| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Linux
- BigData
- Data Engineer
- Apache Kafka
- HIVE
- java
- 자바
- 여행
- 영어
- 백준
- HDFS
- Trino
- Iceberg
- pyspark
- 프로그래머스
- bigdata engineer
- bigdata engineering
- Kafka
- 삼성역맛집
- 맛집
- Spark
- hadoop
- apache iceberg
- 코딩테스트
- 코딩
- Data Engineering
- 개발
- 알고리즘
- 코테
- 코엑스맛집
- Today
- Total
지구정복
[Hive] Hive table 개념정리 본문
Cloudera 7.1.4버전의 문서를 참고
해당 버전의 Hive버전은 3.1.3000
참고한 내용
https://cwiki.apache.org/confluence/display/Hive/Hive+Transactions#HiveTransactions-Compaction
아래 그림에 따라 Hive table에 대한 정의를 한 눈에 알 수 있다.
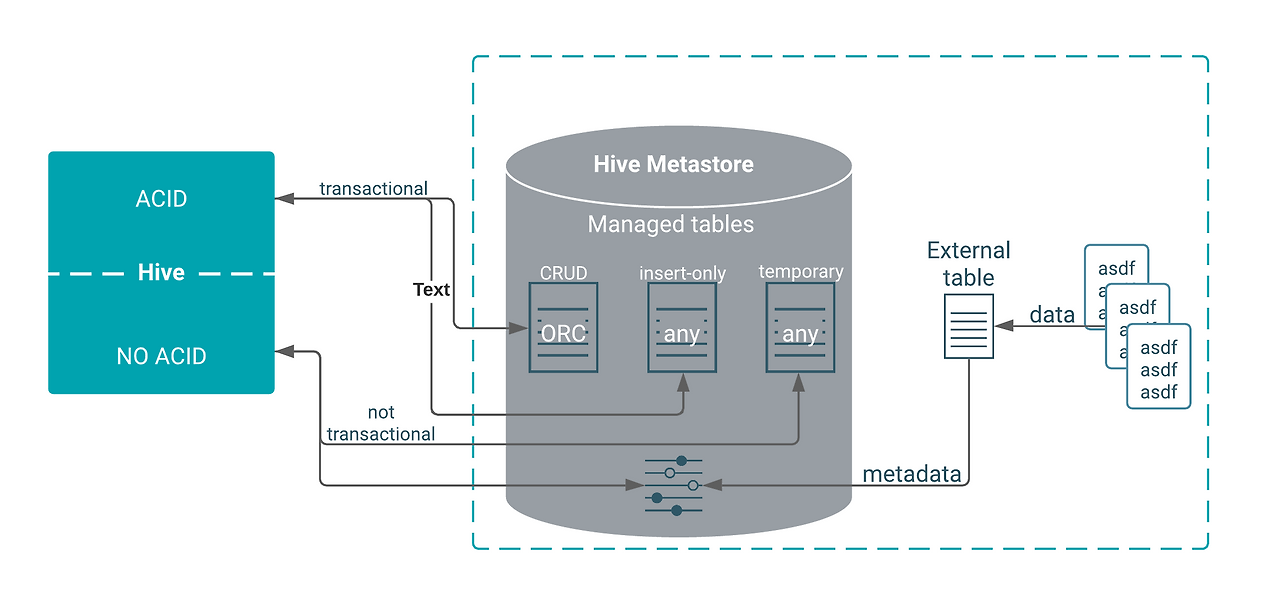
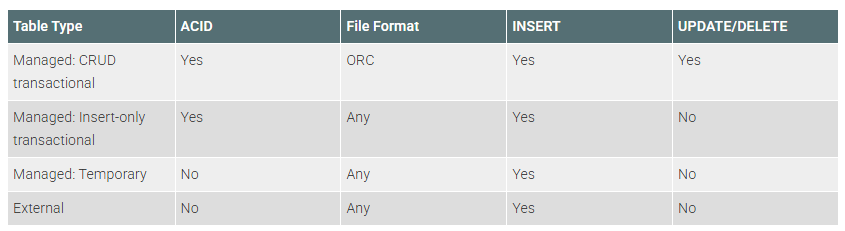
이를 표를 통해 알아보면 다음과 같다.
아래는 참고사항
-LOAD DATA... 구문은 transactional테이블에 적용되지 않는다. (This was not properly enforced until HIVE-16732)
-Manged CRUD테이블을 제외한 나머지 테이블 유형에서는 DELETE 나 UPDATE문으로 데이터를 지울 수 없지만
DROP PARTITION을 이용하면 비슷한 효과로 데이터를 지울 수 있다.
Table storage formats
Managed CRUD테이블의 경우 무조건 ORC 포맷이어야 한다.
반면에 Managed: Insert-only의 경우 아무 파일 포맷도 가능하다.
하이브는 기본값으로 ORC를 사용한다.
그러나 다른 파일 포맷일 경우 오로지 Insert만 가능한 insert-only테이블로 생성된다.
External tables
external table은 하이브에서 관리되지 않는다.
file로 가지고 있는 데이터를 하이브 테이블화하고 싶을 경우 사용한다.
그러나 아래 내용들은 지원되지 않는다.
- Query cache
- Materialized views, except in a limited way
- Automatic runtime filtering
- File merging after insert
- ARCHIVE, UNARCHIVE, TRUNCATE, MERGE, and CONCATENATE. These statements only work for Hive Managed tables.
또한 Drop시 하이브에선 Metastore에서 스키마만 드랍되고 실제 데이터는 남아있게된다.
만약에 데이터도 같이 드랍되게 하고 싶다면 아래 설정을 적용하면 된다.
external.table.purge property to true
Locating Hive tables and changing the location
기본적으로 HDFS의 아래 경로를 따른다.
- /warehouse/tablespace/managed/hive
- /warehouse/tablespace/external/hive
테이블이 매니지드인지 익스터널인지 확인하려면 아래 명령어 사용한다.
show create table tbl_name;
describe extended tbl_name;
익스터널 테이블의 경우 HDFS의 권한도 확인해야하므로
Ranger나 HDFS ACLs를 미리 확인한다.
Create a CRUD transactional table
CRUD가 가능한 Manged CRUD테이블을 만들고 싶으면 그냥 아래와 같이 만들면된다.
이러면 insert, update, delete, merge가 가능한 테이블이 생성된다.
CREATE TABLE T(a int, b int);
이때 default file format은 hive의 아래 설정들에 의해 적용된다.
아래 설정들의 값이 ORC로 되어있어야 한다.
hive.default.fileformat : Create external table시 적용됨(External table용)
hivedefault.fileformat.managed : create table시 적용됨(Managed table용)
ORC로 되어있지 않을 경우 Create문에 stored as ORC 문구를 추가해야한다.
또한 아래 설정들도 확인한다.
Client Side
- hive.support.concurrency – true
- hive.enforce.bucketing – true (Not required as of Hive 2.0)
- hive.exec.dynamic.partition.mode – nonstrict
- hive.txn.manager – org.apache.hadoop.hive.ql.lockmgr.DbTxnManager
Server Side (Metastore)
- hive.compactor.initiator.on – true (See table below for more details)
- hive.compactor.cleaner.on – true (See table below for more details)
- hive.compactor.worker.threads – a positive number on at least one instance of the Thrift metastore service
-테이블의 버킷이 필수적으로 필요하다.
Compactor
ACID테이블의 경우 수많은 delta file이 만들어질 수 있기 때문에 delta files들을 합쳐주는 compaction작업이 필수적이다.
3가지 유형의 병합종류가 있다.
마이너 컴팩션(Minor compaction)은 기존의 델타 파일(delta files) 집합을 가져와서, 버킷(bucket)당 하나의 델타 파일로 다시 작성하는 작업입니다.
메이저 컴팩션(Major compaction)은 하나 이상의 델타 파일과 해당 버킷의 베이스 파일(base file)을 가져와서, 버킷당 새로운 베이스 파일로 다시 작성하는 작업입니다. 메이저 컴팩션은 비용이 더 많이 들지만, 훨씬 더 효과적입니다.
리밸런스 컴팩션(rebalance compaction)에 대한 더 자세한 정보는 여기에서 확인할 수 있습니다: https://cwiki.apache.org/confluence/display/Hive/Rebalance+compaction
기본은 SHOW COMPACTIONS; 쿼리로 각 테이블에 어떤 컴팩션이 일어났는지 히스토리를 확인할 수 있다.
컴팩션을 바꾸려면 아래와 같이 변경가능
| -- MINOR Compaction 실행 ALTER TABLE my_table COMPACT 'MINOR'; -- MAJOR Compaction 실행 ALTER TABLE my_table COMPACT 'MAJOR'; |
Create an insert-only transactional table
update, delete, merge문이 필요없고 Insert만 필요할 경우 Managed Insert-only Table을 만들면 된다.
아래는 ORC파일 포맷일 경우 insert-only table을 만드는 방법이다.
ORC일 경우 'transactional_properties'='insert_only' 이 문구를 넣어주지 않으면 Managed CRUD 테이블이 만들어진다.
CREATE TABLE T2(a int, b int)
STORED AS ORC
TBLPROPERTIES ('transactional'='true',
'transactional_properties'='insert_only');
만약 ORC파일 포맷이 아닐 경우 'transactional_properties'='insert_only' 이 문구 없이 그냥 아래처럼 만들면 된다.
CREATE TABLE T3(a int, b int)
STORED AS TEXTFILE;
ORC포맷이 아닐 경우 자동으로 'transactional_properties'='insert_only' 문구가 추가되기 때문에 수동으로 추가하지 않아도 된다.
Create, use, and drop an external table
익스터널 테이블의 경우 하이브 메타스토어는 단순히 스키마만 관리한다.
익스터널 테이블 사용시 아래 내용들을 숙지해야한다.
- Ranger에서 HDFS에 저장된 데이터 접근되도록 적절한 권한 설정
- HDFS 에서도 해당 데이터 디렉터리에 적절한 ACLs권한 설정
- Create external 쿼리시 LOCATION구문 추가
- external table을 DROP TABLE시 메타스토어의 스키마 정보만 Drop되고 실제 HDFS에 있는 데이터는 삭제안됨
만약 HDFS에 아래와 같은 csv파일 존재한다고 하면
1,jane,doe,senior,mathematics 2,john,smith,junior,engineering
아래와 같이 external table생성한다.
CREATE EXTERNAL TABLE IF NOT EXISTS names_text(
student_ID INT,
FirstName STRING,
LastName STRING,
year STRING,
Major STRING)
COMMENT 'Student Names' ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE LOCATION '/user/andrena';
만약 해당 external table을 Managed CRUD테이블로 옮기고 싶다면 다음 절차를 진행
Managed CRUD테이블 생성
CREATE TABLE IF NOT EXISTS Names(
student_ID INT,
FirstName STRING,
LastName STRING,
year STRING,
Major STRING)
COMMENT 'Student Names';
External table데이터를 Managed CRUD테이블로 이동
INSERT OVERWRITE TABLE Names SELECT * FROM names_text;
external table drop
DROP TABLE names_text;
HDFS에 데이터는 여전히 남아있음
만약 HDFS데이터도 같이 드랍하고 싶으면 아래 쿼리 실행 후 DROP하면 된다.
ALTER TABLE addresses_text SET TBLPROPERTIES ('external.table.purge'='false');
Convert a managed, non-transactional table to external
아래 쿼리를 통해 단순한 Managed table(transactional옵션값 없는 테이블)은 external table로 변환이 가능하다.
transactional=true인 테이블은 external table로 변환할 수 없다.
ALTER TABLE ... SET TBLPROPERTIES('EXTERNAL'='TRUE','external.table.purge'='true')
Using constraints
아래 글 참고
Hive 3 ACID transactions
Hive Managed transactional 테이블의 경우 delta file을 사용하여 이를 구현한다.
먼저 insert-only경우부터 살펴본다.
Atomicity and isolation in insert-only tables
insert-only인 테이블을 아래와 같이 만든다.
CREATE TABLE tm (a int, b int) TBLPROPERTIES
('transactional'='true', 'transactional_properties'='insert_only')위와 같이 테이블을 생성하면 기본적으로 base디렉터리가 생성된다.
/user/hive/warehouse/tm/base_0000001
그리고 아래와 같이 데이터를 insert하는데 두 번째 쿼리는 일부터 fail되도록 한다.
INSERT INTO tm VALUES(1,1);
INSERT INTO tm VALUES(2,2); // Fails
INSERT INTO tm VALUES(3,3);
매번 write operation마다 하이브는 delta 디렉터리를 생성하고 그 안에 data file을 쓴다. (이를 delta file)
이 delta file에는 write IDs, transaction ID들이 적혀있다.
실제 HDFS 테이블 디렉터리를 보면 다음과 같다.
tm
___ base_0000001
___ delta_0000001_0000001_0000
└── 000000_0
___ delta_0000002_0000002_0000 //Fails
└── 000000_0
___ delta_0000003_0000003_0000
└── 000000_0
Table이 읽힐 때는 두 번째 fail된 delta file은 읽지 않는다.
이번엔 Managed CRUD테이블의 경우를 살펴본다.
Atomicity and isolation in CRUD tables
테이블을 만든다.
CREATE TABLE acidtbl (a INT, b STRING);
위와 같이 테이블을 생성하면 기본적으로 base디렉터리가 생성된다.
/user/hive/warehouse/acidtbl/base_0000001
show create table로 속성들을 살펴보면 다음과 같다.
| +----------------------------------------------------+ | createtab_stmt | +----------------------------------------------------+ | CREATE TABLE `acidtbl`( | | `a` int, | | `b` string) | | ROW FORMAT SERDE | | 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' | | STORED AS INPUTFORMAT | | 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' | | OUTPUTFORMAT | | 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat' | | LOCATION | | 's3://myserver.com:8020/warehouse/tablespace/managed/hive/acidtbl' | | TBLPROPERTIES ( | | 'bucketing_version'='2', | | 'transactional'='true', | | 'transactional_properties'='default', | | 'transient_lastDdlTime'='1555090610') | +----------------------------------------------------+ |
하이브는 데이터를 in-place 업데이트/딜리트 하지 않고 append한다.
즉, 데이터가 수정되거나 삭제되거나하면 기존 데이터를 바꾸는 것이 아니라 변경된 데이터만 새롭게 쓰고,
테이블을 읽을 때 수정된 데이터를 읽는다.
예를 들면 아래와 같이 insert, delete, update를 하는 경우를 살펴본다.
아래처럼 insert를 하면 delta file이 만들어지고 그 안에 row ID가 적힌다.
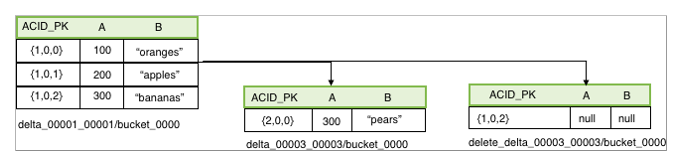
| INSERT INTO acidtbl (a,b) VALUES (100, "oranges"), (200, "apples"), (300, "bananas"); |
즉, HDFS에 delta_00001_00001/bucket_0000 디렉터리가 만들어지고, 그 안에 data file(=delta file)이 생성된다.

이번엔 아래처럼 delete쿼리를 실행하면 새로운 delta 디렉터리와 파일이 생성된다.
delete_delta_00002_00002/bucket_0000
| DELETE FROM acidTbl where a = 200; |

마지막으로 update쿼리를 실행하면 다음과 같다.
| UPDATE acidTbl SET b = "pears" where a = 300; |
새로운 row ID를 가지는 delta file이 생성되고( delete_delta_00003_00003/bucket_0000 ) 그 안에 update된 데이터 내용이 적혀있다.