
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- pyspark
- bigdata engineer
- 코딩테스트
- 코엑스맛집
- BigData
- Data Engineering
- 코테
- 백준
- 코딩
- Spark
- 자바
- java
- 영어
- 개발
- HIVE
- 여행
- 프로그래머스
- bigdata engineering
- Trino
- Apache Kafka
- Kafka
- 맛집
- apache iceberg
- HDFS
- Linux
- hadoop
- 알고리즘
- Data Engineer
- Iceberg
- 삼성역맛집
- Today
- Total
지구정복
[Spark] Spark Streaming (DStreams) 기본 개념 본문
공식 문서를 번역한 글입니다.
버전은 Spark 3.5.5 기준
https://spark.apache.org/docs/latest/streaming-programming-guide.html
1. Note
이제는 Spark Streaming은 레거시이고 사용되지 않는다.
신 Spark Structured Streaming가 사용된다.
프로그래밍 가이드는 아래를 참고한다.
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
2. Overview
다양한 소스(ex: Kafka, Kinesis, TCP sockets, ETC)에서 오는 실시간성 데이터들을 복잡한 알고리즘이나 여러가지 Functions들(ex: map, reduce, join, window, etc)을 사용해서 처리한다.
최종적으로 이렇게 처리된 실시간 데이터들은 HDFS, Databases, Dashboards등에 적재된다.

내부적으로는 아래와 같이 동작한다.
Spark Steaming은 실시간 데이터를 받은 뒤 이 데이터들을 단위로 쪼갠 뒤 처리한다.

Spark Streaming은 Discretized Stream 혹은 DStream이라고 부르는 추상화를 제공하고, DStream은 실시간 데이터를 의미한다.
그리고 이러한 DStream도 결국엔 RDD들의 시퀀스이다.
3. Basic Concepts
3.1. Linking
Spark Streaming을 사용하기 위해선 Maven저장소로부터 필요한 패키지를 사용하도록 해줘야 한다.
아래 내용을 Maven 프로젝트에 추가한다.
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.5.5</version>
<scope>provided</scope>
</dependency>
또한 Kafka나 Kinesis의 데이터를 가져오기 위해서 아래 Artifact도 추가해줘야 한다.
| Source | Artifact |
| Kafka | spark-streaming-kafka-0-10_2.12 |
| Kinesis | spark-streaming-kinesis-asl_2.12 [Amazon Software License] |
3.2. Initializing StreamingContext
기존 SparkContext처럼 Spark Streaming사용하기 위해서는 StreamingContext 객체가 생성되어야 한다.
아래는 python 예시이다.
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
sc = SparkContext(master, appName)
ssc = StreamingContext(sc, 1)
#word count example
# Create a DStream that will connect to hostname:port, like localhost:9999
lines = ssc.socketTextStream("localhost", 9999)
# Split each line into words
words = lines.flatMap(lambda line: line.split(" "))
# Count each word in each batch
pairs = words.map(lambda word: (word, 1))
wordCounts = pairs.reduceByKey(lambda x, y: x + y)
# Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.pprint()
ssc.start() # Start the computation
ssc.awaitTermination() # Wait for the computation to terminate
appname은 Spark Job의 이름이 될 것이고, master는 사용중인 Resource Manager명이 들어간다.(YARN, Mesos, local[*])
local[*]은 로컬모드로 사용한다는 의미이다.
그리고 batch interval도 설정해야 되는데 이 값은 latency requirements(지연시간 요구사항)와 클러스터의 리소스를 고려해서 정해야 한다.
StreamingContext객체 생성이후엔 아래 작업들을 진행한다.
1. Input되는 DStreams 데이터를 위해 Input Sources를 정의한다.
2. DStreams를 처리하기 위한 transformation이나 output operation들을 정의한다.
3. streamingContext.start()를 통해 데이터를 받고 처리를 시작한다.
4. streamingContext.awaitTerminator()를 통해 처리 작업이 종료될 때까지 기다린다.
(종료되는 조건은 사용자가 수동으로 종료했거나 처리 작업중 Error가 발생하면 종료된다.)
5. streamingContext.stop() 을 통해서 수동으로 종료할 수 있다.
여기서 알아야 할 점이 있다.
-일단 context객체가 시작되면 새로운 처리 코드들은 추가하거나 적용할 수 없다.
-일단 context객체가 종료되면 다시 시작될 수 없다.
-오로지 하나의 StreamingContext객체만 해당 Spark JVM에서 실행될 수 있다.
-stop()명령은 StreamingContext 객체뿐만 아니라 SparkContext객체도 종료시킨다.
만약 StreamingContext만 종료시키고 싶으면 아래처럼 사용한다.
| streamingContext.stop( stopSparkContext = false ) |
-SparkContext는 이전 StreamingContext 객체가 종료됐다면 여러 번 StreamingContext를 생성할 수 있다.
3.3. Discretized Streams (DStreams)
DStreams는 연속적인 데이터흐름을 의미한다.(실시간 데이터)
DStream는 연속적인 RDD의 흐름을 의미하고 Spark에서 RDD는 불변하고 분산된 데이터 셋을 의미한다.
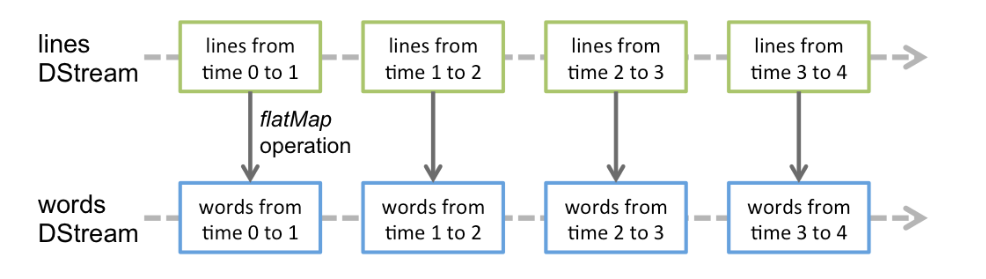
DStream에 있는 각 RDD는 아래 그림과 같이 특정 interval를 포함하고 있다.

어떠한 Operation이 DStream에 적용되면 아래와 같이 새로운 DStream이 된다.
아래는 위 예시에서 처음 TCP Socket으로부터 들어오는 데이터를 lines라는 DStream에 저장하고,
flatMap이란 operation을 적용하여 words라는 DStream으로 만든 과정을 보여준다.
3.4. Input DStreams and Receivers
Input DStream이란 데이터 소스로부터 받게된 Input Data의 Stream을 의미한다.
아까 위 Word Count예제에서 lines를 의미한다.
일반적으로 Spark Streaming에선 두 가지 built-in Streaming Sources를 제공한다.
* Basic Sources: Sources directly available in the StreamingContext API. Examples: file systems, and socket connections.
* Advanced sources: Sources like Kafka, Kinesis, etc. are available through extra utility classes.
These require linking against extra dependencies as discussed in the linking section.
만약 여러 군데의 Sources로부터 Input DStreams를 동시에 받고 싶다면 여러 개의 Input DStreams를 정의하면 된다.
하지만 주의할 점은 Spark Executor가 이러한 Input DStreams를 위해 하나 이상의 CPU Cores를 계속 사용할텐데 원활한 데이터 처리를 위해서는 Spark Streaming Application의 경우 충분한 리소스가 제공되어야 한다.
-Points to remember
* Spark Streaming을 local로 사용할 때 'local' or 'local[1]'을 사용하면 안 된다.
이것은 오직 하나의 thread로 Spark Job을 실행한다는 의미인데 여기서 Input DStreams을 받게되면 이 thread가 receiver역할을 하게된다. 그러면 다른 데이터 처리를 할 thread가 없게된다.
그래서 Local 실행한다면 local[n]으로 설정해줘야 한다. 여기서 n은 receiver개수보다 커야한다.
n > number of receivers
3.4.1. Basic Sources
3.4.1.1. File Streams
HDFS를 포함하여 파일 시스템으로부터 파일을 읽기 위해서 DStream 은 다음과 같이 만들어진다.
StreamingContext.fileStream[KeyClass, ValueClass, InputFormatClass]
이때 File streams는 receiver가 필요없기 때문에 receiver를 위한 core는 필요없다.
또한 Python에서는 간단한 text files는 아래 메서드를 사용하면 된다.
Python에서는 fileStream 메서드는 사용불가해서 textFileStream을 사용한다.
| StreamingContext.textFileStream(dataDirectory) |
다른 언어에서 text파일 이외의 데이터를 읽을 때는 fileStream을 사용하면 된다.
3.4.1.2. How Directories are Monitored
-"hdfs://namenode:8040/logs/"와 같이 간단한 디렉터리는 모니터링된다.
해당 경로에 아래에 있는 모든 파일들은 모니터링 된다.
-POSIX glob pattern 사용가능하다. 따라서 "hdfs://namenode:8040/logs/2017/*"같이 해당 패턴을 만족하는 파일 목록들은 모니터링 된다.
-모든 파일들은 같은 포맷이어야 한다.
-파일을 모니터링할 때 생성시간이 아니라 수정시간으로 인식한다.
-모니터링된 후 DStreams데이터 처리가 되면 한번 읽었던 파일은 다음에 무시된다.
-파일이 많을수록 스캔하는데 오래 걸린다.
-와일드카드를 사용하여 "hdfs://namenode:8040/logs/2016-*"와 같이 디렉터리 경로를 설정하고 실제 디렉터리의 이름을 해당 경로에 맞게 변경하면 모니터링되는 디렉터리 목록에 해당 디렉터리가 추가됩니다.
그리고 그 안에 있는 파일들중 수정시간이 변경된 파일들만 현재 window의 스트림에 포함된다.
-FileSystem.setTimes()로 해당 경로에 파일의 타임스탬프를 수정하면 다음번 window처리때 해당 파일을 처리하게 된다.
3.4.1.3. 데이터 소스로서의 객체 저장소 사용
HDFS와 같은 “완전한” 파일 시스템은 출력 스트림이 생성되자마자 파일의 수정 시간을 설정하는 경향이 있습니다.
파일이 열리면, 데이터가 완전히 작성되기 전에도 DStream에 포함될 수 있으며, 이후 같은 윈도우 내에서 파일에 대한 업데이트는 무시될 수 있습니다.
즉, 변경 사항이 누락되고 스트림에서 데이터가 생략될 수 있습니다.
변경 사항이 윈도우 내에서 수집되도록 보장하려면, 파일을 모니터링되지 않는 디렉토리에 작성한 다음, 출력 스트림이 닫힌 직후에 해당 파일을 목적지 디렉토리로 이름을 변경해야 합니다.
이름이 변경된 파일이 생성된 윈도우 동안 스캔된 목적지 디렉토리에 나타나면, 새로운 데이터가 수집됩니다.
반대로, Amazon S3와 Azure Storage와 같은 객체 저장소는 데이터가 실제로 복사되기 때문에 보통 느린 이름 변경 작업을 수행합니다.
또한, 이름 변경된 객체는 rename() 작업의 시간이 수정 시간으로 설정될 수 있으므로, 원래 생성 시간이 암시하던 윈도우의 일부로 간주되지 않을 수 있습니다.
대상 객체 저장소의 타임스탬프 동작이 Spark Streaming이 기대하는 동작과 일치하는지를 검증하기 위해서는 신중한 테스트가 필요합니다.
선택한 객체 저장소를 통해 스트리밍 데이터를 작성하는 적절한 전략이 목적지 디렉토리에 직접 작성하는 것일 수 있습니다.
이 주제에 대한 자세한 내용은 Hadoop 파일 시스템 명세서를 참조하십시오.
3.4.1.4. Queue of RDDs as a Stream
streamingContext.queueStream(queueOfRDDs)를 사용하여 큐를 가지는 DStreams를 만들 수 있다.
해당 큐에 유입되는 각 RDD는 DStream에서 하나의 배치 데이터로 처리된다.
보통 테스트용으로만 사용된다.
3.4.2. Advanced Sources
Spark 3.5.5 기준으로, 아래 출처 중 Kafka와 Kinesis가 Python API에서 이용 가능합니다.
이러한 출처 카테고리는 외부 비-Spark 라이브러리와의 인터페이스가 필요하며, 그 중 일부는 복잡한 종속성을 가집니다(예: Kafka).
따라서 종속성의 버전 충돌과 관련된 문제를 최소화하기 위해, 이러한 출처에서 DStream을 생성하는 기능이 별도의 라이브러리로 이동되었으며, 필요한 경우 명시적으로 연결할 수 있습니다.
이러한 고급 출처는 Spark 쉘에서 사용할 수 없음을 주의하시기 바랍니다.
따라서 이러한 고급 출처에 기반한 애플리케이션은 쉘에서 테스트할 수 없습니다.
만약 꼭 Spark 쉘에서 사용하고자 한다면, 해당하는 Maven 아티팩트의 JAR 파일과 그 종속성을 다운로드하여 클래스 경로에 추가해야 합니다.
다음은 이러한 고급 출처의 몇 가지 예입니다.
Kafka: Spark Streaming 3.5.5는 Kafka 브로커 버전 0.10 이상과 호환됩니다. 자세한 내용은 Kafka 통합 가이드를 참조하세요.
Kinesis: Spark Streaming 3.5.5는 Kinesis 클라이언트 라이브러리 1.2.1과 호환됩니다. 자세한 내용은 Kinesis 통합 가이드를 참조하세요.
3.4.3. Custom Sources
현재 Python에서는 지원되지 않습니다.
Input DStream은 사용자 정의 데이터 소스에서 생성될 수 있습니다.
이를 위해서는 사용자 정의 수신기(user-defined receiver)를 구현하면 됩니다(다음 섹션에서 이에 대한 설명이 있습니다).
이 수신기는 사용자 정의 소스에서 데이터를 수신하고 이를 Spark로 푸시할 수 있도록 합니다.
자세한 내용은 사용자 정의 수신기 가이드를 참고하십시오.
3.4.4. Receiver Reliability
신뢰성(reliability)관련해서 두 가지 종류의 데이터 소스가 존재한다.
데이터 소스들(ex: kafka)는 전송된 데이터가 잘 전송됐는지 확인하는(acknowledged) 기능이 있다.
만약 이러한 신뢰성 있는 데이터 소스들로부터 데이터를 받는 경우 그 받은 데이터가 정확하다고 인식한다.
이것은 어떠한 문제나 실패로 인해 데이터가 유실되는 것을 방지한다.
그래서 아래 두 가지 receiver 종류가 있다.
1. Reliable Receiver: 신뢰할 수 있는 수신기는 데이터가 수신되어 Spark에 복제와 함께 저장되었을 때, 신뢰할 수 있는 데이터 소스에 확인 응답(acknowledgment)을 보냅니다.
2. Unreliable Receiver: 신뢰할 수 없는 수신기는 출처에 확인 응답을 보내지 않습니다.
이는 확인 응답을 지원하지 않는 데이터 소스에 사용할 수 있으며, 확인 응답의 복잡성에 들어가고 싶지 않거나 필요하지 않은 경우 신뢰할 수 있는 출처에도 사용할 수 있습니다.
3.5. Transformations on DStreams
RDD와 유사하게 transformations작업은 Input DStream를 수정시킬 수 있다.
아래는 지원되는 Transformations작업들이다.
| Transformation | Meaning |
| map(func) | Return a new DStream by passing each element of the source DStream through a function func. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items. |
| filter(func) | Return a new DStream by selecting only the records of the source DStream on which func returns true. |
| repartition(numPartitions) | Changes the level of parallelism in this DStream by creating more or fewer partitions. |
| union(otherStream) | Return a new DStream that contains the union of the elements in the source DStream and otherDStream. |
| count() | Return a new DStream of single-element RDDs by counting the number of elements in each RDD of the source DStream. |
| reduce(func) | Return a new DStream of single-element RDDs by aggregating the elements in each RDD of the source DStream using a function func (which takes two arguments and returns one). The function should be associative and commutative so that it can be computed in parallel. |
| countByValue() | When called on a DStream of elements of type K, return a new DStream of (K, Long) pairs where the value of each key is its frequency in each RDD of the source DStream. |
| reduceByKey(func, [numTasks]) | When called on a DStream of (K, V) pairs, return a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function. Note: By default, this uses Spark's default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config property spark.default.parallelism) to do the grouping. You can pass an optional numTasks argument to set a different number of tasks. |
| join(otherStream, [numTasks]) | When called on two DStreams of (K, V) and (K, W) pairs, return a new DStream of (K, (V, W)) pairs with all pairs of elements for each key. |
| cogroup(otherStream, [numTasks]) | When called on a DStream of (K, V) and (K, W) pairs, return a new DStream of (K, Seq[V], Seq[W]) tuples. |
| transform(func) | Return a new DStream by applying a RDD-to-RDD function to every RDD of the source DStream. This can be used to do arbitrary RDD operations on the DStream. |
| updateStateByKey(func) | Return a new "state" DStream where the state for each key is updated by applying the given function on the previous state of the key and the new values for the key. This can be used to maintain arbitrary state data for each key. |
3.5.1. UpdateStateByKey Operation
updateStateByKey 를 사용하면 계속해서 유입되는 데이터를 활용해서 DStream의 특정 상태를 유지할 수 있게해준다.
예를 들어 실시간으로 웹사이트 방문자 수와 같이 실시간 데이터를 카운트하거나 계속 업데이트하고 싶을 때 사용할 수 있다.
사용하기 위해서 아래 단계를 거친다.
1. 상태 정의 (Define the state): 상태는 임의의 데이터 타입이 될 수 있습니다.
2. 상태 업데이트 함수 정의 (Define the state update function): 입력 스트림의 이전 상태와 새로운 값을 사용하여 상태를 업데이트하는 방법을 함수로 지정합니다.
아래는 예시이다.
def updateFunction(newValues, runningCount):
if runningCount is None:
runningCount = 0
return sum(newValues, runningCount) # add the new values with the previous running count to get the new count
#the pairs DStream containing (word, 1) pairs
runningCounts = pairs.updateStateByKey(updateFunction)
이러면 계속 유입되는 데이터를 확인해서 runningCounts는 계속 상태를 유지하면서 값이 변경된다.
한 가지 알아야할 점은 updateStateByKey는 checkpoint 디렉터리가 필요하다.
3.5.2. Transform Operation
Spark RDD에서 사용했던 기본적인 Transform 작업들도 DStreams에서 사용할 수 있다.
예를 들어서 계속 유입되는 Input DStreams데이터에 다른 데이터셋과 join하는 작업은 위 DStream API에는 적혀있지 않지만 기존 RDD transform작업을 통해서 구현할 수 있다.
spamInfoRDD = sc.pickleFile(...) # RDD containing spam information
# join data stream with spam information to do data cleaning
cleanedDStream = wordCounts.transform(lambda rdd: rdd.join(spamInfoRDD).filter(...))
알아야 할 점은 transform에 적용되는 함수는 input DStream의 각 배치에 유입되는 데이터마다 적용된다.
3.5.3. Window Operations
일단 Window의 개념을 알아야 한다.
window는 입력된 DStream에서 데이터를 특정 시간 범위(윈도우) 동안 유지하며, 이 기간 동안의 데이터에 대한 집계 연산을 가능하게 한다.
두 가지로 나눠진다.
고정 윈도우: 특정 시간 범위에서의 데이터를 고정적으로 집계합니다 (예: 매 1분마다 최근 5분 데이터 집계).
슬라이딩 윈도우: 윈도우가 주기적으로 겹쳐지면서 데이터를 집계합니다. 즉, 이전 윈도우의 일부 데이터가 다음 윈도우에 포함될 수 있습니다.
예제를 확인한다.
만약 아래와 같은 코드가 있다고 하자.
# Create a window for 30 seconds, sliding every 10 seconds
windowedStream = inputDStream.window(30, 10)
첫 번째 인자는 30초 동안의 데이터를 집계한다.
두 번째 인자는 데이터는 10초마다 슬라이드(=나눠진다) 된다. 즉, 새로운 window는 매 10초마다 생성된다.
조금 더 설명을 하면
첫 번째 window: 0~30초 데이터가 포함된다.
두 번째 window: 10~40초 데이터가 포함된다.
세 번째 window: 20~50초 데이터가 포함된다.
이렇게 되면 각 window마다 overlapping되는 부분들이 존재한다.
만약 overlapping되지 않게 하려면 아래와 같이 slide부분을 window interval과 같게 한다.
# Create a window for 30 seconds with no overlapping
windowedStream = inputDStream.window(30, 30)
만약 Time interval이 1초일 경우 1초마다 DStream을 처리하는 코드가 실행된다.
하지만 Sliding Window를 사용하면 각 Time interval을 슬라이드해서 1초마다 처리되는게 아니라 아래 그림처럼 3,4,5초를 묶어서 5초 때에 실행시킬 수 있다.
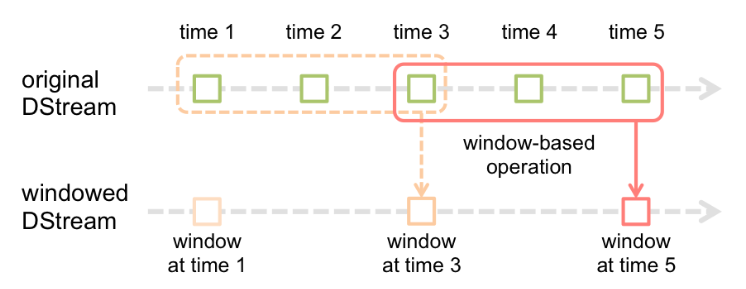
window operation에는 두 가지 parameters가 있다.
* window length - The duration of the window (3 in the figure).
* sliding interval - The interval at which the window operation is performed (2 in the figure).
위 두 매개변수는 원본 DStream의 batch interval(time interval)의 배수여야 한다.
이제 이전 워드카운트 예제에서 만약 최근 30초에 대해 10초마다 데이터를 처리한다고 하면
이를 위해서는 (word, 1)데이터를 가지는 pairs DStream에 reduceByKey를 실행해야 하는데
window설정을 위해선 아래 메서드를 사용해야 한다.
| reduceByKeyAndWinddow() |
# Reduce last 30 seconds of data, every 10 seconds
windowedWordCounts = pairs.reduceByKeyAndWindow(lambda x, y: x + y, lambda x, y: x - y, 30, 10)
사용가능한 메서드들은 다음과 같다.
| Transformation | Meaning |
| window(windowLength, slideInterval) | Return a new DStream which is computed based on windowed batches of the source DStream. |
| countByWindow(windowLength, slideInterval) | Return a sliding window count of elements in the stream. |
| reduceByWindow(func, windowLength, slideInterval) | Return a new single-element stream, created by aggregating elements in the stream over a sliding interval using func. The function should be associative and commutative so that it can be computed correctly in parallel. |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function func over batches in a sliding window. Note: By default, this uses Spark's default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config property spark.default.parallelism) to do the grouping. You can pass an optional numTasks argument to set a different number of tasks. |
| reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | A more efficient version of the above reduceByKeyAndWindow() where the reduce value of each window is calculated incrementally using the reduce values of the previous window. This is done by reducing the new data that enters the sliding window, and “inverse reducing” the old data that leaves the window. An example would be that of “adding” and “subtracting” counts of keys as the window slides. However, it is applicable only to “invertible reduce functions”, that is, those reduce functions which have a corresponding “inverse reduce” function (taken as parameter invFunc). Like in reduceByKeyAndWindow, the number of reduce tasks is configurable through an optional argument. Note that checkpointing must be enabled for using this operation. |
| countByValueAndWindow(windowLength, slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, Long) pairs where the value of each key is its frequency within a sliding window. Like in reduceByKeyAndWindow, the number of reduce tasks is configurable through an optional argument. |
3.5.4. Join Operations
DSterams는 다른 DStreams와 join하기 쉽다.
아래는 예제이고, leftOuterJoin, rightOuterJoin, fullOuterJoin.leftOuterJoin, rightOuterJoin, fullOuterJoin 들도 사용할 수 있다.
stream1 = ...
stream2 = ...
joinedStream = stream1.join(stream2)
또한 window에 따라 join도 가능하다.
dataset = ... # some RDD
windowedStream = stream.window(20)
joinedStream = windowedStream.transform(lambda rdd: rdd.join(dataset))
3.6. Output Operations on DStreams
Output Operations는 DStreams의 데이터를 외부 시스템에 저장되도록 해준다.
이러한 Output Operation작업들이 실행되면 실제로 DStreams에 적용된 transformations 작업들이 실행된다.
RDD의 action작업 때 transformation작업이 실제 이루어지는 것과 동일하다.
현재는 다음과 같은 Output Operation작업들이 존재한다.
| Output Operation | Meaning |
| print() | Prints the first ten elements of every batch of data in a DStream on the driver node running the streaming application. This is useful for development and debugging. |
| Python API This is called pprint() in the Python API. | |
| saveAsTextFiles(prefix, [suffix]) | Save this DStream's contents as text files. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]". |
| saveAsObjectFiles(prefix, [suffix]) | Save this DStream's contents as SequenceFiles of serialized Java objects. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]". |
| Python API This is not available in the Python API. | |
| saveAsHadoopFiles(prefix, [suffix]) | Save this DStream's contents as Hadoop files. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]". |
| Python API This is not available in the Python API. | |
| foreachRDD(func) | The most generic output operator that applies a function, func, to each RDD generated from the stream. This function should push the data in each RDD to an external system, such as saving the RDD to files, or writing it over the network to a database. Note that the function func is executed in the driver process running the streaming application, and will usually have RDD actions in it that will force the computation of the streaming RDDs. |
3.6.1. Design Patterns for using foreachRDD
dstream.foreachRDD 는 데이터를 외부 시스템에 보낼 수 있는 강력한 함수이다.
하지만 이 함수가 어떻게 동작하는지 정확히 이해해야 한다.
외부 시스템에 데이터를 쓰려면 외부 시스템과 연결할 수 있는 객체를 생성하고 이 객체를 통해 외부 시스템에 데이터를 전송해서 쓰게된다.
이를 위해서 개발자는 자신도 모르게 아래 코드와 같이 Spark Driver에서 연결 객체를 생성할 수도 있다. 그리고나서 Spark Executor에서 이 객체를 사용해서 외부 시스템에 RDD를 쓰려고할 수도 있다.
def sendRecord(rdd):
connection = createNewConnection() # executed at the driver
rdd.foreach(lambda record: connection.send(record))
connection.close()
dstream.foreachRDD(sendRecord)이 방법은 잘못 됐다.
왜냐하면 이를 위해서는 외부시스템 연결 객체가 직렬화돼서 Driver에서 Executor들로 보내져야하기 때문이다.
이러한 연결 객체들은 다른 서버로 전송되기 어렵기 때문이다.
따라서 직렬화 에러, 초기화 에러 등이 발생할 수 있다.
(connection object not serializable, connection object needs to be initialized at the workers)
따라서 올바른 사용방법은 각 Executor노드들에서 연결 객체가 생성되어서 사용되어야 한다.
def sendRecord(record):
connection = createNewConnection()
connection.send(record)
connection.close()
dstream.foreachRDD(lambda rdd: rdd.foreach(sendRecord))
위 코드를 살펴보면 dstream.foreachRDD(lambda rdd: rdd.foreach(sendRecord)) 이 코드에서 각 Executor노드들이 각 RDD들에 대해서 sendRecord()라는 함수를 실행하도록 한다.
그럼 각 Executor노드들은 sendRecord() 함수를 실행하게 되고, 이 함수에 connection 객체 생성 코드가 있어서 여기서 연결 객체가 생성된다.
하지만 이 방법에도 또 다른 문제점이 있는데 문제점은 바로 매 record마다 연결 객체가 생성된다는 점이다.
일반적으로 연결객체 생성은 시간과 리소스를 많이 사용하게 된다.
따라서 연결 객체를 생성하고 죽이는 과정이 연속되면 문제를 일으킬 소지가 많아지고 성능이 느려진다.
이를 해결하기 위한 좋은 방법은 rdd.foreachPartition를 사용하는 것이다.
이 함수는 연결 객체를 하나만 만들고 이를 각 RDD Partition에 있는 모든 record로 보내준다.
코드는 다음과 같다.
def sendPartition(iter):
connection = createNewConnection()
for record in iter:
connection.send(record)
connection.close()
dstream.foreachRDD(lambda rdd: rdd.foreachPartition(sendPartition))
이 함수는 많은 records에 따른 연결 객체 생성의 Overhead를 상각해준다.
마지막으로 아래 방법은 더욱 효율적이다.
connection pool을 사용하여 여러 개의 RDD/Batches에 대한 연결 객체를 재사용하여 효율적으로 사용할 수 있게 해준다.
def sendPartition(iter):
# ConnectionPool is a static, lazily initialized pool of connections
connection = ConnectionPool.getConnection()
for record in iter:
connection.send(record)
# return to the pool for future reuse
ConnectionPool.returnConnection(connection)
dstream.foreachRDD(lambda rdd: rdd.foreachPartition(sendPartition))
pool에 있는 connection객체들은 수요에 따라 지연적으로 생성되어야 하고, 일정 기간 동안 사용하지 않으면 타임아웃 되어야 한다.
알아야 할 점들
* DStreams는 Output Operation작업에 의해 실제로 지연 실행된다.
특히 DStream의 Output Operaion작업 내에 RDD Action작업이 있으면 이는 강제로 데이터처리가 이뤄지도록 한다.
따라서 애플리케이션에 출력 작업이 없거나 출력 작업으로 dstream.foreachRDD()가 있지만 그 내부에 RDD 작업이 없다면, 아무것도 실행되지 않는다. 시스템은 단순히 데이터를 수신하고 이를 폐기한다.
* 기본적으로 Output Operation은 한 번에 하나씩 실행된다.
3.7. DataFrame and SQL Operations
스트리밍 데이터에 대해 Spark Dataframe과 SQL Operations을 사용할 수 있다.
먼저 StreamingContext를 사용하는 SparkContext가 있는 SparkSession을 만든다.
Driver가 에러로 실패되면 SparkSession 은 재생성해야한다.
아래는 기존 RDD Word Count예제를 DataFrames & SQL을 사용하는 예제이다.
각 RDD는 Dataframe으로 변환가능하고 임시 테이블로 만들어서 SQL쿼리가 가능하다.
# Lazily instantiated global instance of SparkSession
def getSparkSessionInstance(sparkConf):
if ("sparkSessionSingletonInstance" not in globals()):
globals()["sparkSessionSingletonInstance"] = SparkSession \
.builder \
.config(conf=sparkConf) \
.getOrCreate()
return globals()["sparkSessionSingletonInstance"]
...
# DataFrame operations inside your streaming program
words = ... # DStream of strings
def process(time, rdd):
print("========= %s =========" % str(time))
try:
# Get the singleton instance of SparkSession
spark = getSparkSessionInstance(rdd.context.getConf())
# Convert RDD[String] to RDD[Row] to DataFrame
rowRdd = rdd.map(lambda w: Row(word=w))
wordsDataFrame = spark.createDataFrame(rowRdd)
# Creates a temporary view using the DataFrame
wordsDataFrame.createOrReplaceTempView("words")
# Do word count on table using SQL and print it
wordCountsDataFrame = spark.sql("select word, count(*) as total from words group by word")
wordCountsDataFrame.show()
except:
pass
words.foreachRDD(process)
DataFrames & SQL은 아래 링크를 참고한다.
https://spark.apache.org/docs/latest/sql-programming-guide.html
3.8. MLlib Operations
MLlib에서 제공하는 머신러닝 알고리즘을 쉽게 사용할 수도 있습니다.
우선, 스트리밍 데이터로부터 동시에 학습하고 모델을 스트리밍 데이터에 적용할 수 있는 스트리밍 머신러닝 알고리즘(예: 스트리밍 선형 회귀, 스트리밍 KMeans 등)이 있습니다.
이외에도 훨씬 더 큰 범위의 머신러닝 알고리즘에 대해 오프라인(예: 과거 데이터를 사용하여)에서 학습 모델을 학습한 후 스트리밍 데이터에 온라인으로 모델을 적용할 수 있습니다.
더 자세한 내용은 MLlib 가이드를 참조하십시오.
https://spark.apache.org/docs/latest/ml-guide.html
3.9. Caching / Persistence
RDD와 유사하게 DStreams도 스트림 데이터를 메모리에 저장할 수 있다.
즉, persist() 메서드를 사용하면 DStreams는 자동적으로 각 RDD를 메모리에 유지시킨다.
이 기능은 해당 DStream이 여러번 참조되거나 처리가 필요할 때 유용하다.
window기반의 Operations들 예를들면 reduceByWindow and reduceByKeyAndWindow and state-based operations like updateStateByKey들은 암묵적으로 이를 사용한다.
따라서 window기반 operations으로 만들어진 DStreams는 자동적으로 메모리에 유지되므로 사용자가 따로 persist()를 호출하지 않아도 된다.
그리고 네트워크를 통해 받게되는 Input Streams(예: kafka, socket등)의 기본 persistence level은 두 개 노드에 복제되도록 설정되어 있다.
RDD와 달리 DStream의 기본 Persistence level은 메모리에서 데이터가 직렬화된 상태를 유지한다는 것이다.
3.10. Checkpointing
스트리밍 애플리케이션은 24시간 7일 운영되어야 하므로 코드에러와 관련없는 실패(예: 시스템 실패, JVM충돌 등)에 대해 탄력적이어야 한다.
이를 위해선 Spark Streaming은 실패시 복구를 위해 작업 진행과정에 대한 충분한 정보들을 checkpoint해야 한다.
checkpoint에 사용되는 두 가지 종류 데이터가 있다.
* Metadata checkpointing : 스트리밍 처리를 하는 정보들을 HDFS와 같은 내결함성 저장소에 저장한다.
이는 Driver노드가 실행되는 서버의 문제가 생겼을 때 recover하기 위해서 사용된다.
Metadata에는 아래 정보들이 포함된다.
-Configuration : Spark Streaming application이 사용하고 있는 Spark Configuration들
-DStream Opertions : DStreams에 적용되는 Opertions들 정보
-Incomplete batches : 아직 처리되지 않은 batches 데이터 정보
* Data checkpointing : 만들어진 RDD를 신뢰할 수 있는 저장소에 저장.
이것은 여러 batch에 걸쳐 데이터를 결합하는 Stateful Transformation작업에 필요하다.
Stateful Transformations작업이란 이전 작업이 다음 작업에 영향을 미치는 작업들을 의미한다.
이러한 transformations작업들의 경우 만들어진 RDD는 이전 배치에서의 RDD에 의존하기 때문에 의존성 체인(dependency chain)의 길이가 시간이 지남에 따라 길어진다.
이러한 끝이없는 의존성 체인의 길이의 증가를 피하기 위해선 stateful transformations의 중간 RDD들은 주기적으로 신뢰성 있는 저장소(HDFS)에 checkpoint되어야 한다.
Driver실패에 따른 복구를 위해 metadata checkpointing은 필수적이다.
또한 stateful transformations작업들이 사용되는 경우 데이터 또는 RDD의 checkpoint도 필요하다.
3.10.1. When to enable Checkpointing
체크포인팅은 다음과 같은 요건이 있을 경우 반드시 사용되어야 한다.
-stateful transformations작업 사용시 : 스파크 프로그램에서 updateStateByKey 또는 reduceByKeyAndWindow(역함수 사용)를 사용하는 경우, 주기적인 RDD 체크포인팅을 허용하기 위해 체크포인트 디렉토리를 제공해야 한다.
-Driver 실패를 복구하기 위해 : Metadata checkpoints는 진행 정보를 복구하는 데 사용된다.
stateful transformation사용되지 않는 경우 checkpointing은 사용되지 않는다.
이 경우에 Driver실패로 인한 복구는 부분적일 것이다.(몇몇의 데이터는 유실될 수도 있다.)
보통 이런 식으로 Spark Streaming Application을 사용한다.
3.10.2. How to configure Checkpointing
Checkpointing은 내고장성 및 신뢰성 있는 파일시스템(HFDS, S3, etc)에 있는 특정 디렉터리를 설정함으로서 사용될 수 있다.
아래 명령어로 설정한다.
| streamingContext.checkpoint(checkpointDirectory) |
이렇게 설정하면 stateful transforamtions작업시 checkpointing이 된다.
아래 코드와 같이 StreamingContext를 새로 만들거나 기존 Checkpointing된 디렉터리로부터 만들 수 있다.
# Function to create and setup a new StreamingContext
def functionToCreateContext():
sc = SparkContext(...) # new context
ssc = StreamingContext(...)
lines = ssc.socketTextStream(...) # create DStreams
...
ssc.checkpoint(checkpointDirectory) # set checkpoint directory
return ssc
# Get StreamingContext from checkpoint data or create a new one
context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext)
# Do additional setup on context that needs to be done,
# irrespective of whether it is being started or restarted
context. ...
# Start the context
context.start()
context.awaitTermination()
만약 checkpointDirectory가 존재하면 context객체는 checkpoint data로부터 만들어진다.
만약 cehckpointDirectory가 존재하지만 않으면 funcitonToCreateContext 함수를 호출하여 새롭게 만든다.
또한 그냥 간단히 아래와 같이 context객체를 생성할 수 있다.
| StreamingContext.getOrCreate(checkpointDirectory, None) |
알아야 할 점은 RDD의 checkpointing은 저장시 비용이 든다. 이는 전체 잡 처리시간에 영향을 줄 수 있다.
그래서 checkpointing의 주기는 신중하게 설정되어야 한다.
작은 배치로 스트리밍 데이터를 처리하는 경우(1초주기), 매 배치마다의 checkpointing은 잡의 처리능력을 줄이게 된다.
반대로 checkpointing을 너무 안하면 linege와 task 크기가 계속 증가하므로 전체 잡에 좋지 않은 영향을 주게 된다.
RDD의 checkpointing을 필요로하는 stateful transformations는 기본적으로 10초를 주기로 한다.
이는 아래와 같이 설정할 수 있다.
| dstream.checkpoint(checkpointInterval) |
일반적으로 checkpoint 주기는 5 - 10사이의 sliding 주기(시간 주기가 아님)로 하는 게 가장 효율적이라고 한다.
3.11. Accmulators, Broadcast Variables, and Checkpoints
Accumulators와 Broadcast variables는 Spark Streaming의 Checkpoint로부터 복구되지 않는다.
따라서 만약 checkpointing을 사용중이고, accumulator나 broadcast variables를 사용중이라면 Driver가 실패로 인해 재시작되더라도 accumulator나 broadcast variables가 다시 생성되고 사용될 수 있도록 코딩을 해야 한다.
def getWordExcludeList(sparkContext):
if ("wordExcludeList" not in globals()):
globals()["wordExcludeList"] = sparkContext.broadcast(["a", "b", "c"])
return globals()["wordExcludeList"]
def getDroppedWordsCounter(sparkContext):
if ("droppedWordsCounter" not in globals()):
globals()["droppedWordsCounter"] = sparkContext.accumulator(0)
return globals()["droppedWordsCounter"]
def echo(time, rdd):
# Get or register the excludeList Broadcast
excludeList = getWordExcludeList(rdd.context)
# Get or register the droppedWordsCounter Accumulator
droppedWordsCounter = getDroppedWordsCounter(rdd.context)
# Use excludeList to drop words and use droppedWordsCounter to count them
def filterFunc(wordCount):
if wordCount[0] in excludeList.value:
droppedWordsCounter.add(wordCount[1])
False
else:
True
counts = "Counts at time %s %s" % (time, rdd.filter(filterFunc).collect())
wordCounts.foreachRDD(echo)
3.12. Deploying Applications
3.12.1. Requirements
Spark Streaming 어플리케이션을 실행하려면 아래를 따른다.
* Cluster manager 선정 : YARN, Mesos, etc
* Spark Streaming 실행을 위한 Jar파일 : 만약 spark-submit명령일 경우 필요없지만 Jar를 넘겨줘야하는 프로그램 사용시(Kafka 등등) jar파일을 제공해야 한다.
* 충분한 익스큐터들을 위한 리소스 : 만약 스트리밍 데이터의 window주기를 10분으로 했을 때 10분 동안의 데이터가 익스큐터 노드들의 메모리에 저장되게 될텐데 이를 허용할 수 있는 충분한 메모리가 있어야 한다.
* Checkpointing 설정
* write-ahead logs 설정 : Spark 1.2부터 내고장성을 위해서 도입됐다. 만약 이 기능이 켜져있다면 소스로부터 제공받은 모든 데이터는 체크포인트 디렉터리에 있는 write-ahead log에 기록된다.
이는 driver실패시 데이터 유실을 방지한다.
이 설정은 다음과 같이 킬 수 있다.
| spark.streaming.receiver.writeAheadLog.enable = true |
그러나 이 기능을 키면 수신받을 때 성능이 조금 안좋아진다.
만약 이 기능을 킨다면 Spark가 자동으로 데이터를 복제하는 기능을 끄는게 좋다.
왜냐하면 write-ahaed log가 이미 파일시스템(HDFS 등)에 의해 복제되고 있기 때문이다.
아래 설정으로 설정한다.
| StorageLevel.MEMORY_AND_DISK_SER |
만약 S3와 같이 Flusing기능을 지원하지 않는 경우에는 아래 설정들을 켜준다.
| spark.streaming.driver.writeAheadLog.closeFileAfterWrite spark.streaming.receiver.writeAheadLog.closeFileAfterWrite |
추가적으로 Spark는 I/O 암호화 기능이 켜져있으면 write-ahead log에 작성하는 데이터에 암호화를 하지 않는다.
만약 암호화된 write-ahead log파일을 원한다면 암호화가 기본적으로 제공되는 파일시스템에 저장되어야 한다.
(HDFS에는 암호화 기능이 존재한다.)
* 최대 받을 수 있는 데이터양 설정 : 만약 클러스터 리소스가 충분하지 않은데 보내지는 데이터 속도가 너무 빠르다면 제한을 설정해야 한다.
일단 기본적으로 아래 설정이 있다.
| spark.streaming.receiver.maxRate |
Kafka 사용중이라면 아래 설정으로 바로 설정할 수 있다.
| spark.streaming.kafka.maxRatePerPartition |
그리고 Spark 1.5부터는 backpressure라는 개념이 등장했고, 이는 이러한 제한 설정을 굳이 안해도 되게 해준다.
이를 설정하면 Spark Streaming이 알아서 데이터양을 파악해서 동적으로 제한을 걸어준다.
| spark.streaming.backpressure.enabled = true |
3.12.2. Upgrading Application Code
만약 기존에 실행되고 있는 Spark Application의 코드가 변경됐을 경우 처리하는 두 가지 방법이 있다.
1. 기존에 실행되고 있는 잡과 수정된 코드를 가지는 잡을 일단 동시에 실행한다.
데이터는 두 잡에 같이 보내지게 된다. 신규 애플리케이션이 정상적으로 데이터 받고 처리가 잘 된다면 기존 애플리케이션은 종료될 수 있다.
2. 기존 애플리케이션을 정상적으로 종료한다. 이때 종료되기 직전에 받은 데이터들은 완전히 처리되어야만 한다.
새로운 애플리케이션을 실행하는데 기존 애플리케이션이 종료하기 직전에 처리했던 지점부터 데이터를 받아서 처리되도록 한다.
3.13. Monitoring Applications
Spark의 모니터링 기능 외에도 Spark Streaming에 특정한 추가 기능들이 있습니다.
StreamingContext를 사용할 때, Spark 웹 UI는 추가적인 Streaming 탭을 보여주며, 이 탭에서는 실행 중인 리시버에 대한 통계(리시버가 활성인지 여부, 수신된 레코드 수, 리시버 오류 등)와 완료된 배치(배치 처리 시간, 대기 지연 등)에 대한 정보를 확인할 수 있습니다.
이는 스트리밍 애플리케이션의 진행 상황을 모니터링하는 데 사용될 수 있습니다.
웹 UI의 다음 두 가지 메트릭은 특히 중요합니다:
* 처리 시간: 데이터 배치당 처리하는 데 걸리는 시간.
* 스케줄링 지연: 배치가 이전 배치의 처리가 완료되기를 기다리는 동안 대기하는 시간.
배치 처리 시간이 지속적으로 배치 간격보다 길거나 대기 지연이 계속 증가하는 경우, 이는 시스템이 배치를 생성되는 만큼 빠르게 처리하지 못하고 있다는 것을 나타냅니다. 이러한 경우, 배치 처리 시간을 줄이는 것을 고려하십시오.
Spark Streaming 프로그램의 진행 상황은 StreamingListener 인터페이스를 사용하여 모니터링할 수도 있으며, 이를 통해 리시버 상태와 처리 시간을 확인할 수 있습니다.
단, 이는 개발자 API이며 앞으로 개선될 가능성이 높습니다(즉, 더 많은 정보가 보고될 수 있습니다).
3.14. Performance Tuning
클러스터에서 Spark Streaming 애플리케이션의 최상의 성능을 끌어내기 위해서는 약간의 조정이 필요합니다.
이 섹션에서는 애플리케이션의 성능을 향상시키기 위해 조정할 수 있는 여러 매개변수와 설정을 설명합니다.
전반적으로 고려해야 할 두 가지는 다음과 같습니다:
* 클러스터 자원을 효율적으로 사용하여 데이터 배치의 처리 시간을 줄이는 것.
* 데이터 배치가 수신되는 만큼 빠르게 처리될 수 있도록 올바른 배치 크기를 설정하는 것
(즉, 데이터 처리가 데이터 수집 속도를 따라잡을 수 있도록 하는 것).
3.14.1. Reducing the Batch Processing Times
각 배치의 처리 시간을 최소화하기 위해 Spark에서 수행할 수 있는 여러 가지 최적화가 있습니다.
이러한 내용은 Tuning Guide에서 자세히 논의되었습니다.
이 섹션에서는 가장 중요한 몇 가지를 강조합니다.
-Level of Parallelism in Data Receiving (데이터 수신에 병렬처리수준)
네트워크를 통해 데이터를 수신하는 것(예: Kafka, 소켓 등)은 데이터가 역직렬화되어 Spark에 저장되도록 요구합니다.
데이터 수신이 시스템의 병목 현상이 된다면, 데이터 수신을 병렬화하는 것을 고려해야 합니다.
각 입력 DStream은 단일 리시버(작업자 머신에서 실행됨)를 생성하여 단일 데이터 스트림을 수신합니다.
따라서 여러 데이터 스트림을 수신하려면 여러 입력 DStream을 생성하고 이를 구성하여 소스에서 데이터 스트림의 서로 다른 파티션을 수신하도록 설정할 수 있습니다.
예를 들어, 두 개의 데이터 토픽을 수신하는 단일 Kafka 입력 DStream을 두 개의 Kafka 입력 스트림으로 분할하면 각각 한 개의 토픽만 수신하게 됩니다.
이렇게 하면 두 개의 리시버가 실행되어 데이터가 병렬로 수신될 수 있으며, 그 결과 전체 처리량이 증가합니다.
이러한 여러 DStream은 합쳐져서 단일 DStream을 생성할 수 있습니다.
그 후, 단일 입력 DStream에 적용되었던 변환을 통합된 스트림에 적용할 수 있습니다.
이는 다음과 같이 수행됩니다.
numStreams = 5
kafkaStreams = [KafkaUtils.createStream(...) for _ in range (numStreams)]
unifiedStream = streamingContext.union(*kafkaStreams)
unifiedStream.pprint()
고려해야 할 또 다른 매개변수는 리시버의 블록 간격으로, 이는 설정 매개변수 spark.streaming.blockInterval에 의해 결정됩니다.
대부분의 리시버에서 수신된 데이터는 Spark의 메모리에 저장되기 전에 데이터 블록으로 집계됩니다.
각 배치의 블록 수는 수신된 데이터를 맵과 유사한 변환으로 처리하는 데 사용되는 작업 수를 결정합니다.
리시버당 배치당 작업 수는 대략적으로 (배치 간격 / 블록 간격)입니다.
예를 들어, 블록 간격이 200밀리초인 경우 2초 배치당 10개의 작업이 생성됩니다.
작업 수가 너무 낮으면(즉, 머신당 코어 수보다 적으면), 사용 가능한 모든 코어가 데이터를 처리하는 데 사용되지 않으므로 비효율적이게 됩니다.
주어진 배치 간격에 대한 작업 수를 증가시키려면 블록 간격을 줄여야 합니다.
그러나 블록 간격의 권장 최소값은 약 50밀리초로, 이보다 낮아지면 작업 시작 오버헤드가 문제가 될 수 있습니다.
여러 입력 스트림/리시버로 데이터를 수신하는 대안으로 입력 데이터 스트림을 명시적으로 재파티셔닝하는 방법(예: inputStream.repartition(<partition 수>))이 있습니다.
이는 수신된 데이터 배치를 추가 처리를 하기 전에 클러스터 내에서 지정된 수의 머신에 분산시킵니다.
-Level of Parallelism in Data Processing
클러스터 자원이 충분히 활용되지 않을 수 있는 경우는 계산의 어느 단계에서 사용되는 병렬 작업 수가 충분히 높지 않을 때입니다.
예를 들어, reduceByKey 및 reduceByKeyAndWindow와 같은 분산 축소 작업의 경우, 기본 병렬 작업 수는 spark.default.parallelism 설정 속성에 의해 제어됩니다.
병렬성 수준을 인수로 전달할 수 있으며(자세한 내용은 PairDStreamFunctions 문서를 참조), spark.default.parallelism 설정 속성을 설정하여 기본값을 변경할 수 있습니다.
-Data Serialization
데이터 직렬화 오버헤드는 직렬화 형식을 조정함으로써 줄일 수 있습니다.
스트리밍의 경우, 직렬화되는 데이터의 두 가지 유형이 있습니다.
* 입력 데이터: 기본적으로, 리시버를 통해 수신된 입력 데이터는 예제기 메모리에 StorageLevel.MEMORY_AND_DISK_SER_2 형태로 저장됩니다.
즉, 데이터는 GC 오버헤드를 줄이기 위해 바이트로 직렬화되며, executor 장애를 견디기 위해 복제됩니다.
또한, 데이터는 먼저 메모리에 유지되며, 스트리밍 계산에 필요한 모든 입력 데이터를 보유할 만큼 메모리가 부족할 경우에만 디스크로 넘어갑니다.
이러한 직렬화는 명백히 오버헤드가 발생하는데, 리시버는 수신된 데이터를 역직렬화하고 Spark의 직렬화 형식을 사용하여 다시 직렬화해야 합니다.
* 스트리밍 작업에서 생성된 지속된 RDD: 스트리밍 계산에 의해 생성된 RDD는 메모리에 지속될 수 있습니다.
예를 들어, 윈도우 작업은 여러 번 처리될 수 있기 때문에 데이터를 메모리에 지속합니다.
그러나 Spark Core의 기본값인 StorageLevel.MEMORY_ONLY와 달리, 스트리밍 계산에 의해 생성된 지속된 RDD는 GC 오버헤드를 최소화하기 위해 기본적으로 StorageLevel.MEMORY_ONLY_SER(즉, 직렬화됨)로 유지됩니다.
두 경우 모두, Kryo 직렬화를 사용하면 CPU와 메모리 오버헤드를 모두 줄일 수 있습니다.
자세한 내용은 Spark 튜닝 가이드를 참조하십시오.
Kryo를 사용할 경우, 사용자 정의 클래스를 등록하고 객체 참조 추적을 비활성화하는 것을 고려하세요(구성 가이드에서 Kryo 관련 구성 참조).
스트리밍 애플리케이션에서 보존해야 하는 데이터 양이 많지 않은 특정 경우에는, 과도한 GC 오버헤드를 발생시키지 않고 역직렬화된 객체로 데이터를 지속하는 것이 가능할 수 있습니다.
예를 들어, 몇 초의 배치 간격을 사용하고 윈도우 작업이 없는 경우, 지속된 데이터에서 직렬화를 비활성화하려고 명시적으로 저장 수준을 설정할 수 있습니다.
이렇게 하면 직렬화로 인한 CPU 오버헤드가 줄어들어, 과도한 GC 오버헤드 없이 성능이 향상될 수 있습니다.
3.14.2. Setting the Right Batch Interval
클러스터에서 실행되는 Spark Streaming 애플리케이션이 안정적이려면 시스템이 수신되는 만큼 데이터를 처리할 수 있어야 합니다.
즉, 데이터 배치가 생성되는 만큼 빠르게 처리되어야 합니다.
애플리케이션이 이러한지를 확인하려면 스트리밍 웹 UI에서 처리 시간을 모니터링하면 됩니다.
여기서 배치 처리 시간은 배치 간격보다 짧아야 합니다.
스트리밍 계산의 성격에 따라 사용되는 배치 간격은 고정된 클러스터 자원에서 애플리케이션이 유지할 수 있는 데이터 속도에 상당한 영향을 미칠 수 있습니다.
예를 들어, 이전의 WordCountNetwork 예제를 고려해보겠습니다.
특정 데이터 속도에 대해 시스템은 2초마다 단어 수를 보고하는 것(즉, 배치 간격이 2초)은 유지할 수 있지만, 500밀리초마다 보고하는 것은 유지할 수 없을 수 있습니다.
따라서 배치 간격은 실제 환경에서 예상되는 데이터 속도를 유지할 수 있도록 설정해야 합니다.
애플리케이션에 적합한 배치 크기를 결정하는 좋은 방법은 보수적인 배치 간격(예: 5-10초)과 낮은 데이터 속도로 테스트하는 것입니다.
시스템이 데이터 속도를 유지할 수 있는지를 확인하기 위해 처리된 각 배치가 경험하는 종단 간 지연 시간을 확인할 수 있습니다(스파크 드라이버 log4j 로그에서 "Total delay"를 찾거나 StreamingListener 인터페이스를 사용할 수 있습니다).
지연 시간이 배치 크기와 유사하게 유지된다면 시스템은 안정적입니다.
그러나 지연 시간이 지속적으로 증가한다면 시스템이 속도를 따라가지 못하고 있으므로 불안정하다는 의미입니다.
안정적인 구성을 파악한 후에는 데이터 속도를 높이거나 배치 크기를 줄이도록 시도할 수 있습니다.
일시적인 데이터 속도 증가로 인해 지연 시간이 순간적으로 증가하는 것은 괜찮지만, 지연 시간이 다시 낮은 값(즉, 배치 크기보다 작은 값)으로 줄어드는 것이 중요합니다.
3.14.3. Memory Tuning
Spark 애플리케이션의 메모리 사용량 및 GC 동작 조정에 대한 내용은 튜닝 가이드에서 자세하게 설명되어 있습니다.
이를 꼭 읽어보는 것을 적극 권장합니다.
이 섹션에서는 Spark Streaming 애플리케이션의 맥락에서 몇 가지 튜닝 매개변수에 대해 논의합니다.
Spark Streaming 애플리케이션이 필요로 하는 클러스터 메모리의 양은 사용하는 변환의 유형에 크게 의존합니다.
예를 들어, 최근 10분의 데이터에 대해 윈도우 작업을 사용하려면 클러스터는 메모리에 10분 분량의 데이터를 저장할 수 있는 충분한 메모리를 가져야 합니다.
또는 많은 키를 가진 updateStateByKey를 사용하려는 경우, 필요한 메모리는 높아질 것입니다.
반대로, 단순한 map-filter-store 작업을 수행하려는 경우 필요한 메모리는 낮습니다.
일반적으로 리시버를 통해 수신된 데이터는 StorageLevel.MEMORY_AND_DISK_SER_2로 저장됩니다.
메모리에 맞지 않는 데이터는 디스크로 넘어갑니다.
이로 인해 스트리밍 애플리케이션의 성능이 저하될 수 있으므로, 스트리밍 애플리케이션에 필요한 만큼 충분한 메모리를 제공하는 것이 권장됩니다.
소규모에서 메모리 사용량을 시도해 보고 이를 바탕으로 추정하는 것이 좋습니다.
메모리 조정의 또 다른 측면은 가비지 컬렉션입니다.
낮은 대기 시간이 요구되는 스트리밍 애플리케이션에서는 JVM의 가비지 컬렉션으로 인해 큰 일시 정지가 발생하는 것은 바람직하지 않습니다.
메모리 사용량 및 GC 오버헤드를 조정하는 데 도움이 되는 몇 가지 매개변수가 있습니다:
* DStream의 지속성 수준: 데이터 직렬화 섹션에서 언급했듯이, 입력 데이터와 RDD는 기본적으로 직렬화된 바이트로 지속됩니다.
이는 비직렬화된 지속성에 비해 메모리 사용량 및 GC 오버헤드를 줄입니다.
Kryo 직렬화를 활성화하면 직렬화된 크기와 메모리 사용량이 더 줄어듭니다.
추가적으로, CPU 시간을 소모하더라도 압축을 통해(구성 spark.rdd.compress 참조) 메모리 사용량을 더 줄일 수 있습니다.
* 오래된 데이터 제거: 기본적으로 모든 입력 데이터와 DStream 변환에 의해 생성된 지속된 RDD는 자동으로 정리됩니다. Spark Streaming은 사용된 변환에 따라 데이터를 정리하는 시점을 결정합니다.
예를 들어, 10분의 윈도우 작업을 사용하는 경우, Spark Streaming은 마지막 10분의 데이터를 유지하고 오래된 데이터를 적극적으로 버립니다.
데이터는 streamingContext.remember를 설정하여 더 긴 시간 동안 유지될 수 있습니다(예: 오래된 데이터 쿼리).
* CMS 가비지 수집기: GC 관련 일시 정지를 일관되게 낮게 유지하기 위해 동시 마크-스위프 GC의 사용이 강력히 권장됩니다.
비록 동시 GC가 시스템의 전체 처리량을 줄이는 것으로 알려져 있지만, 보다 일관된 배치 처리 시간을 달성하기 위해 여전히 권장됩니다.
CMS GC를 드라이버와 실행기 모두에 설정해야 합니다(스파크 제출 시 --driver-java-options 사용 및 스파크 구성 시 spark.executor.extraJavaOptions 사용).
* 기타 팁: GC 오버헤드를 추가로 줄이기 위한 몇 가지 추가 팁은 다음과 같습니다:
OFF_HEAP 저장 수준을 사용하여 RDD를 지속합니다. 더 자세한 내용은 Spark 프로그래밍 가이드를 참조하세요.
더 작은 힙 크기를 가진 실행기를 추가로 사용합니다. 이는 각 JVM 힙 내에서 GC 압력을 줄이는 데 도움이 됩니다.
