
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- hadoop
- 삼성역맛집
- Trino
- Apache Kafka
- Iceberg
- 영어
- pyspark
- 백준
- 알고리즘
- bigdata engineering
- Linux
- 용인맛집
- Data Engineer
- BigData
- 여행
- 자바
- 코엑스맛집
- Spark
- 코딩
- bigdata engineer
- 코테
- Kafka
- 프로그래머스
- java
- 개발
- HIVE
- 코딩테스트
- Data Engineering
- 맛집
- apache iceberg
- Today
- Total
지구정복
[Flume] CentOS 7 리눅스에서 Flume 수동설치, 기본예제(spooldir source사용, HDFS싱크사용) 본문
[Flume] CentOS 7 리눅스에서 Flume 수동설치, 기본예제(spooldir source사용, HDFS싱크사용)
noohhee 2021. 5. 18. 13:23설치 전 pc환경
오라클 버추얼박스 이용해서 3개의 하둡서버중 Hadoop2란 서버에 flume설치예정
3개 하둡서버 생성과정은 아래 링크 참고
https://earthconquest.tistory.com/235?category=888284
1. 설치하기
먼저 플룸 홈페이지에 들어가서 tar파일을 다운받는다.
http://flume.apache.org/download.html





해당 파일을 /usr/local로 옮겨놓는다.
(옮기는 이유는 그냥 저 디렉토리에 자바랑 하둡이랑 다 모여있기때문에 그냥 옮겨놓는다.)
[root@hadoop02 local]# cd /home/hadoop/다운로드/
[root@hadoop02 다운로드]# mv apache-flume-1.9.0-bin /usr/local
[root@hadoop02 다운로드]# cd /usr/local
[root@hadoop02 local]# ll
긴 파일명 적기 귀찮으니깐 심볼릭링크를 설정한다.
[root@hadoop02 local]# ln -s apache-flume-1.9.0-bin/ flume
[root@hadoop02 local]# ll
이제 플룸을 쉽게 사용하도록 플룸 바이너리 경로를 환경변수인 PATH에 추가한다.
[root@hadoop02 local]# vi /etc/profile
shift + g 를 눌러서 맨 아래로 이동

:wq
export FLUME_HOME=/usr/local/flume
export PATH=$PATH:$FLUME_HOME/bin
export CLASSPATH=$CLASSPATH:$FLUME_HOME/lib/*.jar
profile파일을 적용시켜준다.
[root@hadoop02 local]# source /etc/profile
그리고 profile에 JAVA_HOME이 설정되어있지만 혹시 모르니 플룸 설정파일에서도 JAVA_HOME을 명시해주자.
[root@hadoop02 local]# cd /usr/local/flume/conf/
[root@hadoop02 conf]# cp flume-env.sh.template flume-env.sh
[root@hadoop02 conf]# ll
[root@hadoop02 conf]# vi flume-env.sh
아래와 같이 주석을 제거하고 경로를 추가한다. 나는 아래와 같은 경로로 되어있다.

:wq
플룸의 버전을 출력해보자. 버전이 아래와 같이 잘 나오면 성공!
플룸의 명령어는 flume-ng이다.
[root@hadoop02 local]# flume-ng version
Flume 1.9.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: d4fcab4f501d41597bc616921329a4339f73585e
Compiled by fszabo on Mon Dec 17 20:45:25 CET 2018
From source with checksum 35db629a3bda49d23e9b3690c80737f9
2. 기본 예제
플룸의 기본설정파일 template를 복사해서 수정해준다.
[root@hadoop02 conf]# cp flume-conf.properties.template flume-conf.properties
[root@hadoop02 conf]# ll
[root@hadoop02 conf]# vi flume-conf.properties기존 내용을 모두 지워준다.
vi킨 상태로 바로 아래명령어 입력하면 내용 싹 다 지워진다.
d shift+G먼저 spooldir 소스를 사용하기위해 spooldir 디렉토리를 생성해주자.
spooldir은 플룸이 특정 디렉토리를 모니터링하고 있다가 그 디렉토리에 파일이 들어오면 데이터를 수집하는 방식이다
mkdir에서 -p 옵션을주면 하위 디렉토리까지 한 방에 만든다.
[root@hadoop02 ~]# mkdir -p /home/hadoop/working/test
그리고 플룸 설정을 아래와 같이 적어준다.
vi 편집기에 줄번호를 나오게하려면 vi 편집기 킨 상태에서
:set nu
를 적어준다.

agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /home/hadoop/working/test
agent1.sinks.sink1.type = logger
agent1.channels.channel1.type = file
:wq
플룸에서 에이전트란 '소스-채널-싱크'의 한 묶음을 에이전트라 한다 대용량 데이터를 수집할 때는 하나의 에이전트로는 부족하므로 여러 개의 에이전트가 있을 것이다. 다수의 에이전트가 있을 경우에도 위 파일에 모두 적어준다.
예제에서는 하나만 사용한다.
1~3줄 : 하나의 소스, 채널, 싱크를 컴포넌트라고 한다. 각 컴포넌트 이름을 선언한다.
5~6줄 : 소스와 싱크간에 채널로 연결해준다. 이때 소스의 채널은 channels이고 싱크의 채널은 channel인데 이는
소스는 여러 개의 채널에 데이터를 줄 수 있지만 싱크는 하나의 채널로만 데이터를 받을 수 있기 때문이다.
채널이 여러 개인 경우 소스는 다양한 채널에 데이터 공급가능하지만 싱크는 여러 개의 채널 중에서 특정 채널의
데이터만 공급받을 수 있다.
8~9줄 : 소스에 대한 설정을 해준다. 위에서 설명한 대로 spooldir을 설정하고 디렉토리 위치를 설정해준다.
11줄 : 싱크의 설정을 해준다. 싱크 타입은 logger로 소스-채널로 받은 데이터를 로그로 기록하라는 것이다.
13줄 : 채널타입을 설정한다. 파일 채널을 사용하면 채널의 이벤트를 저장하기 때문에 지속성을 보장할 수 있다.
이제 플룸을 실행한다. flume/conf 디렉토리로 이동한다. 명령어는 아래와 같다.
한 줄 작성하고 \ 를 누르면 엔터치면 아래줄로 이동한다.
[root@hadoop02 conf]# cd /usr/local/flume/conf
[root@hadoop02 conf]# flume-ng agent \
-n agent1 \
-c $FLUME_HOME/conf \
-f flume-conf.properties \
-Dflume.root.logger=INFO, console
--conf-file은 위에서 작성한 파일명이다.
--n은 위에서 작성한 agent명이다.
--c 는 플룸의 설정파일들이 어디에있는지 경로이다.
이제 새로운 터미널을 열고 /home/hadoop/working/test로 가서 아무 텍스트파일을 만들어보자.
[root@hadoop02 ~]# cd /home/hadoop/working/test/
[root@hadoop02 test]# echo "HEllo flume" > ./file1.txt
[root@hadoop02 test]# ll
합계 1
-rw-r--r--. 1 root root 12 5월 18 13:15 file1.txt.COMPLETEDll 명령얼로 파일을 보면 뒤에 .COMPLETED가 된 것을 확인할 수 있다.
이제 플룸 로그를 확인해보자.
[root@hadoop02 ~]# cd /usr/local/flume/conf/log
[root@hadoop02 logs]# vi flume.log shift + g로 맨 아래로 내려가면 아래 사진처럼 이벤트 기록을 확인할 수 있다.
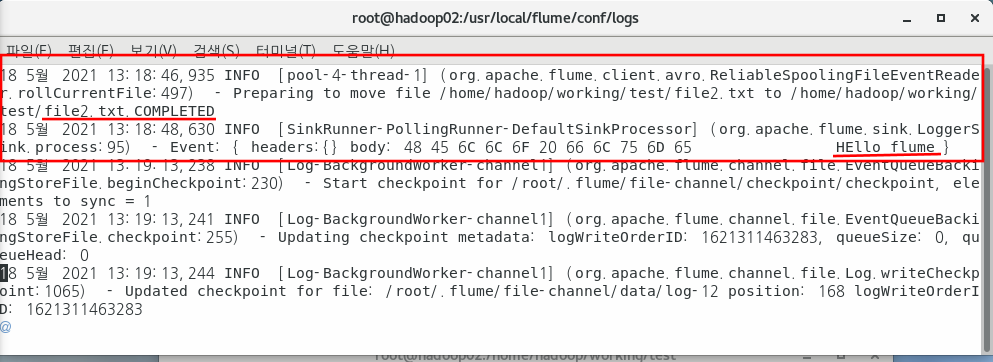
이렇게 되면 플룸이 처리를 완료한 것이다. 뒤에 COMPLETED가 되면 더 이상 해당 파일로 접근하지 않는다.
3. HDFS 싱크이용해서 HDFS에 데이터 적재하기
먼저 conf디렉토리로 이동해서 flume conf파일을 HDFS싱크로 수정한다. 파일을 복사한다.
[root@hadoop02 ~]# cd /usr/local/flume/conf
[root@hadoop02 conf]# cp flume-conf.properties spool-to-hdfs.properties
[root@hadoop02 conf]# vi spool-to-hdfs.properties

agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /home/hadoop/working/test
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.sinks.hdfs-sink.rollSize = 268435456
agent1.sinks.sink1.hdfs.rollInteval = 0
agent1.sinks.sink1.hdfs.rollCount = 0
agent1.sinks.sink1.hdfs.filePrefix = events
agent1.sinks.sink1.hdfs.fileSuffix = .log
agent1.sinks.sink1.hdfs.inUsePrefix = _
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.channels.channel1.type = file
그리고 하둡에 디렉토리를 생성한다.
[root@hadoop01 local]# hadoop fs -mkdir -p /tmp/flume
HDFS 웹UI에서 바로 만들어도된다. UI에서 확인해보자. 잘 생성된 것을 알 수 있다.

그리고 플럼을 실행시킨다.
[root@hadoop02 conf]# flume-ng agent -n agent1 -c $FLUME_HOME/conf -f spool-to-hdfs.properties -Dflume.root.logger=INFO, console
이때 만약 하둡3버전을 사용하는 분은
~/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar 을 flume lib디렉토리로 복사시켜주고
flume lib디렉토리에 있던 기존 guava.jar파일은 이름을 수정해준다.
cd hadoop/share/hadoop/common/lib/
cp guava-27.0-jre.jar /home/hadoop01/flume/lib/
cd
cd flume/lib/
ll guava*
mv guava-11.0.2.jar guava-11.0.2.jar.bak
ll guava*
그리고 spooldir 디렉토리로 이동해서 아무 파일을 만든다. 숨김파일로 만들고 일반파일로 바꿔보자.
파일명 앞에 . 이 붙으면 숨김파일이 된다. .file1.txt 처럼
[root@hadoop02 test]# echo -e "Hello\nAgain\nFlume" > ./.file1.txt
[root@hadoop02 test]# mv .file1.txt file1.txt
이제 hdfs에 적재가 되었는지 확인해보자.
[root@hadoop02 conf]# hadoop fs -ls /tmp/flume
Found 1 items
-rw-r--r-- 2 root supergroup 18 2021-05-18 18:15 /tmp/flume/events.1621329300545.log
내용을 확인해보자.
[root@hadoop02 conf]# hadoop fs -cat /tmp/flume/events.1621329300545.log
Hello
Again
Flume
웹UI에서도 확인해보자. 잘 생성된 것을 확인할 수 있다.
