
- 지구정복과정 (517)

- 데이터 엔지니어링 정복 (415)
- Elastic Stack (2)
- Hadoop Ecosystem (27)
- HTML-CSS-JavaScript-Spring-.. (43)
- JAVA & JSP (46)
- Python (28)
- SQL (14)
- Cloud(AWS, Ncloud) (8)
- Docker&Kubernetes (2)
- Linux (11)
- Git-GitHub (9)
- Algorithm (159)
- HDFS (4)
- Iceberg (6)
- Hive (5)
- Hue (1)
- Yarn (1)
- Spark (8)
- MapReduce (2)
- Airflow (2)
- Sqoop (2)
- Tez (0)
- Trino (2)
- Kafka (12)
- Zookeeper (2)
- Flume (2)
- Oozie (1)
- Hbase (3)
- Ranger (1)
- OpenSearch (1)
- Ansible & AWX (2)
- AD & LDAP (0)
- NiFi (3)
- Ambari (1)
- 데이터 애널리틱스 정복 (3)
- 프로젝트 (5)
- 자격증 정복 (33)
- 영어 정복 (7)
- 건강 정복 (5)
- 주식 정복 (가능 ?) (0)
- 이것저것 (38)
- 데이터 엔지니어링 정복 (415)
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 여행
- bigdata engineering
- 코엑스
- 삼성역맛집
- Data Engineering
- 용인맛집
- 코엑스맛집
- hadoop
- 영어
- bigdata engineer
- 맛집
- 프로그래머스
- Trino
- Iceberg
- 백준
- 코딩
- HIVE
- Apache Kafka
- Data Engineer
- 자바
- java
- pyspark
- 코테
- BigData
- 알고리즘
- Spark
- Kafka
- apache iceberg
- 개발
- 코딩테스트
- Today
- Total
지구정복
[BigData Architecture] 빅데이터 소프트웨어 및 하드웨어 아키텍처 본문
[BigData Architecture] 빅데이터 소프트웨어 및 하드웨어 아키텍처
noohhee 2021. 5. 3. 00:00출처: 실무로 배우는 빅데이터기술 - 위키북스
1. 소프트웨어 아키텍처
전체 아키텍처 모습
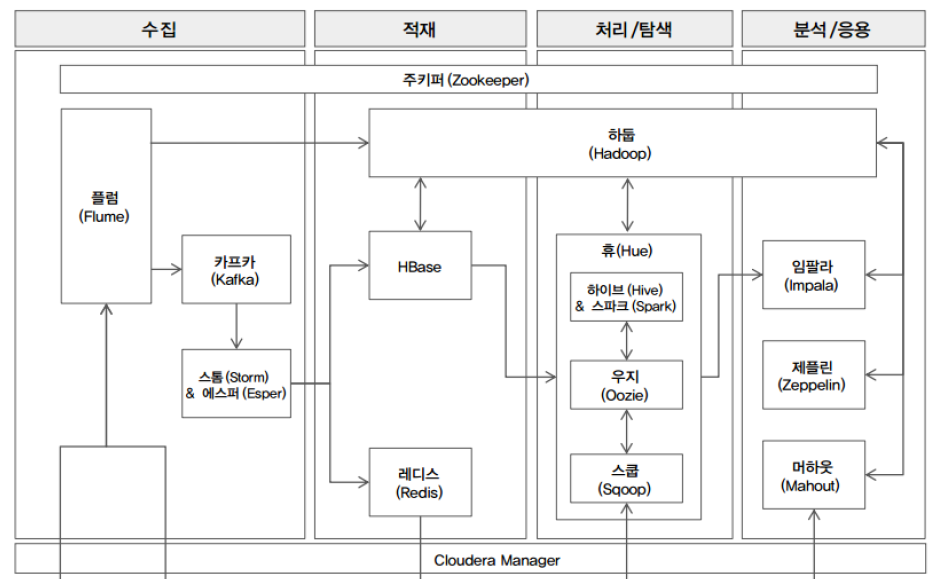
- 수집 단계
수집단계에서 쓰이는 sw는 보통 플럼, 카프카, 스톰/에스퍼가 있다.
이때 로그와 같은 비정형데이터들을 수집하게 되며 실시간 데이터가 아닌 배치프로그램으로 수집되는 대용량 로그 데이터들은 보통 플럼이 처리하고
실시간 로그 데이터들은 플럼 -> 카프카 -> 스톰이 순으로 처리하게 된다.
플럼은 하둡으로 데이터를 전송, 스톰은 HBase, 레디스로 데이터를 전송한다.
-적재 단계
적재 단계의 sw는 하둡, HBase, 레디스가 쓰인다.
대용량 로그 데이터는 하둡으로 적재,
실시간 데이터는 플럼 -> 카프카 -> 스톰 ->HBase/레디스로 적재된다.
-처리/탐색 단계
적재단계에서 적재된 데이터는 하이브/스파크를 통해 정제, 변형, 통합, 분리, 탐색 등의 작업을 수행하고, 데이터를 정형화된 구조로 정규화해 데이터 마트를 만든다.
그리고 가공/분석된 데이터를 외부로 제공하기 위해 스쿱 사용,
이러한 처리/탐색 단계는 데이터의 품질을 높이는 단계이므로 과정이 길고 복잡해진다. 이를 간단히하고 자동화하기 위해 우지를 사용한다.
-분석/응용 단계
처리/탐색 단계를 통해 데이터가 정규화됐고 데이터 마트가 만들어졌으면 데이터를 분석하기 위해 임팔라 또는 제플린을 이용한다.
머하웃과 스파크ML로 군집, 분류/예측, 추천 등을 진행하고 R로 통계분석, 텐서플로로 딥러닝 모델을 만든다.
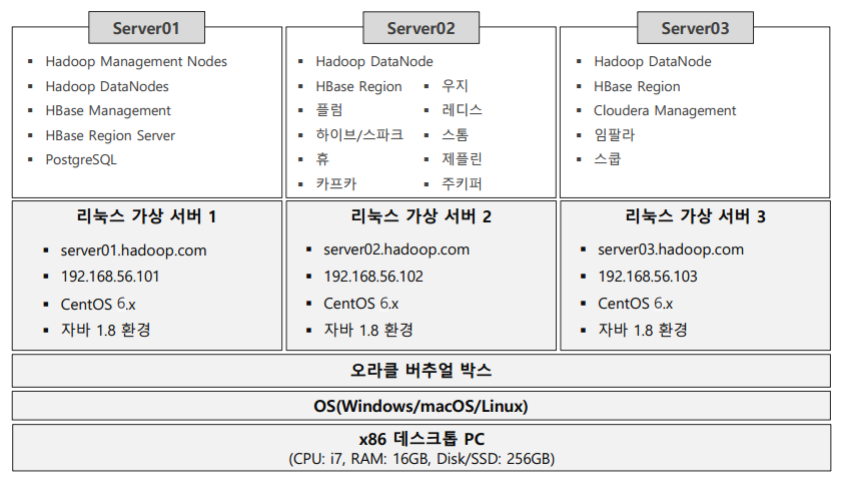
2. 하드웨어 아키텍처
먼저 윈도우 PC 위에 오라클 버추얼 박스를 설치하고
최적의 성능을 위해 가상환경에 3개의 리눅스 가상 서버를 설치할 것이다.
첫 번째 서버는 Hadoop위주
두 번째 서버는 수집~처리/탐색 위주
세 번째 서버는 분석 위주의 서버가 구성된다.
이제 각 서버에 필요한 소프트웨어를 설치할 것이다.
그림은 아래와 같다.
'데이터 엔지니어링 정복 > Hadoop Ecosystem' 카테고리의 다른 글
| [Cloudera Manager] 클라우데라 매니저 이용해서 Hadoop, Zookeeper, Yarn 설치하기 (0) | 2021.05.05 |
|---|---|
| [Virtual Machine 구성] CentOS 설치 및 환경구성, 가상서버 복제, 클라우데라 매니저 설치 (0) | 2021.05.03 |
| [Virtual Machine 구성] VirtualBox 설치하기, 네트워크 설정, 가상서버 이미지 설치, 파일럿PC 호스트 파일 수정, 클라우데라 매니저 접속하기 (0) | 2021.05.02 |
| [BigData] 개념, 특징, 활용, 빅데이터 프로젝트 (0) | 2021.05.02 |
| [Hadoop] 02/17 | 하둡과 맵리듀스, yarn의 개념, yarn 사용하기 (0) | 2021.02.17 |



