
지구정복
[Hadoop & Hive & Presto] 일일 Twitter 데이터 배치 처리하기 | 빅데이터를 지탱하는 기술 본문
[Hadoop & Hive & Presto] 일일 Twitter 데이터 배치 처리하기 | 빅데이터를 지탱하는 기술
eeaarrtthh 2021. 12. 24. 20:46* 참고: 빅데이터를 지탱하는 기술(책)
* 환경
윈도우10
버추얼박스 5.2.44
리눅스 CentOS 7.9.2009
자바 버전: openjdk version "1.8.0_292"
Embulk 버전:
Hadoop 버전:
Hive 버전:Presto 버전:MongoDB 버전: 4.4
자바는 아래 블로거님 글 참고
https://bamdule.tistory.com/57
[Linux] CentOS 7에 OpenJDK 1.8 설치
1. open-jdk 1.8 설치 # yum install java-1.8.0-openjdk # yum install java-1.8.0-openjdk-devel 설치가 완료되면 /usr/bin/경로에 java가 생성됩니다. 2. 환경변수 등록 /usr/bin/java 경로에 심볼릭링크가 걸..
bamdule.tistory.com
1. 사전작업
먼저 아래 글에서 mongoDB 설치와 트위터 데이터 수집까지 하고나서 아래 내용들을 진행하면 된다.https://earthconquest.tistory.com/397
[Python & MongoDB & Spark] Twitter내용 데이터 분석하기
출처 : 빅데이터를 지탱하는 기술(책) 아래 실습을 따라하시려면 버전을 모두 맞춰주세요! 안 그러면 에러와 씨름합니다. ㅎ * 환경 윈도우10 버추얼박스 1개 머신에 CentOS 7.9.2009 설치하고 진행 자
earthconquest.tistory.com
2. 일일 배치를 태스크화하기
정기적으로 데이터를 전송하고 그것을 집계한 후 데이터 마트를 만드는 전형적인 데이터 파이프라인을 고려한다.
데이터 소스는 MongoDB를 이용한다. 장기적인 데이터 분석을 위해 Hive로 열 지향 스토리지를 만들고,그것을 Presto로 집계한다.
2.1. Embulk에 의한 데이터 추출
MongoDB로부터 데이터를 추출하기 위해 오픈 소스의 벌크 전송 도구인 Embulk를 사용한다.Embulk란 Sqoop과 거의 같은 기능을 하는 솔루션으로 여러 데이터 소스로 부터 데이터를 가져와서 제공해주는 솔루션이다.
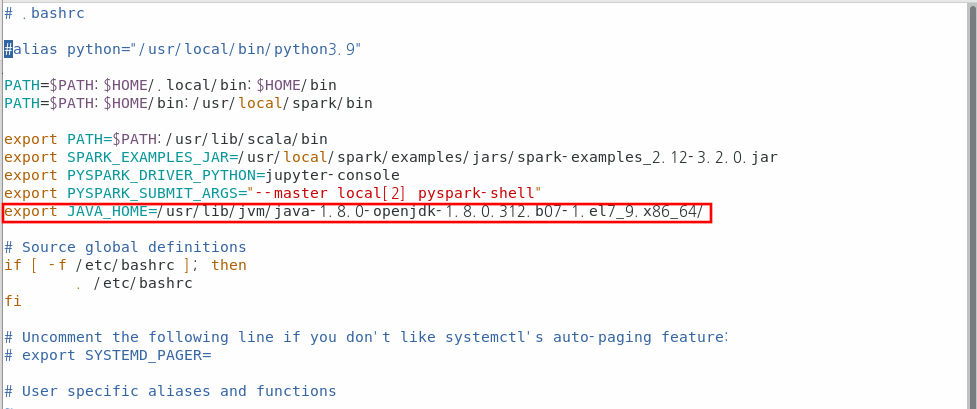
Embulk를 사용하기 위해서는 자바가 설치되어있고 환경변수로 등록이 되어 있어야 한다.JAVA_HOME이외의 나머지 환경변수는 무시하면 된다.
Embulk를 설치한다.
#설치
$ curl --create-dirs -o ~/.embulk/bin/embulk -L "https://dl.embulk.org/embulk-latest.jar"
#권한 변경
$ chmod +x ~/.embulk/bin/embulk
#환경변수 설정
$ echo 'export PATH="$HOME/.embulk/bin:$PATH"' >> ~/.bashrc
#환경변수 적용
$ source ~/.bashrcMongoDB와 연동해야 하므로 관련 플러그인을 설치한다.
$ embulk gem install embulk-input-mongodb embulk-formatter-jsonl
이제 아래 쉘스크립트를 작성하고 embulk로 실행시켜보자.
$ vim extract.sh#!/bin/bash
#추출하는 시간의 범위(파라미터)
START="$1"
END="$2"
cat >config.yml <<EOF
in:
#MongoDB로부터 지정한 날짜의 레코드 추출
type: mongodb
uri: mongodb://localhost:27017/twitter
collection: sample
query: '{ "_timestamp": { \$gte: "${START}", \$lt: "${END}" }}'
projection: '{ "timestamp_ms": 1, "lang":1, "text": 1 }'
out:
#Json파일로 출력
type: file
path_prefix: /tmp/twitter_sample_${START}/
file_ext: json.gz
formatter:
type: jsonl
encoders:
- type: gzip
EOF
#출력디렉터리 초기화
rm -rf /tmp/twitter_sample_${START}
mkdir /tmp/twitter_sample_${START}
#데이터 추출 실행
embulk run config.yml쉘스크립트를 실행한다. 이때 보통 일일단위이지만 실습에서는 100년 단위로 다 가져와본다.
$ bash extract.sh 2021-12-07 2121-12-07데이터를 확인하기위해 gzip 을 설치해주어야 한다.
아래 명령어로 gzip을 설치해준다.
$ sudo yum install -y gzip
혹시 yum에서 아래와 같은 에러가 나온다면 yum파일에서 python버전이 맞지 않아서 생긴다.
두 개의 파일 모두 python2.7로 바꿔준다.
File "/bin/yum", line 30
except KeyboardInterrupt, e:
^
SyntaxError: invalid syntax아래와 같이 해결한다.
$ sudo vim /bin/yum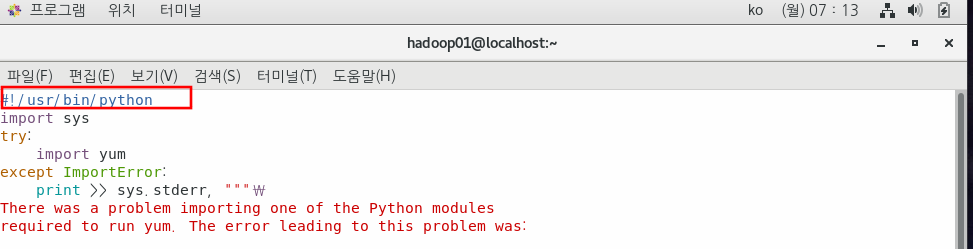
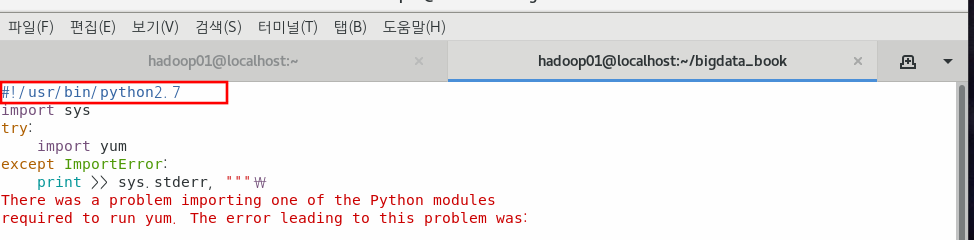
아래 파일도 수정해준다.
$ sudo vim /usr/libexec/urlgrabber-ext-down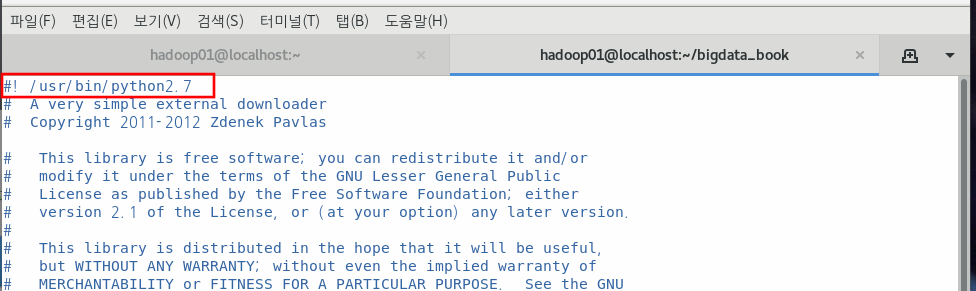
이제 다시 gzip 패키지를 설치해주고 아래 명령어로 데이터가 잘 추출되었는지 확인한다.
$ zcat /tmp/twitter_sample_2021-12-07/000.00.json.gz | head -1
2.2. Hive에 의한 데이터 구조화
이제 Hadoop과 Hive를 설치한다.
Hadoop 3.1.2 버전을 설치한다.
그 전에 공개키를 만들어준다.
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
$ ssh localhost
yes
$ exit
$ wget https://archive.apache.org/dist/hadoop/core/hadoop-2.10.1/hadoop-2.10.1.tar.gz
$ tar -xvf hadoop-2.10.1.tar.gz
먼저 Hive에 필요한 디렉터리를 생성해준다.
$ sudo mkdir -p /user/hive/warehouse
$ sudo chown $USER /user/hive/warehouse
$ mv hadoop-2.10.1 hadoop환경변수를 등록한다.
$ vim ~/.bashrcexport HADOOP_HOME=/home/hadoop01/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin$ source ~/.bashrcHadoop 옵션에 Java Home을 등록한다.
JAVA_HOME환경변수와 그대로 등록해준다.
$ echo $JAVA_HOME
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-1.el7_9.x86_64/$ cd /home/hadoop01/hadoop/etc/hadoop/
이제 추가적으로 Hadoop실행을 위한 설정을 해준다.
$ vim core-site.xml<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
$ vim hdfs-site.xml<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop01/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop01/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
$ vim mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
$ vim yarn-site.xml<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
이제 Hadoop을 초기화하고 실행한다.
$ cd
$ hadoop namenode -format대문자 Y입력
실행을 한다.
$ cd hadoop/sbin
$ ./start-all.sh
잘 실행되는지 확인한다.
$ hadoop version
$ jps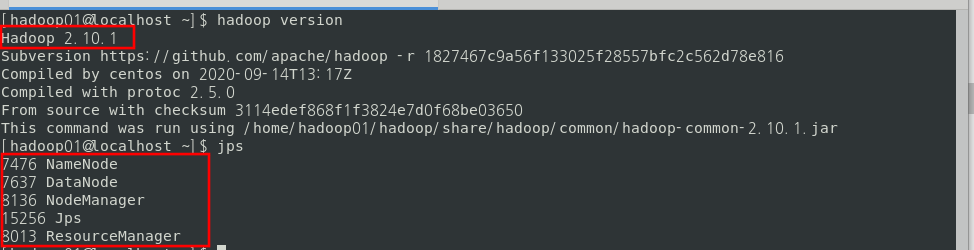
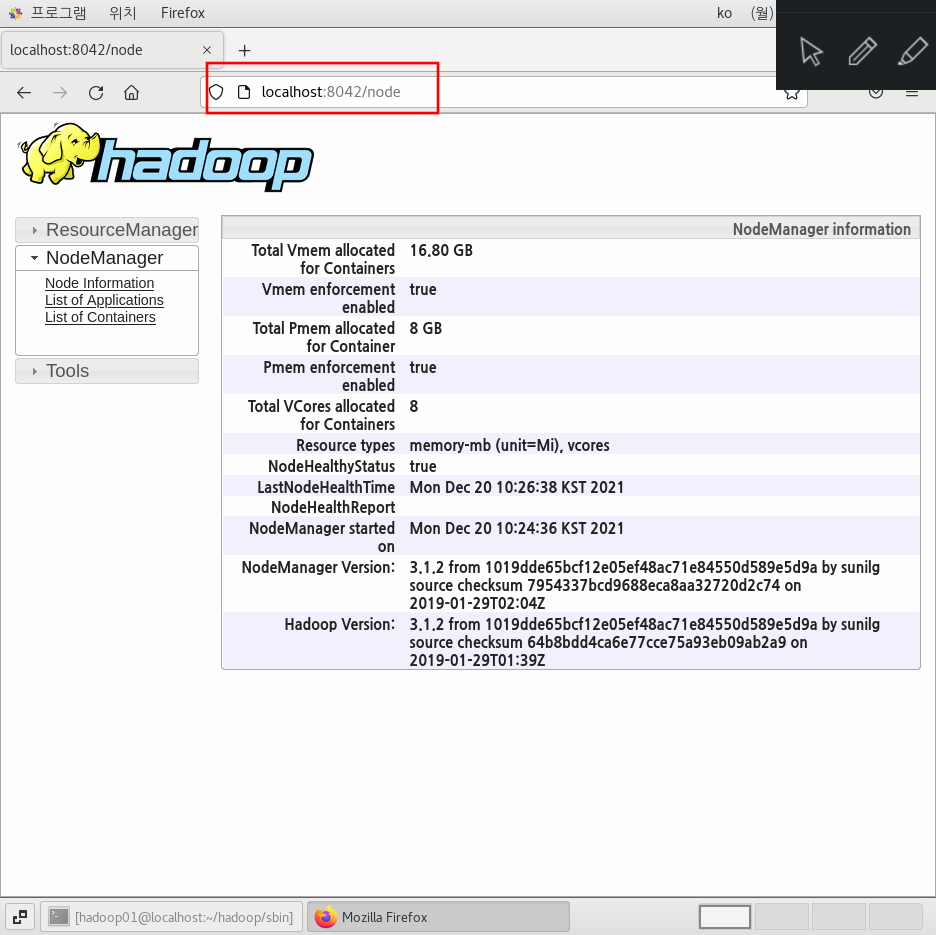
웹에서 확인해본다.
http://localhost:8042
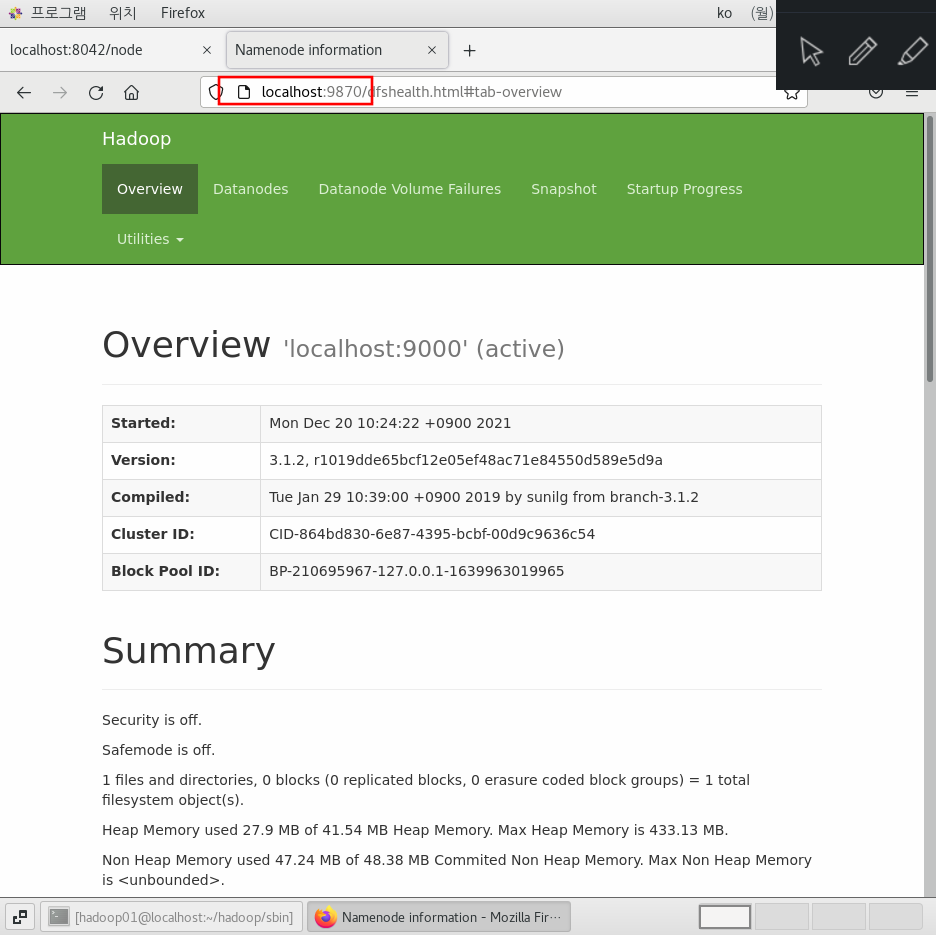
http://localhost:9870
예시로 워드카운트를 실행해보자.
$ hdfs dfs -mkdir -p /user/word/
$ hdfs dfs -put /home/hadoop01/hadoop/LICENSE.txt /user/word/
$ hadoop jar /home/hadoop01/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.1.jar wordcount /user/word/LICENSE.txt /user/word/output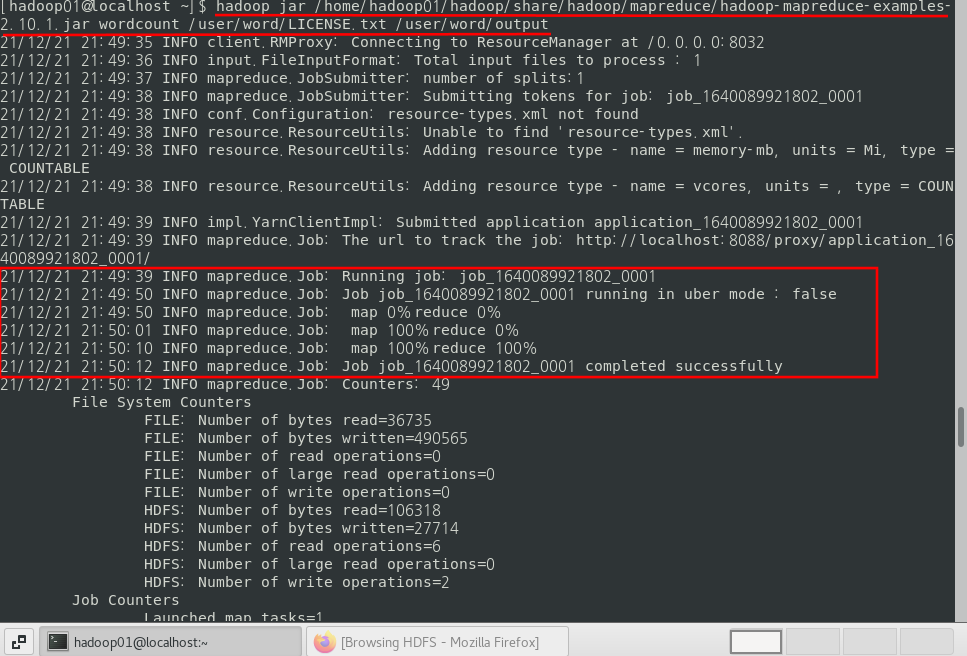
이제 결과를 확인해본다.
$ hdfs dfs -lsr /user/word/output/
$ hdfs dfs -cat /user/word/output/part-r-00000또한 하둡 웹 UI와 HDFS 웹 UI에 잘 들어가는지 확인한다.
하둡 UI - http://localhost:8088/
HDFS UI - http://localhost:50070/
하둡이 잘 설치된 것 같으니
Hive 설치파일을 다운로드해준다.
$ wget https://dlcdn.apache.org/hive/hive-2.3.9/apache-hive-2.3.9-bin.tar.gz위 주소가 설치가 안되면 직접 hive 사이트 들어가서 2.x 버전대에서 ~.bin.tar.gz 파일의 링크를 복사해서
wget 명령어로 다운로드받자.
https://www.apache.org/dyn/closer.cgi/hive/
Apache Downloads
We suggest the following site for your download: https://dlcdn.apache.org/hive/ Alternate download locations are suggested below. It is essential that you verify the integrity of the downloaded file using the PGP signature (.asc file) or a hash (.md5 or .s
www.apache.org
$ tar -xvf apache-hive-2.3.9-bin.tar.gz그리고 hive설정파일에서 metastore에 대한 설정을 해준다.
$ cd apache-hive-2.3.9-bin/conf/
$ vim hive-site.xml<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://localhost:9083</value>
</property>
</configuration>
~하이브에서 하둡을 연동해준다.
$ cd apache-hive-2.3.9-bin/conf/
$ cp hive-env.sh.template hive-env.sh
$ vim hive-env.sh
:set nu48번 줄에 HADOOP_HOME 환경변수를 설정해준다.

Hive 메타스토어를 기본DB인 derbyDB를 사용한다.
$ cd /home/hadoop01/apache-hive-2.3.9-bin/bin
$ ./schematool -initSchema -dbType derbycomplete라는 문구와 함께 metastore_db 디렉터리가 만들어진 것을 확인할 수 있다.
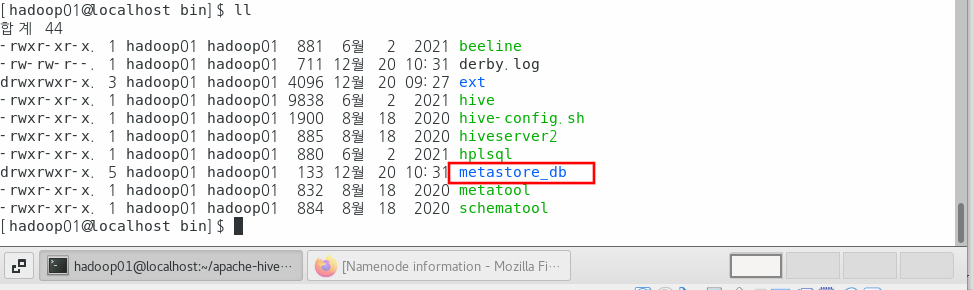
이제 hive 메타스토어 서비스를 기동시킨다.
$ ./hive --service metastore
위 사진처럼 기동시켜놓고 터미널 새로운 탭에서 실습을 진행한다.
먼저 Hive가 잘 작동되는지 예시 테이블을 만들고 데이터를 입력 및 조회해보자.
derby 메타데이터는 위에 처럼 실행시켜 놓고
터미널 새로운 탭을 연다.
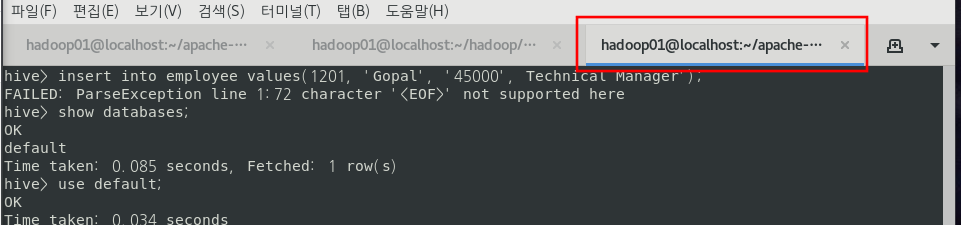
새로운 탭에서 Hive Interface를 작동시킨다.
$ cd /home/hadoop01/apache-hive-2.3.9-bin/bin
$ ./hive
(현재 Hive Metastroe 기동중, Hadoop 기동중이어야 한다.)
새로운 탭을 열어서 jps 명령어를 치면 아래와 같다.

Hive Interface에서 아래 쿼리를 차례대로 실행시킨다.
use default;
CREATE TABLE IF NOT EXISTS employee(
eid INT,
name STRING,
salary STRING,
destination STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
INSERT INTO employee VALUES ( 1201, 'Gopal', '45000', 'Technical Manager');아래와 같이 Insert 문을 실행시키면 하둡의 맵리듀스가 실행된다.
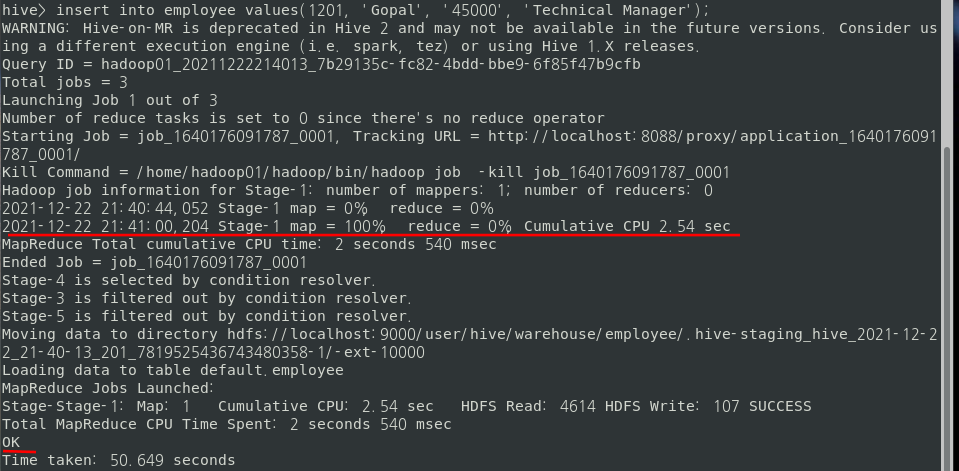
다음 조회를 해보면 결과가 잘 나오는 것을 확인할 수 있다.
SELECT * FROM employee;
이제 원래의 목적인 실습을 진행해본다.
먼저 Hive Interface를 종료시킨다.
그리고 Hive에 의한 데이터 구조화 쿼리를 만든다.
> exit;
$ cd /home/hadoop01/apache-hive-2.3.9-bin/binHDFS에 먼저 json파일을 집어넣어준다.
#HDFS의 /tmp 디렉터리에 모든 권한을 부여한다.
$ hdfs dfs -chmod -R 777 /tmp
#로컬에 있는 000.00.json파일을 HDFS에 업로드시킨다.
$ hdfs dfs -put /tmp/twitter_sample_2021-12-07/000.00.json /tmp/twitter_sample_2021-12-07/000.00.json
#업로드가 잘 되었는지 확인한다.
$ hdfs dfs -lsr /tmp/twitter_sample_2021-12-07/
이제 hive파일을 작성해준다.
$ cd /home/hadoop01/apache-hive-2.3.9-bin/bin
$ vim load.hql아래 # 주석은 모두 제거해주세요.
#Json 파일을 읽어들이기 위한 라이브러리
ADD JAR /home/hadoop01/apache-hive-2.3.9-bin/hcatalog/share/hcatalog/hive-hcatalog-core-2.3.9.jar;
#Json 파일을 읽어들이기 위한 외부 테이블
CREATE TEMPORARY EXTERNAL TABLE twitter_sample(
`record` struct<timestamp_ms:string, lang:string, text:string>
)ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS TEXTFILE
LOCATION '/tmp/twitter_sample_${START}/';
#출력 테이블(파티션 분할, ORC형식)
CREATE TABLE IF NOT EXISTS twitter_sample_words(
time timestamp, word string
)
PARTITIONED BY(pt string) STORED AS ORC;
#날짜 지정으로 파티션 덮어쓰기
INSERT OVERWRITE TABLE twitter_sample_words PARTITION (pt='${START}')
SELECT from_unixtime(cast(record.timestamp_ms / 1000 AS bigint)) time, word
FROM twitter_sample
LATERAL VIEW explode(split(record.text, '\\s+')) words AS word
WHERE record.lang = 'en'
ORDER BY time;ADD JAR /home/hadoop01/apache-hive-2.3.9-bin/hcatalog/share/hcatalog/hive-hcatalog-core-2.3.9.jar;
CREATE TEMPORARY EXTERNAL TABLE twitter_sample(
`record` struct<timestamp_ms:string, lang:string, text:string>
)ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS TEXTFILE
LOCATION '/tmp/twitter_sample_${START}/';
CREATE TABLE IF NOT EXISTS twitter_sample_words(
time timestamp, word string
)
PARTITIONED BY(pt string)
STORED AS ORC;
INSERT OVERWRITE TABLE twitter_sample_words PARTITION (pt='${START}')
SELECT from_unixtime(cast(record.timestamp_ms / 1000 AS bigint)) time, word
FROM twitter_sample
LATERAL VIEW explode(split(record.text, '\\s+')) words AS word
WHERE record.lang = 'en'
ORDER BY time;위에서 작성한 hive파일을 실행시켜준다.
이때 Hive Metastore와 Hadoop이 모두 실행되어 있어야 한다!!
$ ./hive -f load.hql -d START=2021-12-07아래와 같이 모두 성공적으로 실행됐다.
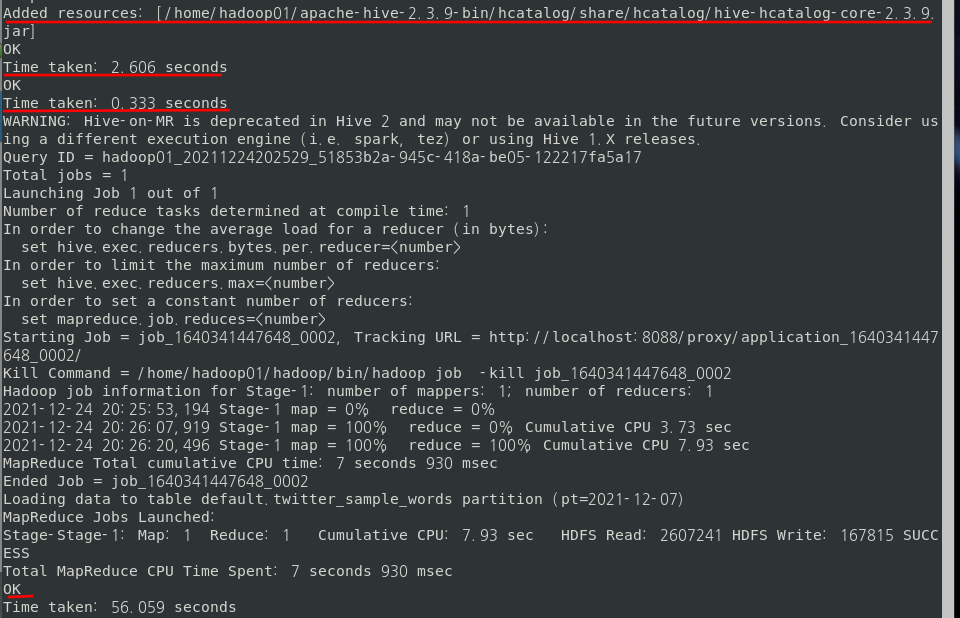
직접 Hive Interface에 접속해서 확인해보자.
#Hive 실행하기
$ ./hivehive> show databases;
OK
default
Time taken: 0.2 seconds, Fetched: 1 row(s)
hive> use default;
OK
Time taken: 0.068 seconds
hive> show tables;
OK
twitter_sample_words
Time taken: 0.048 seconds, Fetched: 4 row(s)
hive> select count(*) from twitter_sample_words;
OK
44668
Time taken: 3.416 seconds, Fetched: 1 row(s)
hive> select * from twitter_sample_words limit 10;
OK
2021-12-07 21:30:08 This 2021-12-07
2021-12-07 21:30:08 RT 2021-12-07
2021-12-07 21:30:08 is 2021-12-07
2021-12-07 21:30:08 a 2021-12-07
2021-12-07 21:30:08 tremendous 2021-12-07
2021-12-07 21:30:08 time 2021-12-07
2021-12-07 21:30:08 ⠀ 2021-12-07
2021-12-07 21:30:08 for 2021-12-07
2021-12-07 21:30:08 us 2021-12-07
2021-12-07 21:30:08 to 2021-12-07
Time taken: 0.546 seconds, Fetched: 10 row(s)
쿼리에 건넬 파라미터(-d START=2021-12-07)를 매일매일의 날짜로 바꾸면 새로운 파티션이 계속 만들어지고,
그에 따라 시간으로 파티션이 분할된 시계열 테이블이 완성된다.
출력테이블의 'time'컬럼에는 Twitter의 타임스탬프(timestamp_ms)를 보관하여 ORDER BY로 정렬한다.
이것이 이벤트 시간에 의해 데이터가 정렬되어서 조건절(Predicate) 푸쉬다운에 의한 최적화를 기대할 수 있다.
2.3 Presto에 의한 데이터 집계
이제 마지막으로 Presto를 설치한다.
Presto는 서버/클라이언트 형의 시스템이므로 Presto서버가 필요하지만
Hive 메타스토어 서비스로 대체할 수 있다.
먼저 Presto 설치를 진행한다.
아래 블로거님 글을 따라했습니다.
Java와 Python 버전 확인
$ java -version
openjdk version "1.8.0_312"
OpenJDK Runtime Environment (build 1.8.0_312-b07)
OpenJDK 64-Bit Server VM (build 25.312-b07, mixed mode)
$ python -V
Python 3.6.8
tar파일 다운로드
$ wget https://s3.us-east-2.amazonaws.com/starburstdata/presto-admin/2.6/prestoadmin-2.6-offline-el7.tar.gz
$ wget https://s3.us-east-2.amazonaws.com/starburstdata/presto/starburst/302e/302-e.11/presto-server-rpm-302-e.11.x86_64.rpm
$ wget https://s3.us-east-2.amazonaws.com/starburstdata/presto/starburst/302e/302-e.11/presto-cli-302-e.11-executable.jar
$ wget https://s3.us-east-2.amazonaws.com/starburstdata/presto/starburst/302e/302-e.11/presto-jdbc-302-e.11.jar
$ tar -xvf prestoadmin-2.6-offline-el7.tar.gz
$ cd prestoadmin/prestoadmin을 설치한다.
$ ./install-prestoadmin.sh
