
- 지구정복과정 (524)

- 데이터 엔지니어링 정복 (422)
- Elastic Stack (2)
- Hadoop Ecosystem (27)
- HTML-CSS-JavaScript-Spring-.. (43)
- JAVA & JSP (46)
- Python (29)
- SQL (14)
- Cloud(AWS, Ncloud) (8)
- Docker&Kubernetes (2)
- Linux (11)
- Git-GitHub (9)
- Algorithm (159)
- HDFS (4)
- Iceberg (8)
- Hive (5)
- Hue (1)
- Yarn (1)
- Spark (9)
- MapReduce (2)
- Airflow (2)
- Sqoop (2)
- Tez (0)
- Trino (3)
- Kafka (12)
- Zookeeper (2)
- Flume (2)
- Oozie (1)
- Hbase (3)
- Ranger (1)
- OpenSearch (1)
- Ansible & AWX (2)
- AD & LDAP (0)
- NiFi (3)
- Ambari (1)
- Infra Solr (2)
- 데이터 애널리틱스 정복 (3)
- 프로젝트 (5)
- 자격증 정복 (33)
- 영어 정복 (7)
- 건강 정복 (5)
- 주식 정복 (가능 ?) (0)
- 이것저것 (38)
- 데이터 엔지니어링 정복 (422)
반응형
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 맛집
- BigData
- 코엑스
- pyspark
- 코딩테스트
- Apache Kafka
- bigdata engineer
- hadoop
- 여행
- 영어
- 알고리즘
- 코딩
- Spark
- Data Engineering
- java
- 개발
- 삼성역맛집
- 자바
- Iceberg
- 프로그래머스
- 백준
- 코테
- bigdata engineering
- 코엑스맛집
- HIVE
- Data Engineer
- Trino
- 용인맛집
- Kafka
- apache iceberg
Archives
- Today
- Total
지구정복
[NiFi] Data Pipeline | log -> Json -> gzip.parquet -> HDFS -> Iceberg Table 본문
데이터 엔지니어링 정복/NiFi
[NiFi] Data Pipeline | log -> Json -> gzip.parquet -> HDFS -> Iceberg Table
noohhee 2025. 4. 22. 14:42728x90
반응형
NiFi 1.15.2
Spark 3.1.4
Iceberg 1.3.1
Hive 3.1.3
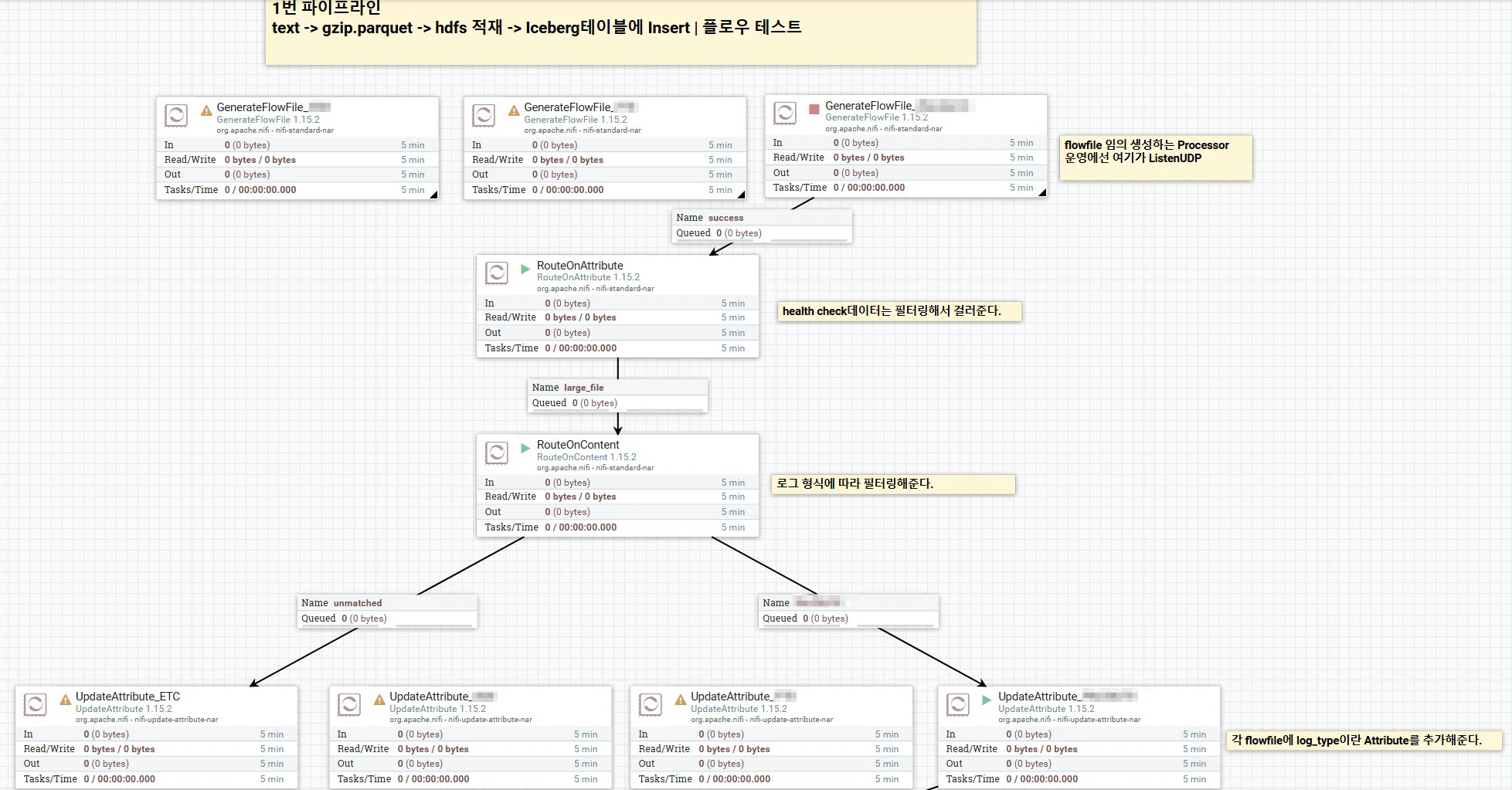


마지막 HDFS에 저장된 gzip.parquet 파일을 읽어서 Iceberg Table로 적재하는 PySpark Streaming을 실행한다.
미리 Iceberg Table은 생성되어야 있어야 하므로 PySpark로 만들어준다.
#iceberg table 생성쿼리
q="""
CREATE TABLE iceberg_test_db.test_table_name (
data STRING,
log_timestamp timestamp_ntz
)
USING iceberg
PARTITIONED BY (days(log_timestamp))
TBLPROPERTIES (
'read.parquet.vectorization.enabled' = 'true',
'write.metadata.delete-after-commit.enabled' = 'true',
'write.metadata.previous-versions-max' = '5',
'format-version' = '2',
'format' = 'parquet'
)
"""
spark.sql(q).show()
아래는 PySpark Streaming 코드이다.
spark = SparkSession.builder \
.appName("LOG_Original_To_Iceberg") \
.config("spark.driver.cores", "4") \
.config("spark.driver.memory", "4g") \
.enableHiveSupport() \
.getOrCreate()
import glob
import subprocess
import os
# 파일 경로 설정
input_path = "/user/poc/tmp/test_table_name/*.gzip.parquet"
# 스트리밍 읽기
streaming_df = spark.readStream.schema("data STRING, log_timestamp TIMESTAMP").parquet(input_path)
# Iceberg에 데이터 적재하는 함수 정의
def write_to_iceberg(df, epoch_id):
df.write.format("iceberg") \
.mode("append") \
.save("iceberg_test_db.test_table_name")
# 처리 완료 후 원본 Parquet 파일 삭제
try:
# HDFS 디렉터리 삭제
delete_path = "/user/poc/tmp/test_table_name/*"
command = ["hdfs", "dfs", "-rm", "-r", delete_path]
result = subprocess.run(command, check=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
print(f"Deleted HDFS directory: {delete_path}")
print("Output:", result.stdout.decode())
except subprocess.CalledProcessError as e:
print(f"Error deleting HDFS directory {delete_path}: {e.stderr.decode()}")
# 스트리밍 쿼리 시작
query = (streaming_df
.writeStream
.foreachBatch(write_to_iceberg)
.outputMode("append")
.trigger(processingTime="10 minutes") # 여기서 10분 단위로 트리거 설정
.start())
# 스트리밍 쿼리 실행 대기
query.awaitTermination()
728x90
반응형
'데이터 엔지니어링 정복 > NiFi' 카테고리의 다른 글
| [NiFi & Linux] NiFi log 관리하기 (1) | 2025.05.09 |
|---|---|
| [NiFi] 주로 사용하는 프로세서 설명 (0) | 2025.04.16 |
'데이터 엔지니어링 정복/NiFi' Related Articles
more

Comments