
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 백준
- 프로그래머스
- pyspark
- bigdata engineering
- 맛집
- 코테
- Data Engineering
- 코엑스맛집
- Kafka
- HIVE
- 개발
- 삼성역맛집
- Trino
- apache iceberg
- 영어
- 자바
- java
- HDFS
- Spark
- Data Engineer
- Iceberg
- BigData
- hadoop
- bigdata engineer
- 코딩테스트
- Apache Kafka
- 알고리즘
- 코딩
- Linux
- 여행
- Today
- Total
지구정복
[Iceberg] Iceberg Guide Book Summary | Chaper 11. Apache Iceberg in Production 본문
[Iceberg] Iceberg Guide Book Summary | Chaper 11. Apache Iceberg in Production
noohhee 2025. 3. 5. 19:19CHAPTER 11 Apache Iceberg in Production
In this chapter, we will discuss many of the tools that can be used to help monitor and maintain Apache Iceberg tables in production.
Apache Iceberg Metadata Tables
SELECT * FROM catalog.table.history AS OF VERSION 1059035530770364194
These tables are generated from the metadata across Apache Iceberg metadata files at query time.
The history Metadata Table
The history metadata table records the table’s evolution.
Each of the four fields in this table provides unique insights into the table’s history.
The first field, made_current_at, represents the exact timestamp when the corresponding snapshot was made the current snapshot.
This gives you a precise temporal marker for when changes to the table were committed.
Next, the snapshot_id field serves as a unique identifier for each snapshot.
This identifier enables you to track and reference specific snapshots within the table’s history.
Following this, the parent_id field provides the unique ID of the parent snapshot of the current snapshot.
This effectively maps out the lineage of each snapshot, thus facilitating the tracking of the table’s evolution over time.
Finally, the is_current_ancestor field indicates whether a snapshot is an ancestor of the table’s current snapshot.
This boolean value (true or false) helps identify snapshots that are part of the table’s present state lineage and those that have been invalidated from table rollbacks.
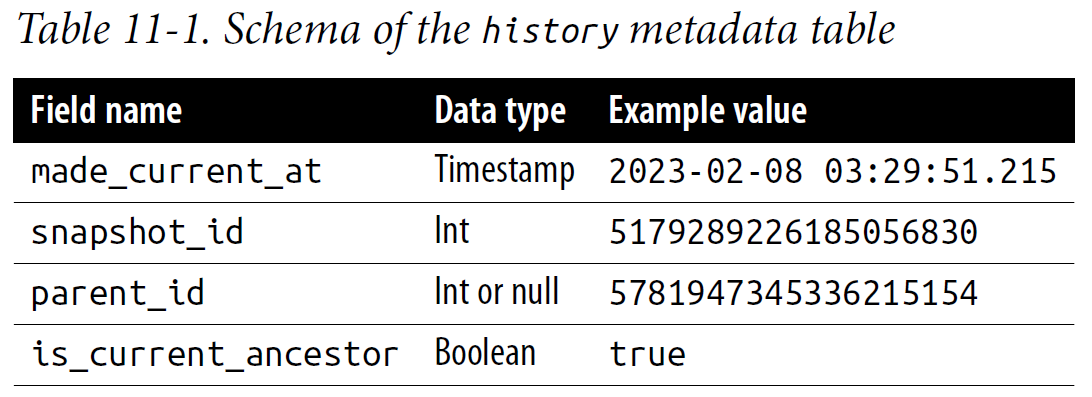
You can use the history metadata table for data recovery and version control as well as to identify table rollbacks.
With a snapshot ID, you can restore your data and minimize potential data loss.
In the following code snippet, we run a query to get the snapshot_id from all snapshots prior to July 11, which we can use to roll back the table to a snapshot before any incident that occurred on that date.
SELECT snapshot_id
FROM catalog.table.metadata_log_entries
WHERE made_current_at < '2023-07-11 00:00:00'
ORDER BY made_current_at ASC
There are two signals to look for in the history table to identify a table rollback:
• Two or more snapshots have the same parent_id.
• Only one of those snapshots has is_current_ancestor set to true (true would mean it’s part of the current table history).
The following code snippet shows how to query all entries from the history metadata table:
-- Trino
SELECT * FROM "table$history"
The metadata_log_entries Metadata Table
The metadata_log_entries metadata table keeps track of the evolution of the table by logging the metadata files generated during table updates.
The timestamp field records the exact date and time when the metadata was updated.
Next, the file field indicates the location of the datafile that corresponds to that particular metadata log entry.
The latest_snapshot_id field provides the identifier of the most recent snapshot at the time of the metadata update.
Following that, the latest_schema_id field contains the ID of the schema being used when the metadata log entry was created.
Finally, the latest_sequence_number field signifies the order of the metadata updates.
It is an incrementing count that helps track the sequence of metadata changes over time.
The schema of the metadata-log-entries table is laid out in Table 11-2.

You can use the metadata_log_-entries metadata table to find the latest snapshot with a previous schema.
For example, maybe you made a change to the schema and now you want to go back to the previous schema. You’ll want to find the latest snapshot using that schema, which can be determined with a query that will rank the snapshots for each schema_id and then return only the top-ranked snapshot for each:
WITH Ranked_Entries AS (
SELECT
latest_snapshot_id,
latest_schema_id,
timestamp,
ROW_NUMBER() OVER(PARTITION BY latest_schema_id ORDER BY timestamp DESC) as row_num
FROM
catalog.table.metadata_log_entries
WHERE
latest_schema_id IS NOT NULL
)
SELECT
latest_snapshot_id,
latest_schema_id,
timestamp AS latest_timestamp
FROM
Ranked_Entries
WHERE
row_num = 1
ORDER BY
latest_schema_id DESC;The following code snippet will query all entries from this table:
-- Spark SQL
SELECT * FROM my_catalog.table.metadata_log_entries;
The snapshots Metadata Table
The snapshots metadata table is essential for tracking dataset versions and histories.
It maintains metadata about every snapshot for a given table, representing a consistent view of the dataset at a specific time.
First, the committed_at field signifies the precise timestamp when the snapshot was created, giving an indication of when the snapshot and its associated data state were committed.
The snapshot_id field is a unique identifier for each snapshot.
This field is crucial for distinguishing between the different snapshots and for specific operations such as snapshot retrieval or deletion.
The operation field lists a string of the types of operations that occurred, such as APPEND and OVERWRITE.
The parent_id field links to the snapshot ID of the snapshot’s parent, providing context about the lineage of snapshots and allowing for the reconstruction of a historical sequence of snapshots.
Further, the manifest_list field offers detailed insights into the files comprising the snapshot.
Lastly, the summary field holds metrics about the snapshot, such as the number of added or deleted files, number of records, and other statistical data that provides a quick glance into the snapshot’s content.
Table 11-3 summarizes the schema for the snapshots metadata table.

There are many possible ways to use the snapshots metadata table.
One use case is to understand the pattern of data additions to the table.
This could be useful in capacity planning or understanding data growth over time.
SELECT
committed_at,
snapshot_id,
summary['added-records'] AS added_records
FROM
catalog.table.snapshots;
Another use case for the snapshots metadata table is to monitor the types and frequency of operations performed on the table over time.
This could be useful for understanding the workload and usage patterns of the table. Here is an SQL query that shows the count of each operation type over time:
SELECT
operation,
COUNT(*) AS operation_count,
DATE(committed_at) AS date
FROM
catalog.table.snapshots
GROUP BY
operation,
DATE(committed_at)
ORDER BY
date;
The following SQL will allow you to query the snapshots table to see all of its data:
-- Trino
SELECT * FROM "table$snapshots"
The files Metadata Table
적당한 파티션 개수를 확인하거나 특정 컬럼의 null값을 찾거나 스냅샷에 사용되는 모든 파일 크기를 알 수 있다.
The files metadata table showcases the current datafiles within a table and furnishes detailed information about each of them, from their location and format to their content and partitioning specifics.
The first field, content, represents the type of content in the file, with a 0 signifying a datafile, 1 a position delete file, and 2 an equality delete file.
Next, file_path gives the exact location of each file. This helps facilitate access to each datafile when needed.
The file_format field indicates the format of the datafile; for instance, whether it’s a Parquet, Avro, or ORC file.
The spec_id field corresponds to the partition spec ID that the file adheres to, providing a reference to how the data is partitioned.
The partition field provides a representation of the datafile’s specific partition, indicating how the data within the file is divided for optimized access and query performance.
The record_count field reports the number of records contained within each file, giving a measure of the file’s data volume.
The file_size_in_bytes field provides the total size of the file in bytes, while column_sizes furnishes the sizes of the individual columns.
The value_counts, null_value_counts, and nan_value_counts fields provide the count of non-null, null, and NaN (Not a Number) values, respectively, in each column.
The lower_bounds and upper_bounds fields hold the minimum and maximum values in each column, providing essential insights into the data range within each file.
The key_metadata field contains implementation-specific metadata, if any exists.
The split_offsets field provides the offsets at which the file is split into smaller segments for parallel processing.
The equality_ids and sort_order_id fields correspond to the IDs relating to equality delete files, if any exist, and the IDs of the table’s sort order, if it has one.
Table 11-4 summarizes the schema of the files metadata table.
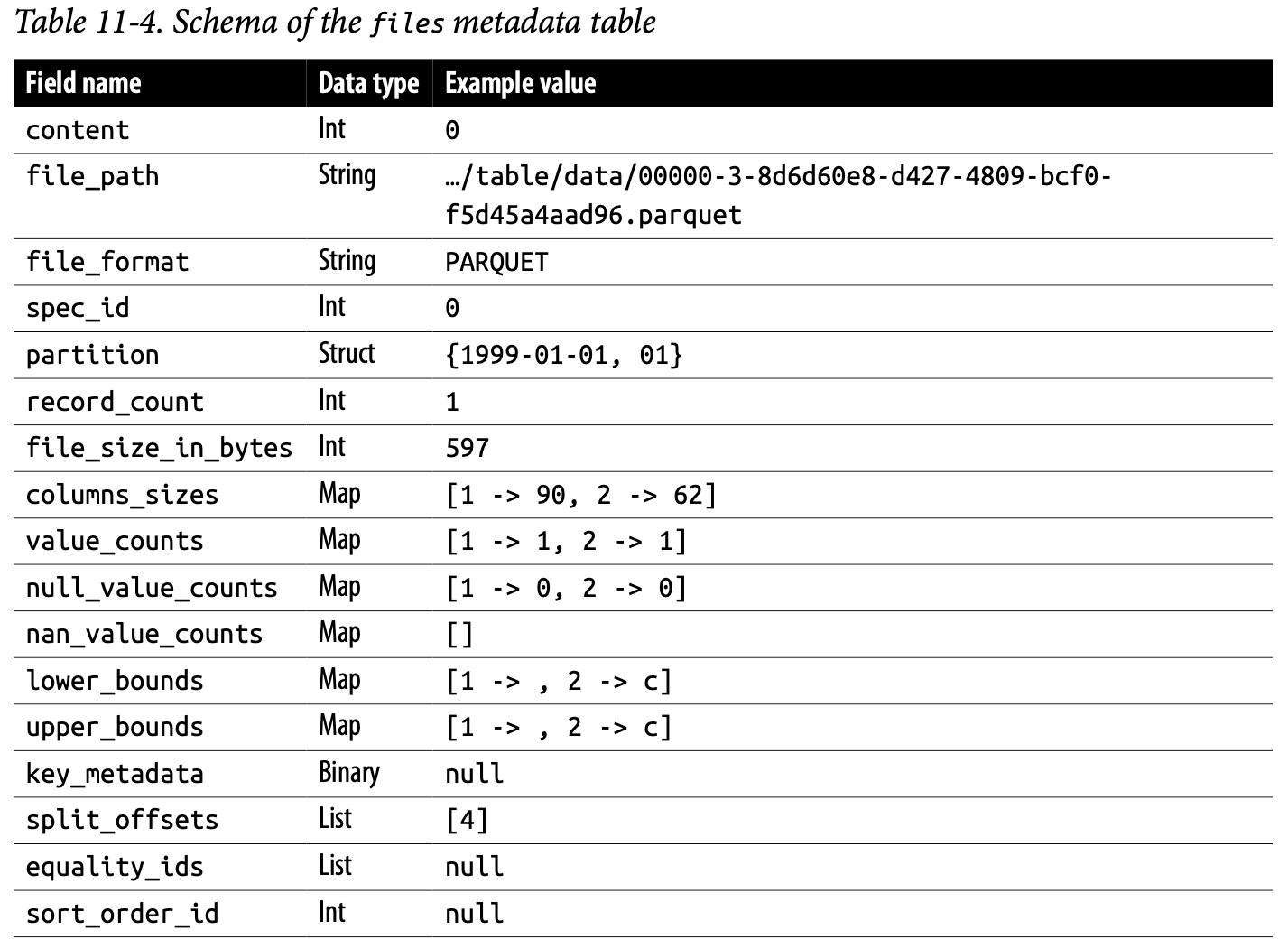
The following query can help you break down each partition’s number of files and average file size to help identify partitions to rewrite:
SELECT
partition,
COUNT(*) AS num_files,
AVG(file_size_in_bytes) AS avg_file_size
FROM
catalog.table.files
GROUP BY
partition
ORDER BY
num_files DESC,
avg_file_size ASC
Some fields probably shouldn’t have null values in your data.
Using the files metadata table you can identify partitions or files that may have missing values in a much more lightweight operation than scanning the actual data.
The following query returns the partition and filename of any files with null data in their third column:
SELECT
partition, file_path
FROM
catalog.table.files
WHERE
null_value_counts['3'] > 0
GROUP BY
partition
You can also use the files metadata table to sum all the file sizes to get a total size of the snapshot:
SELECT sum(file_size_in_bytes) from catalog.table.files;
Using time travel you can get the list of files from a previous snapshot:
SELECT file_path, file_size_in_bytes
FROM catalog.table.files
VERSION AS OF <snapshot_id>;
The following SQL allows you to pull up the data in the files table:
-- Trino
SELECT * FROM "table$files"
The manifests Metadata Table
어느 manifest 파일을 rewrite_manifests할 지 알 수 있다.
The manifests metadata table details each of the table’s current manifest files.
The path field provides the filepath where the manifest is stored, enabling quick access to the file.
The length field, on the other hand, shows the size of the manifest file.
The partition_spec_id field indicates the specification ID of the partition that the manifest file is associated with, which is valuable for tracking changes in partitioned tables.
The added_snapshot_id field provides the ID of the snapshot that added this manifest file, offering a link between snapshots and manifests.
Three count fields—added_data_files_count, existing_data_files_count, and deleted_data_files_count—respectively relay the number of new files added in this manifest, the number of existing datafiles that were added in previous snapshots, and the number of files deleted in this manifest.
This trio of fields is instrumental in understanding the evolution of the data.
Lastly, the partition_summaries field is an array of field_summary structs that summarize partition-level statistics.
It contains the following information: contains_null, contains_nan, lower_bound, and upper_bound.
These fields indicate whether the partition contains null or NaN values, and they provide the lower and upper bounds of data within the partition.
It’s important to note that contains_nan could return null when the information isn’t available from the file’s metadata, which usually occurs when reading from a V1 table.
Table 11-5 summarizes the schema for the manifests metadata table.

With the manifests metadata table, users can perform various operations, including finding manifests that need rewriting, summing the total number of files added per snapshot, finding snapshots where files were deleted, and determining whether the table is sorted well.
With the following query, you can find which manifests are below the average size of manifest files, which can help you discover which manifests can be compacted with rewrite_manifests:
WITH avg_length AS (
SELECT AVG(length) as average_manifest_length
FROM catalog.table.manifests
)
SELECT
path,
length
FROM
catalog.table.manifests
WHERE
length < (SELECT average_manifest_length FROM avg_length);
With this query, you can see how many files were added for each snapshot:
SELECT
added_snapshot_id,
SUM(added_data_files_count) AS total_added_data_files
FROM
catalog.table.manifests
GROUP BY
added_snapshot_id;
Knowing which snapshots have deletes can help you monitor which snapshots may need expiration to hard-
delete the data:
SELECT
added_snapshot_id
FROM
catalog.table.manifests
WHERE
deleted_data_files_count > 0;
-- Trino
SELECT * FROM "table$manifests"
The partitions Metadata Table
The partitions metadata table in Apache Iceberg provides a snapshot of how the data in a table is divided into distinct, nonoverlapping regions, known as partitions.
Each row represents a specific partition within the table.

There are many use cases for the partitions metadata table, including finding how many files are in a partition, summing the total size in bytes of a partition, and finding the number of partitions per partition scheme.
For instance, you may want to see how many files are in a partition, because if a particular partition has a large number of files, it may be a candidate for compaction.
The following code accomplishes this:
SELECT partition, file_count FROM catalog.table.partitions
Along with looking at the number of files, you may want to look at the size of the partition.
If one partition is particularly large, you may want to alter your partitioning scheme to better balance out distribution, as shown here:
SELECT partition, SUM(file_size_in_bytes) AS partition_size FROM cata
log.table.files GROUP BY partition
With partition evolution, you may have different partitioning schemes over time.
If you’re curious how different partitioning schemes affected the number of partitions for the data written with it, the following query should be helpful:
SELECT
spec_id,
COUNT(*) as partition_count
FROM
catalog.table.partitions
GROUP BY
spec_id;
-- Trino
SELECT * FROM "test_table$partitions"
The all_data_files Metadata Table
The all_data_files metadata table in Apache Iceberg provides comprehensive details about every datafile across all valid snapshots in the table.
Remember, the all_data_files metadata table may produce more than one row per datafile because a file could be part of multiple table snapshots.
Table 11-7 summarizes the schema of the all_data_files metadata table.

There are many use cases for the all_data_files metadata table, including finding the largest table across all snapshots, finding the total file size across all snapshots, and assessing partitions across snapshots.
The following query first makes sure you have only distinct files since the same file can have multiple records. It then returns the five largest files from that list of distinct files:
WITH distinct_files AS (
SELECT DISTINCT file_path, file_size_in_bytes
FROM catalog.table.all_data_files
)
SELECT file_path, file_size_in_bytes
FROM distinct_files
ORDER BY file_size_in_bytes DESC
LIMIT 5;
The all_manifests Metadata Table
The all_manifests metadata table in Apache Iceberg provides detailed insights into every manifest file across all valid snapshots in the table.
Remember, the all_manifests metadata table may produce more than one row per manifest file because a manifest file may be part of multiple table snapshots.
Table 11-8 summarizes the schema of the all_manifests metadata table.

There are many use cases for the all_manifests metadata table, including finding all manifests for a particular snapshot, monitoring the growth of manifests from snapshot to snapshot, and getting the total size of all valid manifests.
While the manifests table will tell you all the manifests for the current snapshot, you can generate this data for any snapshot using the all_manifests table with a query such as this one:
SELECT *
FROM catalog.table.all_manifests
WHERE reference_snapshot_id = 1059035530770364194;
The following query returns the total manifest size and datafile counts for each snapshot to see the growth of files and manifest size from snapshot to snapshot:
SELECT reference_snapshot_id, SUM(length) as manifests_length,
SUM(added_data_files_count + existing_data_files_count)AS total_data_files
FROM catalog.table.example.all_manifests
GROUP BY reference_snapshot_id;
The refs Metadata Table
The refs metadata table in Apache Iceberg provides a list of all the named references within an Iceberg table. Named references can be thought of as pointers to specific snapshots of the table data, providing an ability to bookmark or version the table state.
Remember, the refs metadata table helps you understand and manage your table’s snapshot history and retention policy, making it a crucial part of maintaining data versioning and ensuring that your table’s size is under control.
Table 11-9 summarizes the schema of the refs metadata table.

you may be wondering whether a particular branch’s rules may result in the invalidation of a snapshot on its next update. This query should help filter just references that have max snapshot rules:
SELECT name, min_snapshots_to_keep, max_snapshot_age_in_ms
FROM catalog.table.refs
WHERE min_snapshots_to_keep IS NOT NULL AND max_snapshot_age_in_ms IS NOT NULL;
The entries Metadata Table
The entries metadata table in Apache Iceberg offers insightful details about each operation that has been performed on the table’s data and delete files across all snapshots.
Each row in this table captures operations that affected many files at a certain point in the table’s history, making it an essential resource for understanding the evolution of your dataset.
By querying the entries table, you can keep track of each operation applied to your table, offering a comprehensive audit trail of your data evolution. Table 11-10 summarizes the schema of the entries metadata table.

the following query will find all entries that match a snapshot representing an added file:
SELECT data_file
FROM catalog.table.entries
WHERE snapshot_id = <your_snapshot_id> AND status = 1;
With the following query, you’ll get the size of added files for each snapshot to see the growth in storage needs across snapshots:
SELECT snapshot_id, SUM(data_file.file_size_in_bytes) as total_size_in_bytes
FROM catalog.table.entries
WHERE status = 1
GROUP BY snapshot_id
ORDER BY snapshot_id ASC;
Using the Metadata Tables in Conjunction
Get data on all the files added in a snapshot
To bring up all the file metadata for a particular snapshot, use the following query:
SELECT f.*, e.snapshot_id
FROM catalog.table.entries AS e
JOIN catalog.table.files AS f
ON e.data_file.file_path = f.file_path
WHERE e.status = 1 AND e.snapshot_id = <your_snapshot_id>;
Get a detailed overview of the lifecycle of a particular datafile
Using the following query you can build a detailed log of a particular datafile’s history, allowing you to also see how many files were added and deleted at each point in the file’s lifecycle.
Also, using the filepath you can identify each operation where the file was involved and use the entries and manifests tables to gather more information and context around those operations:
SELECT e.snapshot_id, e.sequence_number, e.status, m.added_snapshot_id,
m.deleted_data_files_count, m.added_data_files_count
FROM catalog.table.entries AS e
JOIN catalog.table.manifests AS m
ON e.snapshot_id = m.added_snapshot_id
WHERE e.data_file.file_path = '<your_file_path>'
ORDER BY e.sequence_number ASC;
나머지 귀찮아서 생략
Isolation of Changes with Branches
This approach allows for the separation of different lines of work,enabling developers to make changes independently without interfering with other developers’ work or destabilizing the main codebase.
It’s akin to having multiple parallel universes, where changes in one universe do not affect the others.
You can experiment, make mistakes, and learn without the fear of impacting the broader system.
there are two ways to implement this concept:
at the table level, which is native to Apache Iceberg regardless of catalog;
and at the catalog level, which is possible when using the Project Nessie catalog.
The first method, isolating changes at the table level, involves creating branches for specific tables.
Each branch contains a full history of changes made to that table.
This approach allows for concurrent schema evolution, rollbacks, and other advanced use cases.
There are advantages and drawbacks to both methods. Table-level isolation provides granular control and flexibility for individual tables but might become complex to manage in a large-scale data environment.
It provides developers with the freedom to experiment and make changes without fear of widespread impact, allows for version control and rollback of changes, and promotes greater data integrity and lineage tracking.
Table Branching and Tagging
Built into the Apache Iceberg specification is the ability for the metadata to track snapshots under different paths, known as branching, or to give particular snapshots a name, known as tagging.
This enables isolation, reproducibility, and experimentation in your data operations with an individual table.
Table branching
Table branching in Apache Iceberg allows you to create independent lineages of snapshots, each with its own lifecycle.
Each branch also has settings for maximum snapshot age and minimum number of snapshots that should exist in the branch.
You can achieve this with Iceberg’s Java API using the toBranch operation while writing to the table (the Java API consists of Java libraries that are part of the Apache Iceberg project that enable common operations on Iceberg tables).
This method isolates the incoming data, allowing for validation and checks before it’s merged with the main table data.
Here is a Java code snippet demonstrating this process:
// Using Iceberg Java API
// String to be used as branch name
String branch = "ingestion-validation-branch";
// Create a branch
table.manageSnapshots()
// Create a branch from a particular snapshot
.createBranch(branch, 3)
// Specify how many snapshots to keep
.setMinSnapshotsToKeep(branch, 2)
// Specify max age of those snapshots
.setMaxSnapshotAgeMs(branch, 3600000)
// Set max age of branch
.setMaxRefAgeMs(branch, 604800000)
.commit();
// Write incoming data to the new branch
table.newAppend()
// Append incoming file to the branch
.appendFile(INCOMING_FILE)
// Specify the branch to do this operation on
.toBranch(branch)
.commit();
// Read from the branch for validation
TableScan branchRead = table
.newScan()
.useRef(branch);
The creation of "ingestion-validation-branch" allows for the testing and validation of new incoming data, making it an invaluable tool in data engineering workflows.
Once the data on the new branch is validated and passes all the quality checks, the main branch can be updated to the head of "ingestion-validation-branch" using the fastForward operation:
// Updating the main branch to incorporate validated changes from the new branch
table
.manageSnapshots()
// Set that the main branch's latest commit should match the new branch
.fastForward("main", "ingestion-validation-branch")
.commit();
To achieve the same isolation and validation workflow using SQL, you can use the ALTER TABLE statement provided by Apache Iceberg.
The first step is to create a new branch, "ingestion-validation-branch", on your table.
Let’s say you’re working with a table named sales_data in a catalog called my_catalog and a database named my_db. The branch is configured to retain snapshots for seven days and to always keep at least two snapshots.
Here is the code to do this:
-- Create the new branch
ALTER TABLE my_catalog.my_db.sales_data
CREATE BRANCH ingestion-validation-branch
RETAIN 7 DAYS
WITH RETENTION 2 SNAPSHOTS;
Next, set the newly created branch as the active writing branch using the SET command:
-- Set the new branch to the write branch
SET spark.wap.branch = 'ingestion-validation-branch';
The term WAP (Write Audit Publish) is a pattern where you write the data, audit the data for quality issues, and then publish it when complete.
For this example, let’s assume you are inserting some data into the sales_data table:
-- Write incoming data to the new branch
INSERT INTO my_catalog.my_db.sales_data (column1, column2, column3)
VALUES (value1, value2, value3), (value4, value5, value6);
Once you’re done with any validations, you will need to use Java to run the fastForward procedure.
Table tagging
Tagging in Iceberg allows for named references to snapshots, facilitating reproducibility.
Tagging enables you to retain important historical snapshots, thereby allowing state reproduction.
A tag can be created for a snapshot using the createTag operation, and you can specify how long the tag should be retained:
-- Spark SQL
-- Create a tag with a life of 14 days
ALTER TABLE catalog.db.closed_invoices
CREATE TAG 'end-of-quarter-Q3FY23'
AS OF VERSION 8
RETAIN 14 DAYS;
In this example, a tag named "end-of-quarter-Q3FY23" is created at snapshot 8, and it is retained for one day. Reading from a tag is as straightforward as passing it to the useRef API when setting up a table scan, as shown here: