
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- dfs
- 프로그래머스
- BigData
- BFS
- 알고리즘
- 영어
- 백준
- hadoop
- 양평
- 코엑스맛집
- Data Engineering
- 코딩
- 개발
- Data Engineer
- java
- apache iceberg
- 자바
- 용인맛집
- 코엑스
- 맛집
- Iceberg
- 코테
- 삼성역맛집
- Trino
- bigdata engineer
- bigdata engineering
- 파이썬
- 코딩테스트
- HIVE
- 여행
- Today
- Total
지구정복
[Hadoop] 맵리듀스 구현하기 (항공 출발 및 도착 지연 데이터 분석) 본문
미국규격협회에서 제공하는 미국 항공편 운항 통계 데이터(1987년~2008년)를
하둡의 맵리듀스를 이용하여 항공 출발 및 도착에 관한 데이터 분석을 실시한다.
1. 데이터 준비
미국 규격 협회의 Airline on-time performance 1987~2008년까지의 데이터를 사용한다.
아래 사이트에서 다운로드받을 수 있다.
https://community.amstat.org/jointscsg-section/dataexpo/dataexpo2009
-데이터 컬럼 정보

해당 csv 파일들을 모두 HDFS /user/hadoop01/input에 업로드 시킨다. 약 10분정도 걸린다.
[hadoop01@hadoop04 ~]$ hdfs dfs -mkdir input
[hadoop01@hadoop04 ~]$ hdfs dfs -ls /user/hadoop01/
[hadoop01@hadoop04 ~]$ hdfs dfs -put /home/hadoop01/dataexpo/*.csv input
[hadoop01@hadoop04 ~]$ hdfs dfs -count /user/hadoop01/input
1 26 11574571031 /user/hadoop01/input
-공통 클래스 구현
-AirlinePerformanceParser.java
package com.exam.chap05;
import org.apache.hadoop.io.Text;
public class AirlinePerformanceParser {
private int year;
private int month;
private int arriveDelayTime = 0;
private int departureDelayTime = 0;
private int distance = 0;
private boolean arriveDelayAvailable = true;
private boolean departureDelayAvailable = true;
private boolean distanceAvailable = true;
private String uniqueCarrier;
public AirlinePerformanceParser( Text text ) {
try {
String[] colums = text.toString().split( "," );
//운항연도설정
year = Integer.parseInt( colums[0] );
//운항 월 설정
month = Integer.parseInt( colums[1] );
//항공사 코드 설정
uniqueCarrier = colums[8];
//항공기 출발 지연 시간 설정
if( !colums[15].equals( "NA" ) ) {
departureDelayTime = Integer.parseInt( colums[15] );
} else {
departureDelayAvailable = false;
}
//항공기 도착 지연 시간 설정
if( !colums[14].equals("NA" ) ) {
arriveDelayTime = Integer.parseInt( colums[14] );
} else {
arriveDelayAvailable = false;
}
//운항 거리 설정
if( !colums[18].equals( "NA" ) ) {
distance = Integer.parseInt( colums[18] );
} else {
distanceAvailable = false;
}
} catch ( Exception e ) {
System.out.println( "Error parsing a record: " + e.getMessage() );
}
}
public int getYear() {
return year;
}
public int getMonth() {
return month;
}
public int getArriveDelayTime() {
return arriveDelayTime;
}
public int getDepartureDelayTime() {
return departureDelayTime;
}
public int getDistance() {
return distance;
}
public boolean isArriveDelayAvailable() {
return arriveDelayAvailable;
}
public boolean isDepartureDelayAvailable() {
return departureDelayAvailable;
}
public boolean isDistanceAvailable() {
return distanceAvailable;
}
public String getUniqueCarrier() {
return uniqueCarrier;
}
}//
2. 항공 출발 지연 데이터 분석
이제 각 년도의 월별로 항공기들의 총 지연횟수를 구해본다.
출발 지연 분석 맵리듀스 입출력 데이터 타입을 아래와 같이 정의한다.
| 클래스 | 입출력 구분 | 키 | 값 |
| 매퍼 | 입력 | 오프셋 | 항공 운항 통계 데이터 |
| 출력 | 운항연도, 운항월 | 출발 지연 건수 | |
| 리듀서 | 입력 | 운항연도, 운항월 | 출발 지연 건수 |
| 출력 | 운항연도, 운항월 | 출발 지연 건수 합계 |
-매퍼 구현하기
-DepartureDelayCountMapper.java
package com.exam.chap05;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class DepartureDelayCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
//맵 출력값 객체 생성
private final static IntWritable outputValue = new IntWritable(1);
//맵 출력키 객체 생성
private Text outputKey = new Text();
//맵 메소드 정의
public void map( LongWritable key, Text value, Context context ) throws IOException, InterruptedException {
AirlinePerformanceParser parser = new AirlinePerformanceParser(value);
//출력키 선언
outputKey.set( parser.getYear() + "," + parser.getMonth() );
if( parser.getDepartureDelayTime() > 0 ) {
//출력 데이터 생성
context.write( outputKey, outputValue );
}
}
}
-리듀서 구현하기
-DelayCountReducer.java
package com.exam.chap05;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class DelayCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable result = new IntWritable();
public void reduce( Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException {
int sum = 0;
for( IntWritable value : values ) sum += value.get();
result.set(sum);
context.write(key, result);
}
}
-드라이버 클래스 구현하기
-DepartureDelayCount.java
package com.exam.chap05;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class DepartureDelayCount {
public static void main(String[] args) throws IOException, Exception, InterruptedException {
Configuration conf = new Configuration();
//입출력 데이터 경로 확인
if( args.length != 2 ) {
System.err.println("Usage : DepartureDelayCount <input> <output> ");
System.exit(2);
}
//잡 정의
Job job = new Job( conf, "DepartureDelayCount" );
//입출력 데이터 경로 선언
FileInputFormat.addInputPath(job, new Path( args[0] ) );
FileOutputFormat.setOutputPath(job, new Path( args[1] ) );
//잡 클래스 선언
job.setJarByClass( DepartureDelayCount.class );
//매퍼 클래스 선언
job.setMapperClass( DepartureDelayCountMapper.class );
//리듀서 클래스 선언
job.setReducerClass( DelayCountReducer.class );
//입출력 데이터 포맷 설정
job.setInputFormatClass( TextInputFormat.class );
job.setOutputFormatClass( TextOutputFormat.class );
//출력키 및 출력값 데이터 타입 설정
job.setOutputKeyClass( Text.class );
job.setOutputValueClass( IntWritable.class );
//잡 실행 메소드
job.waitForCompletion( true );
}
}
-맵리듀스 실행하기
java 메이븐 프로젝트를 jar파일 형식으로 export한 뒤 하둡으로 실행시킨다.
데이터가 약 10GB정도 이므로 시간이 굉장히 오래 걸린다. 필자는 약 10분 걸렸다.
[hadoop01@hadoop01 ~]$ hadoop jar /home/hadoop01/eclipse/hadoopEx01.jar com.exam.chap05.DepartureDelayCount input dep_delay_count
이제 cat의 head와 tail로 결과를 확인해본다.
[hadoop01@hadoop01 ~]$ hadoop fs -cat dep_delay_count/part-r-00000 | head -10
1987,10 175568
1987,11 177218
1987,12 218858
1988,1 198610
1988,10 162211
1988,11 175123
1988,12 189137
1988,2 177939
1988,3 187141
1988,4 159216
[hadoop01@hadoop01 ~]$ hadoop fs -cat dep_delay_count/part-r-00000 | tail -10
2007,4 249097
2007,5 241699
2007,6 307986
2007,7 307864
2007,8 298530
2007,9 195615
2008,1 247948
2008,2 252765
2008,3 271969
2008,4 220864
이를 엑셀의 피벗차트로 표현해보면 아래와 같다.
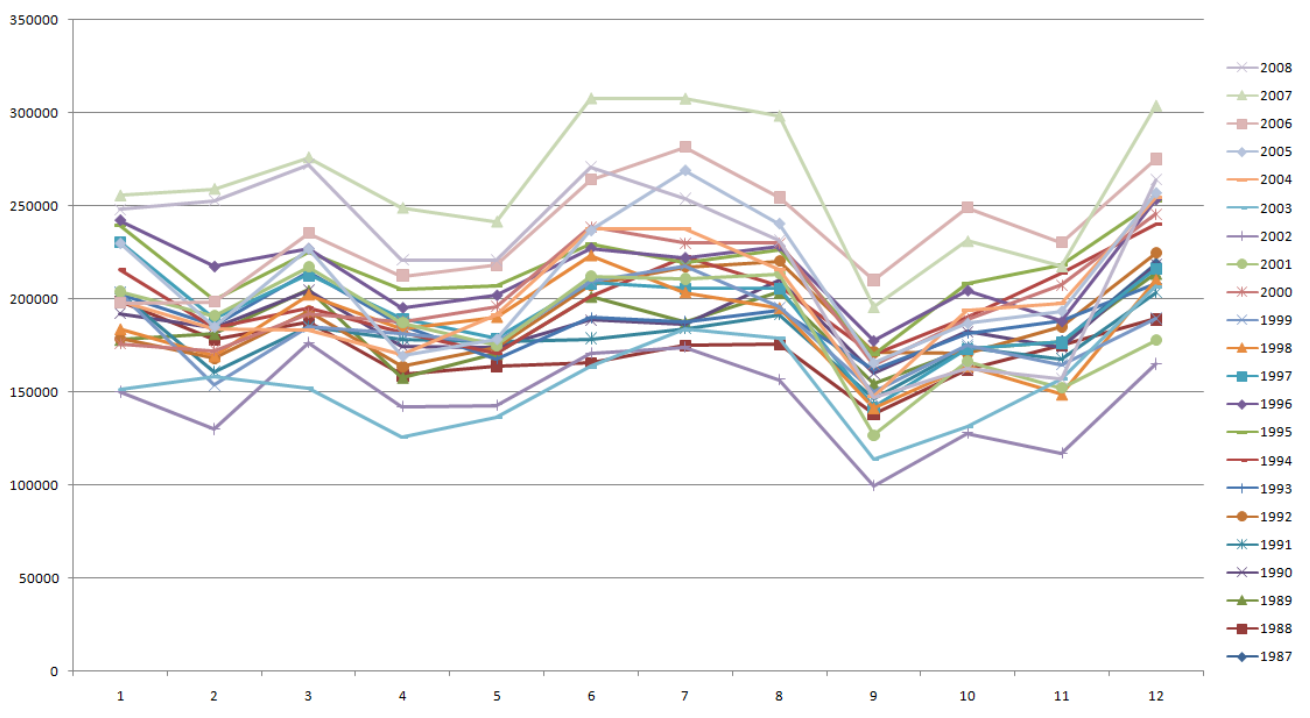
3. 항공 도착 지연 데이터 분석
이번에는 도착이 얼마나 지연이 됐는 지를 지연 건수를 통해 확인해본다.
-매퍼 구현하기
-ArrivalDelayCountMapper.java
package com.exam.chap05;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class ArrivalDelayCountMapper
extends Mapper<LongWritable, Text, Text, IntWritable> {
//맵 출력값
private final static IntWritable outputValue = new IntWritable(1);
//맵 출력키
private Text outputKey = new Text();
public void map( LongWritable key, Text value, Context context ) throws IOException, InterruptedException {
AirlinePerformanceParser parser = new AirlinePerformanceParser(value);
outputKey.set( parser.getYear() + "-" + parser.getMonth() + "," );
if( parser.getArriveDelayTime() > 0 ) {
//출력 데이터 생성
context.write( outputKey, outputValue );
}
}
}
-리듀서 구현하기
-DelayCountReducer2.java
package com.exam.chap05;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class DelayCountReducer2
extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException {
int sum = 0;
for( IntWritable value : values ) sum += value.get();
result.set( sum );
context.write(key, result);
}
}
-드라이버 클래스 구현하기
-ArrivalDelayCount.java
package com.exam.chap05;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class ArrivalDelayCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//입출력 데이터 경로 확인
if( args.length != 2 ) {
System.err.println("Usage: ArrivalDelayCount <input> <output>");
System.exit(2);
}
//잡 이름 설정
Job job = new Job( conf, "ArrivalDelayCount" );
//입출력 데이터 경로 설정
FileInputFormat.addInputPath( job, new Path(args[0]) );
FileOutputFormat.setOutputPath( job, new Path(args[1]) );
//잡 클래스 설정
job.setJarByClass( ArrivalDelayCount.class );
//매퍼 클래스 설정
job.setMapperClass( ArrivalDelayCountMapper.class );
//리듀서 클래스 설정
job.setReducerClass( DelayCountReducer2.class );
//입출력 데이터 포맷 설정
job.setInputFormatClass( TextInputFormat.class );
job.setOutputFormatClass( TextOutputFormat.class );
//출력키값 데이터 유형 설정
job.setOutputKeyClass( Text.class );
job.setOutputValueClass( Text.class );
job.waitForCompletion( true );
}
}
jar파일을 빌드하고 하둡으로 실행시킨다.
[hadoop01@hadoop01 ~]$ hadoop jar /home/hadoop01/eclipse/hadoopEx01.jar com.exam.chap05.ArrivalDelayCount input arr_delay_count
결과를 확인해본다.
[hadoop01@hadoop01 ~]$ hdfs dfs -cat /user/hadoop01/arr_delay_count/part-r-00000 | head -10
1987-10, 265658
1987-11, 255127
1987-12, 287408
1988-1, 261810
1988-10, 230876
1988-11, 237343
1988-12, 249340
1988-2, 242219
1988-3, 255083
1988-4, 219288
[hadoop01@hadoop01 ~]$ hdfs dfs -cat /user/hadoop01/arr_delay_count/part-r-00000 | tail -10
2007-4, 273055
2007-5, 275332
2007-6, 326446
2007-7, 326559
2007-8, 317197
2007-9, 225751
2008-1, 279427
2008-2, 278902
2008-3, 294556
2008-4, 256142
출처: 시작하세요 하둡프로그래밍
'데이터 엔지니어링 정복 > MapReduce' 카테고리의 다른 글
| [MapReduce] wordcount 직접 구현하기 (0) | 2021.05.24 |
|---|