롤러를 이용한 의류 브랜드 경쟁력 분석] (3) | 2021.06.07 |
|---|---|
| [2021_팀. 랜선여행 웹 커뮤니티 프로젝트] (0) | 2021.04.20 |
| [2017_팀. 날씨데이터를 이용한 매출예측 웹서비스] (0) | 2021.04.09 |
| [미니프로젝트] Java Swing을 이용한 CRUD프로그램 만들기(축구선수 관리 프로그램) (0) | 2020.12.17 |



