
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 여행
- bigdata engineer
- Trino
- 알고리즘
- 코엑스맛집
- 코딩테스트
- Data Engineer
- Iceberg
- 용인맛집
- apache iceberg
- Kafka
- 코엑스
- 프로그래머스
- 영어
- java
- HIVE
- Spark
- 맛집
- pyspark
- 코딩
- BigData
- 코테
- bigdata engineering
- 삼성역맛집
- hadoop
- Data Engineering
- 개발
- Apache Kafka
- 자바
- 백준
- Today
- Total
지구정복
[Hadoop] 02/17 | 하둡과 맵리듀스, yarn의 개념, yarn 사용하기 본문
[Hadoop] 02/17 | 하둡과 맵리듀스, yarn의 개념, yarn 사용하기
noohhee 2021. 2. 17. 17:391. 하둡과 맵리듀스, yarn의 개념
1. hadoop
1. hdfs - 분산 저장 구조
2. mapreduce - 취합 및 분석
출처 : fniko.tistory.com/entry/Hadoop-1-%ED%95%98%EB%91%A1-%EC%86%8C%EA%B0%9C?category=512556
1. 분산시스템과 하둡
값싼 범용 컴퓨터들을 하나로 묶어 하나의 기능을 수행할 수 있는 분산환경을 구축하는 것이 하나의 좋은 컴퓨터를 사용하는 것보다 가격대비 효율이 높다. 이것의 하둡의 데이터 저장 및 처리 방법이다.
또 하나의 하둡의 특징은 데이터를 가져와서 처리하는 것이 아니라 코드를 데이터 있는 곳으로 보내서 처리한다.
하둡에서 데이터는 이미 클러스터 내에 분산되어 배치되어 있고 데이터의 연산은 실제 데이터가 위치한
컴퓨터에서 바로 이루어진다.
2. SQL데이터베이스와 하둡
관계형 데이터베이스가 SQL을 이용해 구조화된 데이터를 처리하는 반면 하둡은 텍스트와 같은 비구조적 데이터를 처리한다. 이 둘을 상호보완적인 역할을 할 수 있다.
3. MapReduce의 이해
맵리듀스는 하나의 데이터 처리 모델이다. 맵리듀스의 장점은 여러 대의 컴퓨터들에서 데이터를 처리하는 경우 확장이 쉽다는 점이다.
맵리듀스에서 데이터를 처리하는 기본단위는 mapper와 reducer이다. 이렇게 두 가지로 나누기만 하면 클러스터에서 환경 설정만 수정해주면 확장이 가능하다.
mapper는 입력데이터를 필터링하고 reducer가 처리할 수 있는 형태로 변형시키며, reducer는 값을 받아 통합한다.
중간에 shuffle도 있을 수 있다.
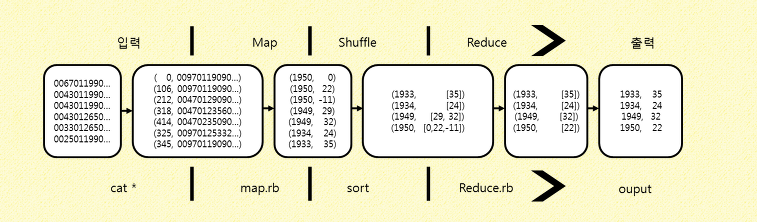
입력 : 가공되지 않은 정보 수집
Map : Mapper 함수를 통해 자료를 Mapping시켜 Reducer함수가 처리할 수 있게 가공
Shuffle : 아직 정보가 많이 지저분하기때문에 Shuffle함수를 통해 자료를 재배치
Reduce : Reducer함수가 데이터를 처리하여 결과 출력
1.4 yarn이란
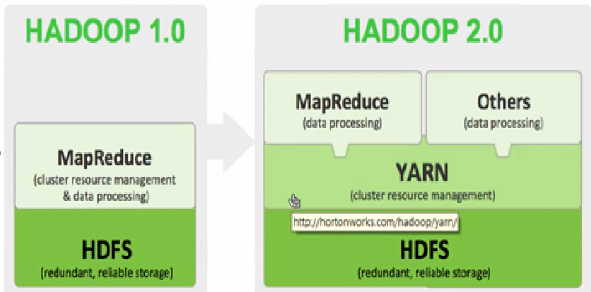
얀은 맵리듀스의 차세대 기술로 맵리듀스의 확장성과 속도 문제를 해소하기 위해 새로 개발되었다.
얀 자체로 맵리듀를 구동할 수 있고 추가로 다른 분산 처리 프레임워크를 사용자의 인터페이스 개발만으로 구동이 가능하다.
1.4.1. 얀의 구조
- 리소스 매니저
클러스터 전체를 관리하는 마스터 서버의 역할을 담당, 응용 프로그램의 요청을 처리
클러스터에서 발생한 작업을 관리하는 애플리케이션 매니저를 내장하고 있으며, 응용 프로그램들 간의 자원 사용에 대한 경쟁을 죠율한다. - 노드매니저
노드당 하나씩 존재하며, 슬레이브 노드의 자원을 모니터링하고 관리하는 역할을 수행한다.
노드 매니저는 리소스 매니저의 지시를 받아 작업 요구사항에 따라서 컨테이너를 생성한다. - 애플리케이션 마스터
노드 매니저와 함께 번들로 제공되며, 작업당 하나씩 생성이되며, 컨테이너를 사용하여 작업 모니터링과 실행을 관리한다. 또한 리소스 매니저와 작업에 대한 자원 요구사항을 협상하고, 작업을 완료하기 위한 책임을 가진다. - 컨테이너
CPU, 디스크, 메모리 등과 같은 속성으로 정의된다. 모든 작업(job)은 결국 여러 개의 작업(task)으로 세분화되며, 각 작업은 하나의 컨테이너 안에서 실행이 된다. 필요한 자원의 요청은 애플리케이션 마스터가 담당하며 승인 여부는 리소스 매니저가 담당한다. 컨테이너 안에서 실행할 수 있는 프로그램은 자바 프로그램뿐만 아니라, 커맨드 라인에서 실행할 수 있는 프로그램이면 모두 가능하다.
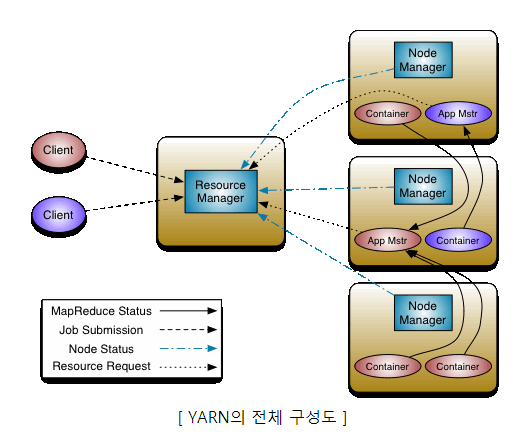
1. yarn 사용하기
1. yarn 설정 및 실행
[hadoop@localhost ~]$ cd hadoop-3.2.2/etc/hadoop/
[hadoop@localhost hadoop]$ head hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.275.b01-1.el8_3.x86_64
[hadoop@localhost hadoop]$ vi yarn-env.sh
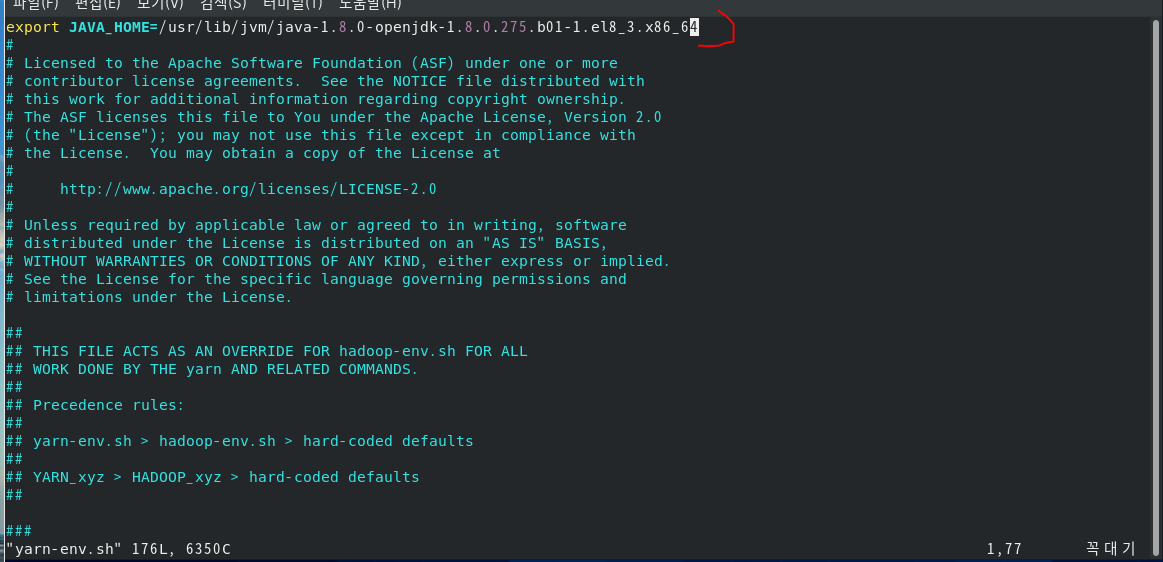
[hadoop@localhost hadoop]$ vi hdfs-site.xml4yy p : 4줄 복사
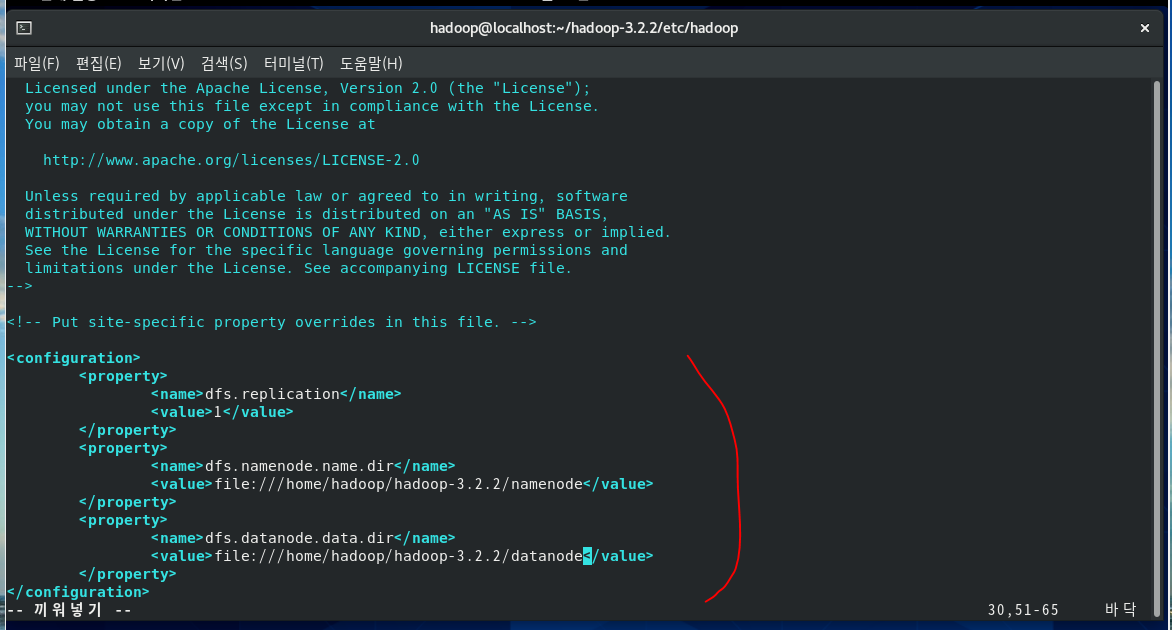
[hadoop@localhost hadoop]$ mkdir /home/hadoop/hadoop-3.2.2/namenode
[hadoop@localhost hadoop]$ mkdir /home/hadoop/hadoop-3.2.2/datanode
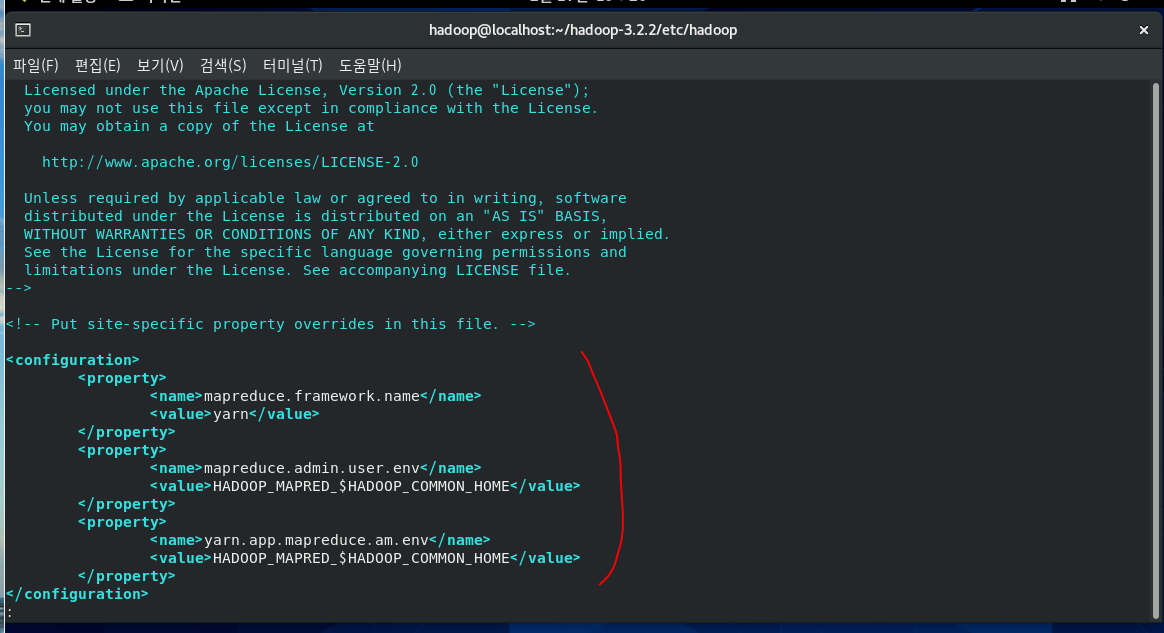
[hadoop@localhost hadoop]$ vi mapred-site.xml
[hadoop@localhost hadoop]$ vi yarn-site.xml
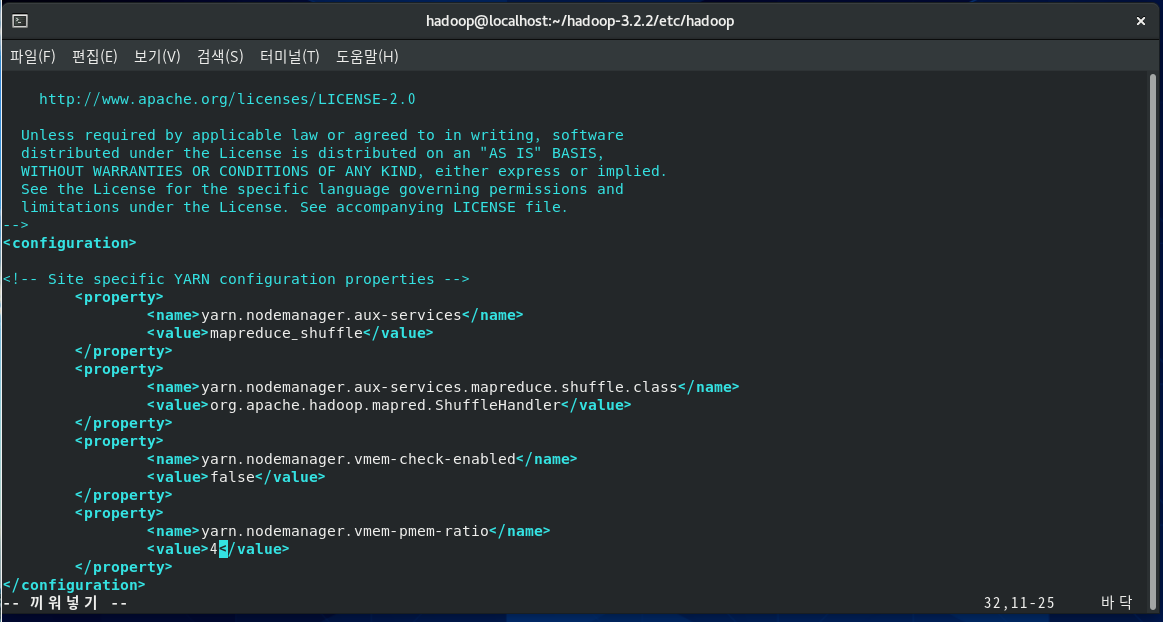
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
</configuration>
기존 사용했던 tmp디렉터리에 파일들과 namenode를 포맷시켜준다. 이때 경로를 잘 확인하고 포맷하자.
[hadoop@localhost hadoop]$ cd
[hadoop@localhost ~]$ rm -fr hadoop-3.2.2/tmp/*
[hadoop@localhost ~]$ hdfs namenode -format
#하둡이 지정되어있는 클래스패스 정보 확인하기
[hadoop@localhost ~]$ hadoop classpath
#하둡 실행
[hadoop@localhost ~]$ start-dfs.sh
[hadoop@localhost ~]$ jps
#yarn 실행하기
[hadoop@localhost ~]$ start-yarn.sh
[hadoop@localhost ~]$ jps
#NodeManager (nm), ResourceManager (rm) 실행
#yarn 종료하기
[hadoop@localhost ~]$ stop-yarn.sh
[hadoop@localhost ~]$ stop-dfs.sh
#한꺼번에 실행하고 종료하기
[hadoop@localhost ~]$ start-all.sh
[hadoop@localhost ~]$ jps
[hadoop@localhost ~]$ stop-all.sh
[hadoop@localhost ~]$ start-all.sh
#현재 가동중인 시스템의 정보확인하기
[hadoop@localhost ~]$ hdfs dfsadmin -report
전체적인 어플리케이션에 대한 진행상황을 브라우저에서 확인할 수 있다.
yarn에 의해서 처리되는 정보들을 확인할 수 있다.
node에 대한 정보, 어떤 특정 기능에 대한 처리작업들도 확인가능
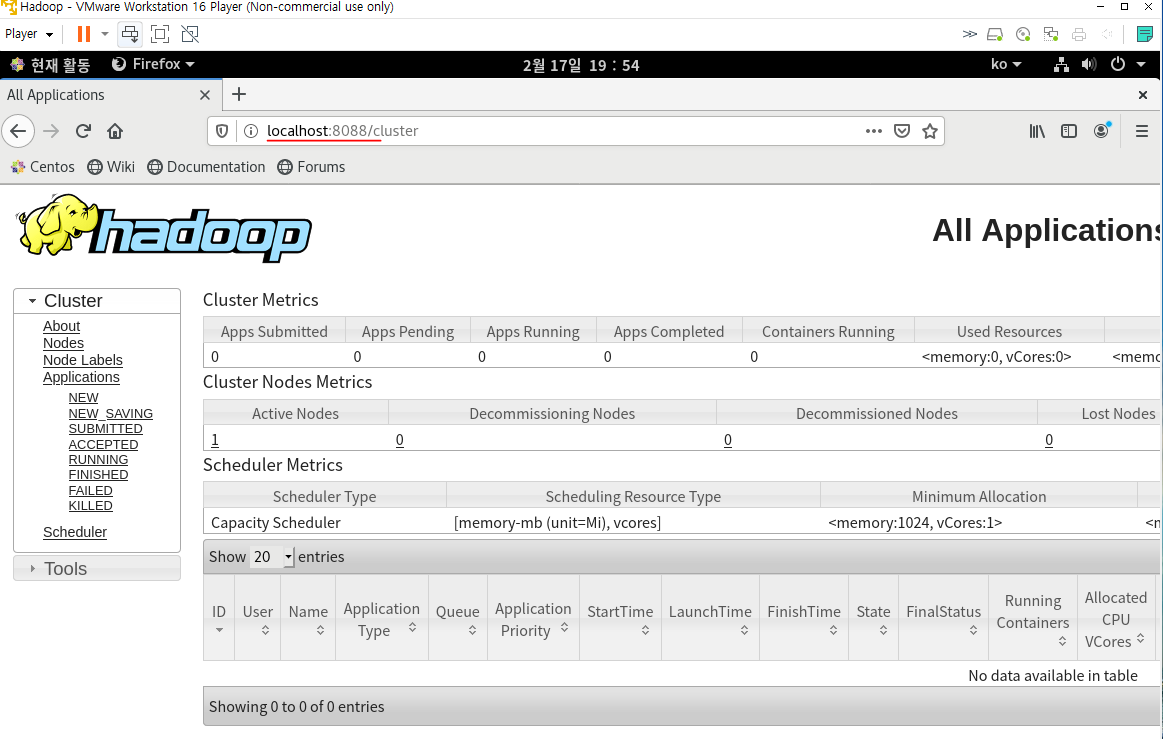
또한 원격에서도 확인이 가능하다. 윈도우 브라우저에서 확인해보자.
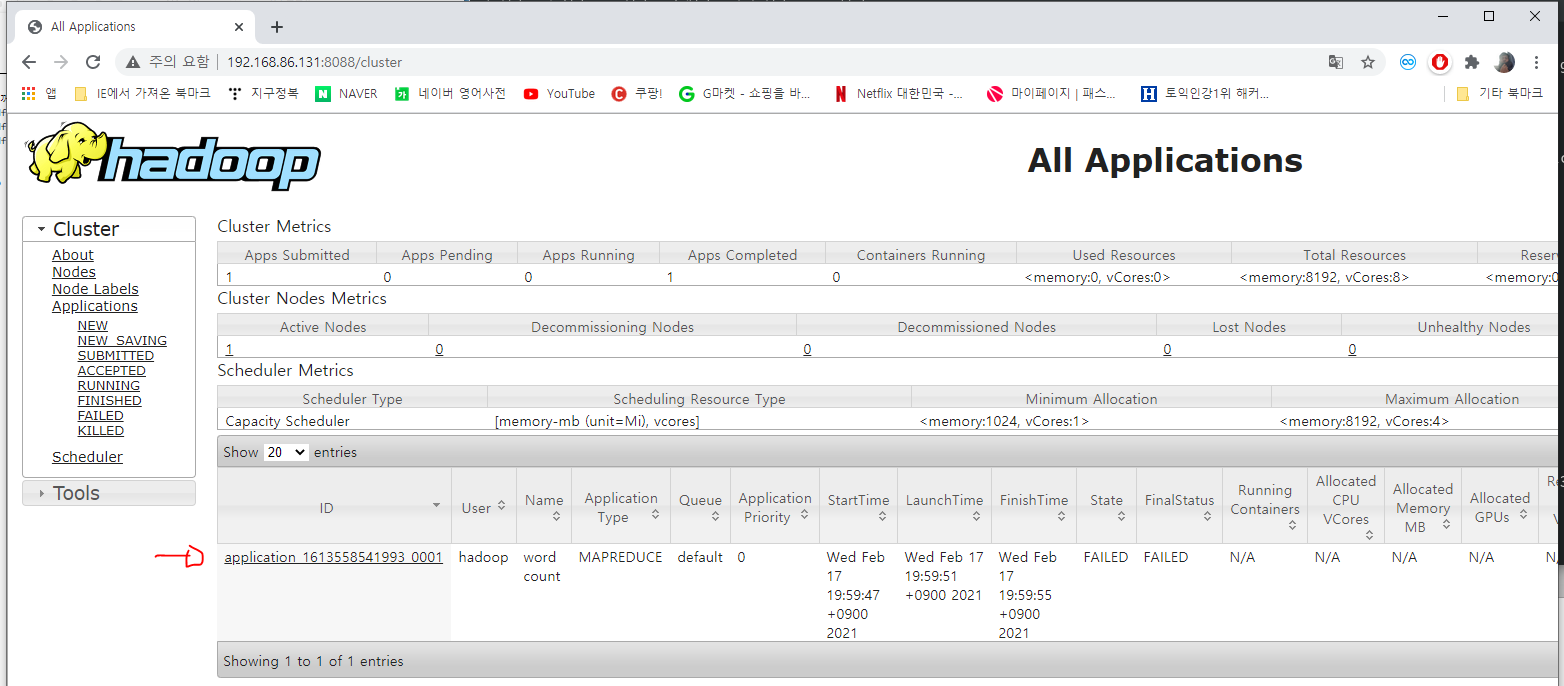
워드카운트를 실행해보자.
#-p 옵션은 서브디렉터리까지 한꺼번에 만든다는 옵션
[hadoop@localhost ~]$ hdfs dfs -mkdir -p /user/hadoop
[hadoop@localhost ~]$ hdfs dfs -put ./hadoop-3.2.2/NOTICE.txt /user/hadoop
[hadoop@localhost ~]$ hdfs dfs -put ./hadoop-3.2.2/README.txt /user/hadoop
#워드카운트 실행
[hadoop@localhost ~]$ hadoop jar hadoop-3.2.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount /user/hadoop/*.txt /output
워드카운트 어플리케이션이 실행중인 것을 확인할 수 있다.
'데이터 엔지니어링 정복 > Hadoop Ecosystem' 카테고리의 다른 글
| [Virtual Machine 구성] CentOS 설치 및 환경구성, 가상서버 복제, 클라우데라 매니저 설치 (0) | 2021.05.03 |
|---|---|
| [BigData Architecture] 빅데이터 소프트웨어 및 하드웨어 아키텍처 (0) | 2021.05.03 |
| [Virtual Machine 구성] VirtualBox 설치하기, 네트워크 설정, 가상서버 이미지 설치, 파일럿PC 호스트 파일 수정, 클라우데라 매니저 접속하기 (0) | 2021.05.02 |
| [BigData] 개념, 특징, 활용, 빅데이터 프로젝트 (0) | 2021.05.02 |
| [Hadoop] 02/16 | 빅데이터 개념과 하둡, 하둡설치, 맵리듀스사용(wordcount), 하둡저장소 만들기, 복습 (0) | 2021.02.16 |



