
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Trino
- Apache Kafka
- pyspark
- hadoop
- Kafka
- Data Engineer
- HIVE
- 삼성역맛집
- 프로그래머스
- 개발
- Data Engineering
- 백준
- Spark
- apache iceberg
- Linux
- bigdata engineering
- 코딩
- java
- 코테
- 코딩테스트
- 자바
- BigData
- 코엑스맛집
- 여행
- 알고리즘
- bigdata engineer
- 영어
- HDFS
- 맛집
- Iceberg
- Today
- Total
지구정복
[Python & MongoDB & Spark] Twitter내용 데이터 분석하기 | 빅데이터를 지탱하는 기술 본문
[Python & MongoDB & Spark] Twitter내용 데이터 분석하기 | 빅데이터를 지탱하는 기술
noohhee 2021. 12. 6. 17:23출처 : 빅데이터를 지탱하는 기술(책)
아래 실습을 따라하시려면 버전을 모두 맞춰주세요!
안 그러면 에러와 씨름합니다. ㅎ
* 환경
윈도우10 버추얼박스 1개 머신에 CentOS 7.9.2009 설치하고 진행
자바 버전: openjdk version "1.8.0_292"
파이썬 버전: Python 3.6.8
jdk1.8설치는 아래 블로거님 글 참고
https://bamdule.tistory.com/57
[Linux] CentOS 7에 OpenJDK 1.8 설치
1. open-jdk 1.8 설치 # yum install java-1.8.0-openjdk # yum install java-1.8.0-openjdk-devel 설치가 완료되면 /usr/bin/경로에 java가 생성됩니다. 2. 환경변수 등록 /usr/bin/java 경로에 심볼릭링크가 걸..
bamdule.tistory.com
파이썬 설치는 아래 블로거님 글 참고
https://cntechsystems.tistory.com/105
[CentOS 7] Python3 설치 및 버전 변경과 Tensorflow, Keras 설치
안녕하세요 씨앤텍 시스템즈 봉시윤 연구원입니다. 이번 포스트는 Linux CentOS 7버전 Python3 설치 및 버전 변경과 Tensorflow, Keras 설치 입니다. 글의 구성은 다음과 같습니다. 1. python3 설치 2. python2.7..
cntechsystems.tistory.com
CentOS와 자바, 파이썬은 모두 설치되어 있다는 가정하에 진행
1. MongoDB 설치
1. yum 패키지 레포지토리 추가
/etc/yum.repos.d/mongodb-org-4.4.repo 파일을 생성하여 다음 내용 작성
$ sudo vim /etc/yum.repos.d/mongodb-org-4.4.repo아래 내용 입력
[mongodb-org-4.4]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/4.4/x86_64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-4.4.asc2. MongoDB 패키지 설치 및 서비스 시작
$ sudo yum install -y mongodb-org서비스 시작하기
$ sudo service mongod start부팅시 자동시작
$ sduo chkconfig mongod on3. MongoDB Shell 접속
$ mongo
2. Twitter API 신청하기
아래에서 먼저 Twitter 회원가입
https://developer.twitter.com/en
Use Cases, Tutorials, & Documentation
Publish & analyze Tweets, optimize ads, & create unique customer experiences with the Twitter API, Twitter Ads API, & Twitter Embeds.
developer.twitter.com
그리고 핸드폰 번호를 입력해야지 Twitter developer에 가입할 수 있다.
메뉴 -> Settings and privacy

Your account -> Account infomation

핸드폰 번호 등록이 완료되었으면 다시 Twitter developer에서 Sign Up을 한다.
이때 왜 사용하는지 물어보는데 대충 번역기 돌려서 이유를 적어준다.
이렇게 대충쓰고 가입이 완료되면 Project를 만들고 Consumer Key, Access Token을 발급받는다.
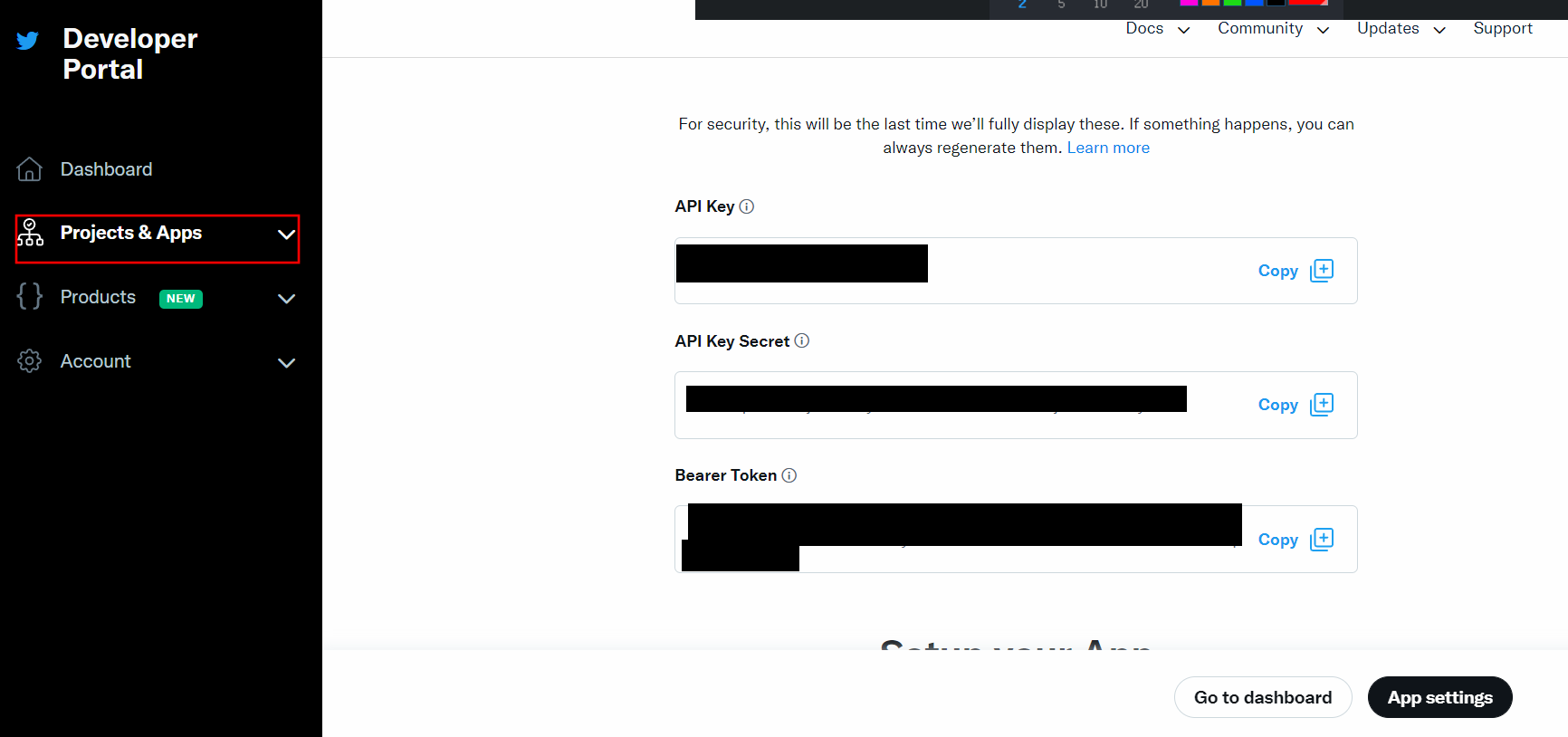
따로 잘 복사해둔다. 그리고 App settings를 눌러서 다음화면으로 넘어간다.
그리고 위에서 Key and Token 탭을 누른다.

그리고 Access Token and Secret의 Generate를 눌러서 발급받는다.
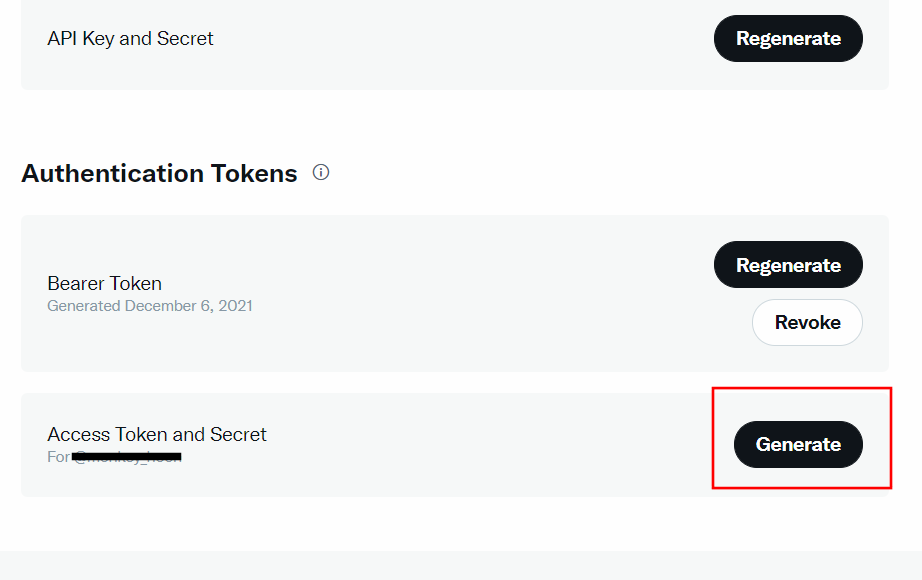
이제 위의 API Key와 API Key Secret 그리고 Access Token과 Access Token Secret을 잘 복사해둔다.
3. Twitter 스트리밍 API호출하는 스크립트 작성
먼저 파이썬에서 사용할 패키지들을 미리 다운받는다.
그러기 위해서는 pip3를 설치해야 한다.
설치방법은 아래 글 참고!
https://earthconquest.tistory.com/224?category=888280
[Python] Linux CentOS 7에 파이썬 pip3 설치하기
pip는 파이썬으로 작성된 패키지 라이브러리들을 관리해주는 시스템이다. 만약 yum이 안될 경우 업데이트를 해준다. [root@localhost ~]# yum update [root@localhost ~]# yum install epel-release //pip를 설치..
earthconquest.tistory.com
나는 pip3의 패키지 설치 경로가 아래의 두 개의 경로와 같다.
이 경로들은 이따가 파이썬 코드에 추가해야 한다.
/usr/local/lib64/python3.6/site-packages
/home/hadoop01/.local/lib/python3.6/site-packages
pip3가 설치가 되었다면 아래 명령어로 필요한 패키지를 모두 다운받는다.
$ pip3 install --user datetime pymongo requests_oauthlib tqdm
파이썬으로 Twitter 스트리밍 API를 호출하는 코드를 아래와 같이 작성한다.
$ vim twitter-streaming.py#!/usr/bin/python3.6
# -*-coding:utf-8 -*
import sys #시스템 패키지
#pip3의 설치되는 패키지 디렉터리 2군데 적어주기
sys.path.append( '/home/hadoop01/.local/lib/python3.6/site-packages')
sys.path.append( '/usr/local/lib64/python3.6/site-packages')
import datetime
import json
import pymongo
import requests_oauthlib
import tqdm
#You sould get the API Key from Twiitter Developer site.
consumer_key = '~~~~~~~~~~~~~~~~~~~'
consumer_secret = '~~~~~~~~~~~~~~~~~~~'
access_token_key = '~~~~~~~~~~~~~~~~~~~'
access_token_secret = '~~~~~~~~~~~~~~~~~~~'
#Excute Twitter API
twitter = requests_oauthlib.OAuth1Session(
consumer_key, consumer_secret, access_token_key, access_token_secret)
uri = 'https://stream.twitter.com/1.1/statuses/sample.json'
r = twitter.get(uri, stream=True)
r.raise_for_status()
#print( r )
#sample tweets be saved to mongoDB
mongo = pymongo.MongoClient()
for line in tqdm.tqdm(r.iter_lines(), unit='tweets', mininterval=1):
if line:
tweet = json.loads(line)
#when receive data, append timestamp
tweet['_timestamp'] = datetime.datetime.utcnow().isoformat()
mongo.twitter.sample.insert_one(tweet)
이제 실행하면 아래와 같이 1초마다 트윗을 몽고디비에 저장한다.
$ python twitter-streaming.py디스크 용량을 고려해서 적당히 실행하다가 멈춰준다.
필자는 20분정도? 모았던 것 같다.
책에서는 1일치를 모았다.
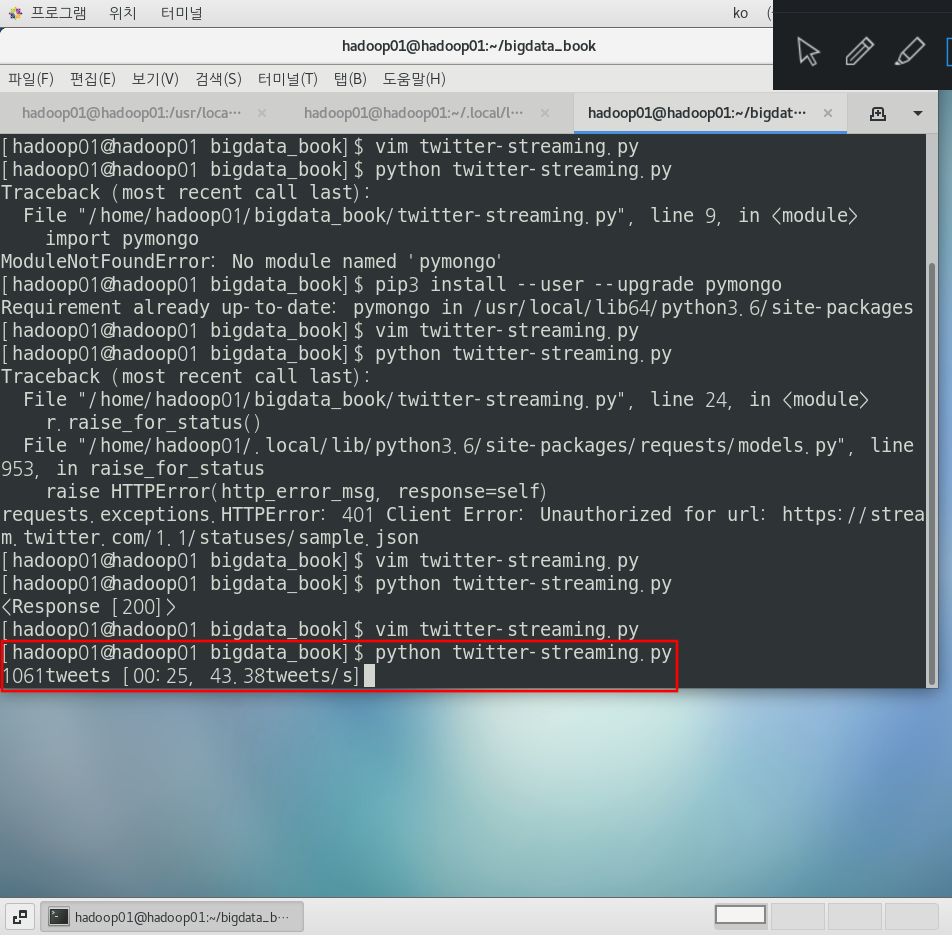
몽고디비에서 확인해본다.
$ mongoshow databases
show tables위 파이썬 코드에서 만들었던 twitter DB와 sample 테이블이 생성되어 있는 것을 확인할 수 있다.

4. 대화식 실행환경 준비
먼저 주피터 노트북과 pandas 패키지를 설치한다.
$ pip3 install --user pandas
$ pip3 install --user jupyter-client==6.1.12주피터 노트북을 실행한다.
$ jupyter-notebook
아래와 같이 몽고디비 접속하고 데이터 하나만 불러와본다.
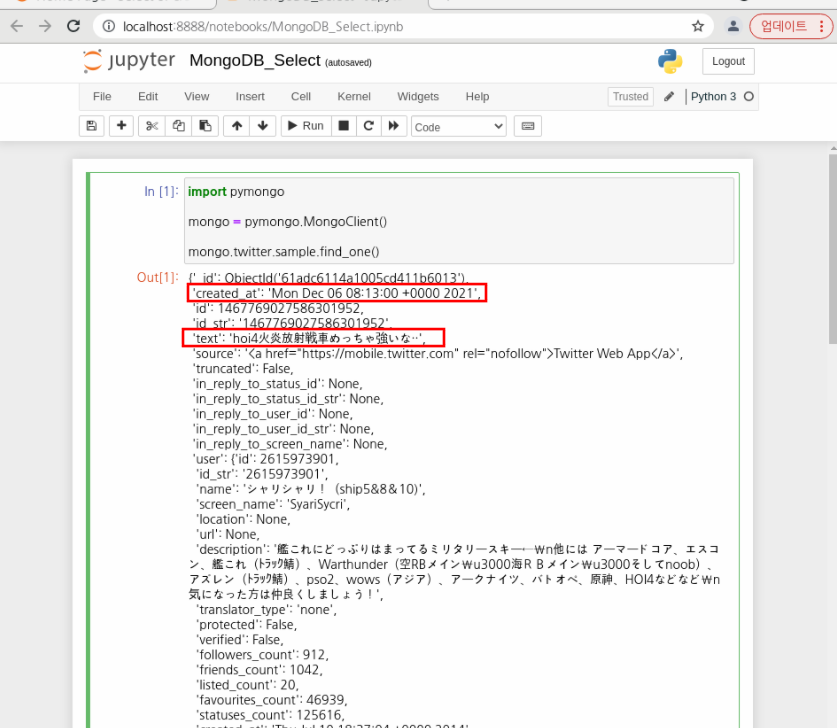
import pymongo
mongo = pymongo.MongoClient()
mongo.twitter.sample.find_one()
이제 흥미가 있는 필드만 출력해본다.
created_at과 text만 추출하는데 lang이 en인 트윗만 추출해본다.
주피터 노트북에 아래와 같이 코드를 작성하고 실행한다.
import pymongo
import pandas as pd
#MongoDB 접속
mongo = pymongo.MongoClient()
#예시로 하나만 출력해본다.
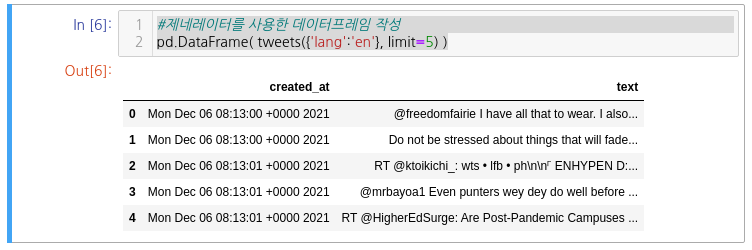
mongo.twitter.sample.find_one()#MongoDB로부터 레코드를 읽어들이는 제네레이터 함수
def tweets(*args, **kwargs):
for tweet in mongo.twitter.sample.find( *args, **kwargs ):
if 'delete' not in tweet:
yield {
'created_at': tweet['created_at'],
'text': tweet['text'],
}#제네레이터를 사용한 데이터프레임 작성
pd.DataFrame( tweets({'lang':'en'}, limit=5) )아래와 같이 결과가 나오는 것을 확인할 수 있다.
5. Spark에 의한 분산환경
5.1 Spark 설치하기
데이터양이 늘어나도 대응할 수 있도록 분산환경 빅데이터 처리 플랫폼인 Spark를 설치하고 이용한다.
먼저 스칼라를 설치한다.
$ wget https://downloads.lightbend.com/scala/2.12.10/scala-2.12.10.tgz
$ tar xvf scala-2.12.10.tgz
$ sudo mv scala-2.12.10 /usr/lib
$ sudo ln -s /usr/lib/scala-2.12.10 /usr/lib/scala
$ vi ~/.bashrc아래 환경변수를 적어준다.
$ export PATH=$PATH:/usr/lib/scala/bin
이제 스파크를 설치한다. 이때 분산모드가 아니므로 리소스매니저는 그냥 디폴트인 스탠다드얼론을 사용한다.
$ wget https://archive.apache.org/dist/spark/spark-2.4.7/spark-2.4.7-bin-hadoop2.7.tgz
$ tar -xvf spark-2.4.7-bin-hadoop2.7.tgz
$ sudo mkdir /usr/local/spark
$ sudo cp -r spark-2.4.7-bin-hadoop2.7/* /usr/local/spark
$ vi ~/.bashrc아래 두 줄을 추가한다.
export SPARK_EXAMPLES_JAR=/usr/local/spark/examples/jars/spark-examples_2.12-3.2.0.jar
PATH=$PATH:$HOME/bin:/usr/local/spark/bin환경변수가 추가된 .bashrc를 적용한다.
$ source ~/.bashrc
최종적인 환경변수는 아래와 같다.
# .bashrc
PATH=$PATH:$HOME/.local/bin:$HOME/bin
PATH=$PATH:$HOME/bin:/usr/local/spark/bin
export PATH=$PATH:/usr/lib/scala/bin
export SPARK_EXAMPLES_JAR=/usr/local/spark/examples/jars/spark-examples_2.12-3.2.0.jar
export PYSPARK_DRIVER_PYTHON=jupyter-console
export PYSPARK_SUBMIT_ARGS="--master local[2] pyspark-shell"
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-1.el7_9.x86_64/
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
# Uncomment the following line if you don't like systemctl's auto-paging feature:
# export SYSTEMD_PAGER=
# User specific aliases and functions
이제 스파크를 실행한다.
$ spark-shell
ctrl + c눌러서 종료하고
혹은 파이썬을 이용한 pyspark로 실행할 수 있다. 앞으로 예제는 파이스파크를 사용한다.
$ pyspark
먼저 다시 리눅스 쉘로 돌아와서
spar디렉터리의 conf 디렉터리로 가서 spark-env-sh.templeate을 spark-env-sh로 만들고 환경변수를 추가해준다.
#자신의 파이썬 위치 확인
$ which python
/usr/bin/python
$ cd spark-2.4.7-bin-hadoop2.7/conf
$ cp spark-env.sh.template spark-env.sh
$ vim spark-env.sh
그리고 아래 내용을 추가하는데 PYSPARK_PYTHON은 spark worker들이 사용할 python위치이고
PYSPARK_DRIVER_PYTHON은 스파크 드라이버가 사용할 파이썬인데 이 둘은 버전이 같아야 한다.
필자는 주피터와 로컬에 설치된 파이썬 버전은 python3.6.8이다.
export PYSPARK_PYTHON=/usr/bin/python
export PYSPARK_DRIVER_PYTHON=jupyter-console그리고 적용하고 재부팅해준다.
$ source spark-env.sh
$ reboot
5.2 MongoDB의 애드혹 집계
그리고 작업용 디렉터리를 만들어준다.
$ cd
$ mkdir ~/adhoc; cd ~/adhoc
이제 파이스파크를 기동하는데 몽고디비용 패키지를 추가해서 기동한다.
$ pyspark --packages org.mongodb.spark:mongo-spark-connector_2.11:2.2.0
이제 MongoDB로부터 데이터를 읽어들이기 위해서 Spark 세션을 통해 데이터 프레임을 작성해본다.
#Spark세션 정보에 접근하기 위한 변수
spark
#MongoDB로 부터 데이터가져와서 데이터프레임 형태로 변경
df = (spark.read
.format("com.mongodb.spark.sql.DefaultSource")
.option("uri", "mongodb://localhost/twitter.sample")
.load())
#데이터프레임을 일시적인 뷰로 등록
df.createOrReplaceTempView('tweets')
#언어별 트윗 수의 상위 3건 표시하는 쿼리 작성
query = '''
SELECT lang, count(*) count
FROM tweets
WHERE delete IS NULL
GROUP BY 1
ORDER BY 2 DESC
'''
#쿼리 실행
spark.sql(query).show(3)
5.3 텍스트 데이터 가공하기
이제 영어 트윗에 포함된 모든 단어를 세어본다.
다음과 같이 트윗을 추출한다.
#영어 트윗과 글작성 시간을 모두 추출한다.
en_query = '''
SELECT from_unixtime(timestamp_ms / 1000) time, text
FROM tweets
WHERE lang = 'en'
'''
#en_query를 실행해서 데이터프레임을 만든다.
en_tweets=spark.sql(en_query)
SparkSQL의 실행결과는 데이터프레임이므로 이것을 다시 파이썬 함수로 처리해야 한다.
지금과 같이 텍스트 데이터를 처리하고 싶으면 다음과 같이 파이썬 함수를 정의한다.
from pyspark.sql import Row
#트윗을 단어로 분해하는 제네레이터 함수
def text_split(row):
for word in row.text.split():
yield Row(time=row.time, word=word)Spark에서는 데이터 프레임의 1행의 레코드가 Row라는 객체에 보관되어 있다.
이것을 가공해서 다시 다음의 Row 객체를 만듦으로써 차례대로 데이터를 변환한다.
다음 코드를 실행함으로써 트윗을 단어로 분해한 새로운 데이터 프레임이 만들어지는 것을 알 수 있다.
#.rdd 로 원시 레코드 참조한다.
en_tweets.rdd.take(1)
#flatMap()에 위에서 정의한 제네레이터 함수를 적용
en_tweets.rdd.flatMap(text_split).take(2)
#toDF()를 이용해서 데이터프레임으로 변환
en_tweets.rdd.flatMap(text_split).toDF().show(2)
5.4 Spark DAG 실행하기
Spark 데이터 프레임을 토대로 RDD(Resilient Distributed Dataset)라 불리는 로우 레벨의 데이터 구조로 되어 있다.
이것을 사용하면 복잡한 MapReduce 작업을 손쉽게 할 수 있다.
위 코드에 이어서 아래 코드들을 실행한다.
#분해한 단어로 이루어진 뷰를 만든다.
words = en_tweets.rdd.flatMap(text_split).toDF()
#단어별 카운트의 상위 3건을 표시
wc_query='''
SELECT word, count(*) count
FROM words
GROUP BY 1
ORDER BY 2 DESC
'''
spark.sql(wc_query).show(3)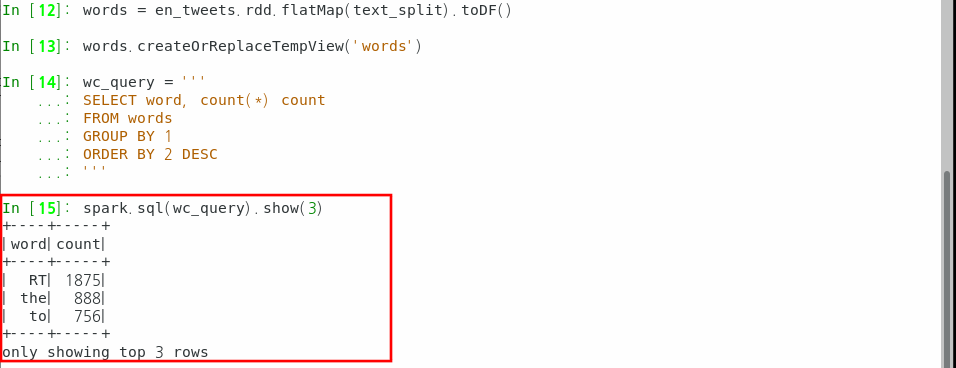
개념적으로 DAG란 비순환 그래프로서 아래 그림처럼 작업들이 순서가 있는 것을 의미한다.
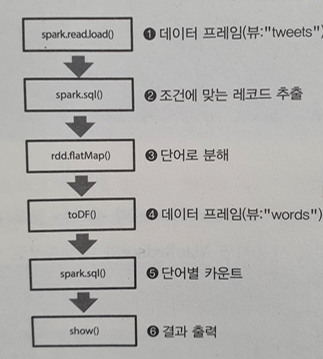
이러한 각 작업은 액션 오퍼레이션(위 그림에서는 show())만나기 전까지는 그냥 코드로만 존재하다가
show()와 같은 액션 오퍼레이션을 만나면 그제서야 코드가 순서대로 실행된다.
이를 지연평가 혹은 지연실행이라고 부른다.
위 그림에서 show() 이외에 메서드는 모두 변환 오퍼레이션이라고 부른다.
이렇게 지연실행을 하는 이유는 해당 액션 오퍼레이션을 실행하기 위한 최적의 변환 오퍼레이션을 수행하기 위해서이다.
즉, 위 코드처럼 간단한 코드가 아니라 여러 개의 변환 오퍼레이션이 있을 경우
효율적인 최적의 변환 오퍼레이션들만 거쳐서 액션 오퍼레이션이 실행되게 해준다.
이를 가능하게 하려면 순환 그래프가 아닌 한쪽 방향으로만 실행되는 비순환 그래프 DAG가 필요하다.
아무튼 위의 과정들을 매번 Spark 구동할 때마다 실행하면 번거로우니깐 테이블로 저장시킨다.
#분해한 단어를 테이블로 저장한다.
words.write.saveAsTable('twitter_sample_words')
#초기 설정에서는 'spark-warehouse'에 테이블이 만들어진다.
!ls -R spark-warehouse
6. 데이터를 집계해서 데이터 마트 구축하기
지금까지 데이터 집계를 했다면 추후에 데이터 시각화를 위한 데이터 마트를 구축해본다.
데이터 마트를 구축하는 데에는 여러가지 방법이 있겠지만 간단하게 csv파일을 만들어본다.
csv파일말고 그냥 RDBMS를 이용해서 데이터 마트를 구축할 수 있다.
일단 전체 데이터를 다 하기에는 시간이 많이 걸리므로 데이터를 작게 만든다.
#모든 레코드 수 확인하기
spark.table('twitter_sample_words').count()
#1시간마다 그룹화하여 집계하기
csv_query='''
SELECT substr(time, 1, 13) time, word, count(*) count
FROM twitter_sample_words
GROUP BY 1, 2
'''
spark.sql(csv_query).count()
위 그림과 같이 44682 레코드에서 17038로 데이터를 줄였다.
6.1 카디널리티 삭감
데이터에서 카디널리티란 유니크함의 정도라고 할 수 있다.
테이블에 중복된 데이터가 적으면 카디널리티가 높고
중복된 데이터가 많으면 카디널리티가 낮다.
그래서 테이블에서 Primary Key는 카디널리티가 높고
다른 컬럼들은 Primary Key에 비해 카디널리티가 낮다고 할 수 있다.
하나의 컬럼에서도 카디널리티가 높은 데이터들이 있을 수 있다.
예를 들어 정말 잘 안쓰는 말들은 데이터를 시각화해도 별 의미가 없다.
이러한 데이터들은 미리 제거를 해주는 것이 나중에 데이터 시각화할 때 유의미하고 신뢰성 있는 결과를
확보할 수 있다.
따라서 테이블 내에서 카디널리티가 높은 데이터 = 유니크한 데이터 = 잘 사용하지 않는 단어들을 제거한다.
먼저 아래 쿼리는 단어수가 적은 데이터를 집계해준다.
#단어수가 적은 단어의 수를 집계한다.
low_query='''
SELECT t.count, count(*) words
FROM ( SELECT word, count(*) count
FROM twitter_sample_words
GROUP BY 1) t
GROUP BY 1
ORDER BY 1
'''
spark.sql(low_query).show(3)
위 쿼리는 서브쿼리를 이용해서 단어수에 대한 단어의 개수를 보여주고 있다.
즉, 1번만 등장한 단어는 총 13,448개가 있고
2번 등장한 단어는 1,833개
3번 등장한 단어는 654개가 있다는 것이다.
쿼리에 대해서 간단히 설명하면
먼저 서브쿼리에서 각 단어별로 그룹화하고 그룹화된 단어의 개수가 나온다.
아버지 300
어머니 200
가방 100
뷁 1
쉙 2
강아지 1
블로그 1
강남 300
버스 100
이 서브 쿼리 결과는 t라는 임시 테이블이 되고
본 쿼리문에서 t.count는 서브쿼리의 count 결과를 나타낸다.
위 예시에서 300, 200, 100, 1, 2, 300을 의미한다.
이를 같은 숫자끼리 그룹화하고 개수를 나타내는데 오름차순으로 결과를 나타내면
1 3
2 1
100 2
200 1
300 2
이런식으로 된다.
아무튼 최종 결과를 보면 1번만 등장한 단어가 13448개로 많이 있는 것을 확인할 수 있다.
이러한 단어들은 시각화해봤자 큰 의미가 없으므로 정리한다.
정리를 위한 임시 테이블을 만든다.
임시 테이블은 단어 등장횟수가 5 이하의 단어를 'COUNT=' 문자열을 앞에 붙여준 category라는 컬럼으로 나타낸다.
필자는 트위터 데이터를 많이 수집하지 않아서 5로 했는데 많이한 분은 더 높게 해도된다.
책에서는 1000으로 한다.
#단어를 카테고리로 나누는 디멘전 테이블을 만든다.
category_query='''
SELECT word, count, IF(count > 5, word, concat('COUNT=', count)) category
FROM (
SELECT word, count(*) count
FROM twitter_sample_words
GROUP BY 1
) t
'''
spark.sql(category_query).show(50)
결과를 보면 등장횟수가 5이상인 단어는 'COUNT='가 붙지 않는 것을 확인할 수 있다.
#일시적인 뷰로 저장
spark.sql(category_query).createOrReplaceTempView('word_category')
이제 위 임시적인 뷰테이블을 이용해서 데이터 수를 줄인다.
레프트 조인을 사용해서 twitter_sample_words테이블과 word_category 뷰테이블에서
겹치는 단어를 뺀 단어만 출력시킨다.
#1시간마다 카테고리별로 그룹화하여 집계
low_csv_query='''
SELECT substr(a.time, 1, 13) time, b.category, count(*) count
FROM twitter_sample_words a
LEFT JOIN word_category b
ON a.word = b.word
GROUP BY 1, 2
'''
spark.sql(low_csv_query).count()
위 그림과 같이 842개의 데이터로 줄어든 것을 확인할 수 있다.
6.2 CSV 파일로 작성하기
Spark에서 집계결과를 CSV에 출력하려면 몇 가지 방법이 있다.
하나는 표준 spark-csv 라이브러리를 사용하는 것이다.
#아래 코드의 옵션 설명은 다음과 같다.
#coalese(): 출력파일 개수
#write.format() : CSV형식
#option() : 헤더 있음
#save() : 출력파일 저장할 디렉터리
(spark.sql(low_csv_query)
.coalesce(1)
.write.format('com.databricks.spark.csv')
.option('header', 'true')
.save('csv_output'))
#출력파일 확인
!ls csv_output/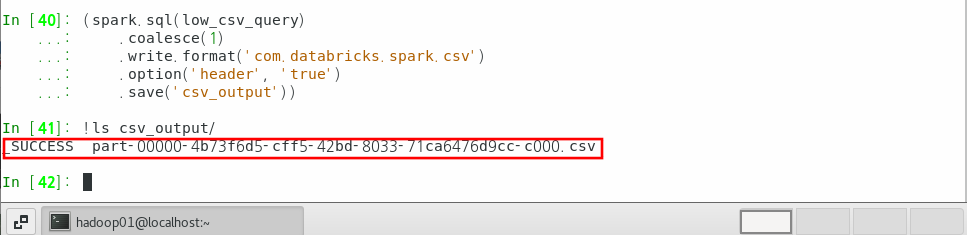
잘 저장된 것을 확인할 수 있다.
하지만 위 방법은 Spark 클러스터 상에서 실행되기 때문에, 대량의 데이터를 작성하는 데는 좋지만
지금처럼 작은 데이터를 보관하기에는 과하다.
이 정도의 데이터는 pandas의 데이터프레임으로 저장하는 편이 낫다.
#pandas의 데이터프레임으로 변환하기
result = spark.sql(low_csv_query).toPandas()
#데이터프레임 확인하기. 'time'이 도중에 끊겨 있다.
result.head(5)
#시간에서 끊어진 데이터를 pandas를 이용해서 수정해준다.
import pandas as pd
result['time'] = pd.to_datetime(result['time'])
result.head(5)
#변형후의 데이터프레임을 저장한다.
result.to_csv('word_summary.csv', index=False, encoding='utf-8')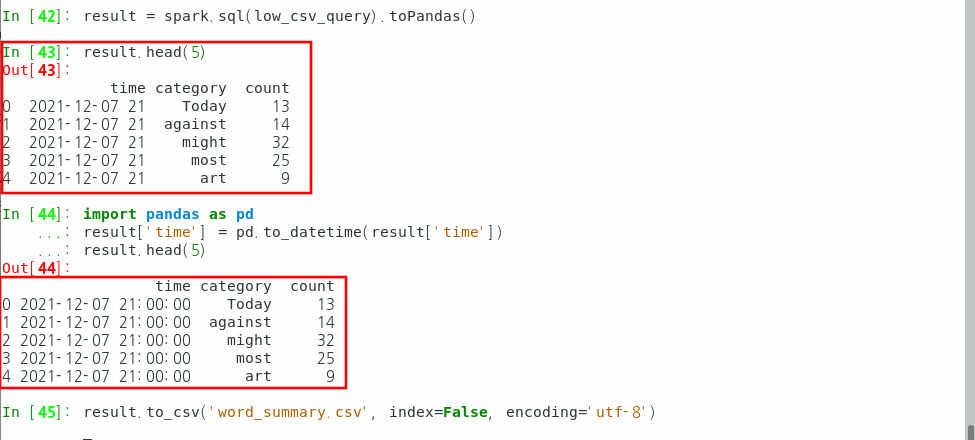
이제 이 csv파일로 워드클라우드를 한다든지 시각화를 할 수 있다.
여기까지 끝!
